 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework
Nov 09, 2024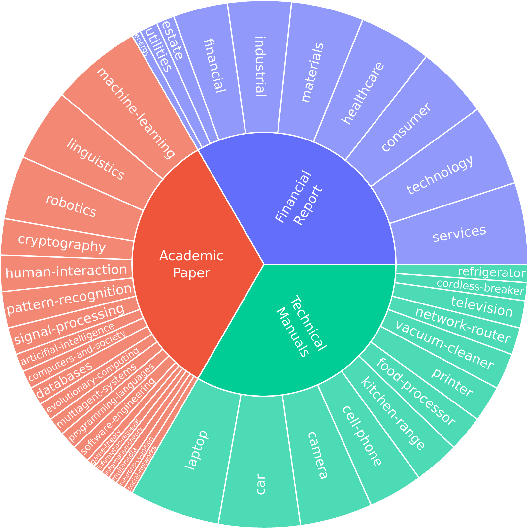
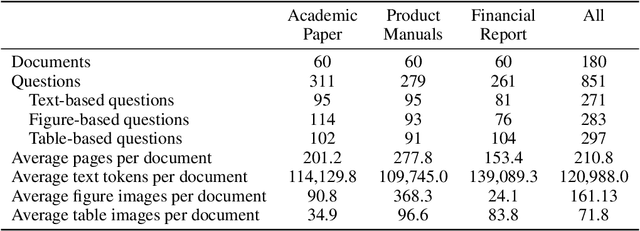
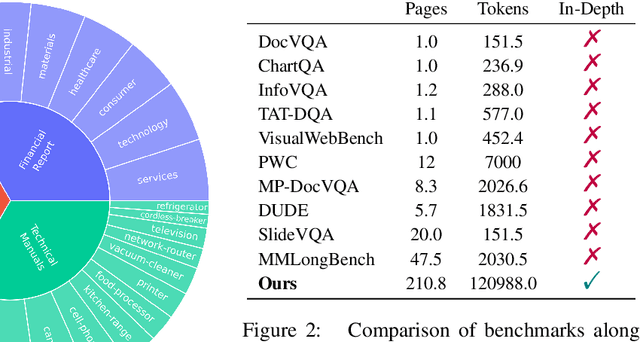
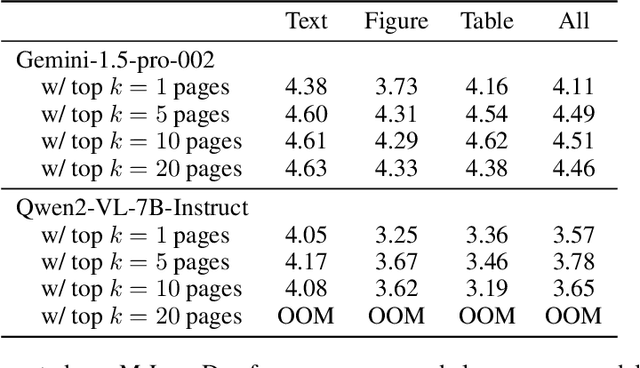
The ability to understand and answer questions over documents can be useful in many business and practical applications. However, documents often contain lengthy and diverse multimodal contents such as texts, figures, and tables, which are very time-consuming for humans to read thoroughly. Hence, there is an urgent need to develop effective and automated methods to aid humans in this task. In this work, we introduce M-LongDoc, a benchmark of 851 samples, and an automated framework to evaluate the performance of large multimodal models. We further propose a retrieval-aware tuning approach for efficient and effective multimodal document reading. Compared to existing works, our benchmark consists of more recent and lengthy documents with hundreds of pages, while also requiring open-ended solutions and not just extractive answers. To our knowledge, our training framework is the first to directly address the retrieval setting for multimodal long documents. To enable tuning open-source models, we construct a training corpus in a fully automatic manner for the question-answering task over such documents. Experiments show that our tuning approach achieves a relative improvement of 4.6% for the correctness of model responses, compared to the baseline open-source models. Our data, code, and models are available at https://multimodal-documents.github.io.
Reasoning Robustness of LLMs to Adversarial Typographical Errors
Nov 08, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning using Chain-of-Thought (CoT) prompting. However, CoT can be biased by users' instruction. In this work, we study the reasoning robustness of LLMs to typographical errors, which can naturally occur in users' queries. We design an Adversarial Typo Attack ($\texttt{ATA}$) algorithm that iteratively samples typos for words that are important to the query and selects the edit that is most likely to succeed in attacking. It shows that LLMs are sensitive to minimal adversarial typographical changes. Notably, with 1 character edit, Mistral-7B-Instruct's accuracy drops from 43.7% to 38.6% on GSM8K, while with 8 character edits the performance further drops to 19.2%. To extend our evaluation to larger and closed-source LLMs, we develop the $\texttt{R$^2$ATA}$ benchmark, which assesses models' $\underline{R}$easoning $\underline{R}$obustness to $\underline{\texttt{ATA}}$. It includes adversarial typographical questions derived from three widely used reasoning datasets-GSM8K, BBH, and MMLU-by applying $\texttt{ATA}$ to open-source LLMs. $\texttt{R$^2$ATA}$ demonstrates remarkable transferability and causes notable performance drops across multiple super large and closed-source LLMs.
SeaLLMs -- Large Language Models for Southeast Asia
Dec 01, 2023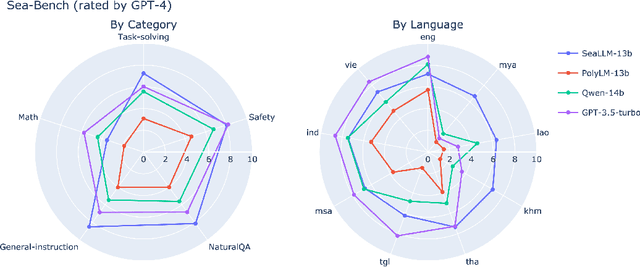
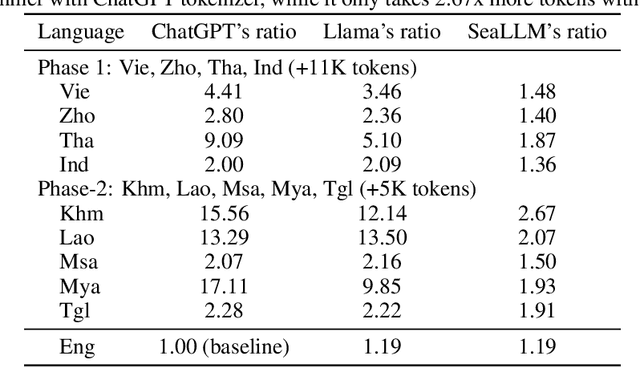
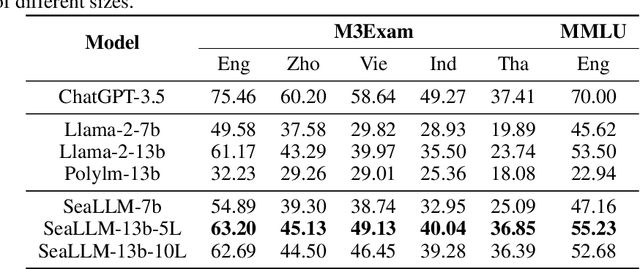
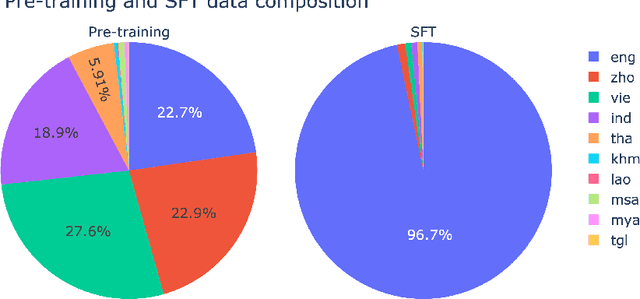
Despite the remarkable achievements of large language models (LLMs) in various tasks, there remains a linguistic bias that favors high-resource languages, such as English, often at the expense of low-resource and regional languages. To address this imbalance, we introduce SeaLLMs, an innovative series of language models that specifically focuses on Southeast Asian (SEA) languages. SeaLLMs are built upon the Llama-2 model and further advanced through continued pre-training with an extended vocabulary, specialized instruction and alignment tuning to better capture the intricacies of regional languages. This allows them to respect and reflect local cultural norms, customs, stylistic preferences, and legal considerations. Our comprehensive evaluation demonstrates that SeaLLM-13b models exhibit superior performance across a wide spectrum of linguistic tasks and assistant-style instruction-following capabilities relative to comparable open-source models. Moreover, they outperform ChatGPT-3.5 in non-Latin languages, such as Thai, Khmer, Lao, and Burmese, by large margins while remaining lightweight and cost-effective to operate.
Exploring the Potential of Large Language Models in Computational Argumentation
Nov 15, 2023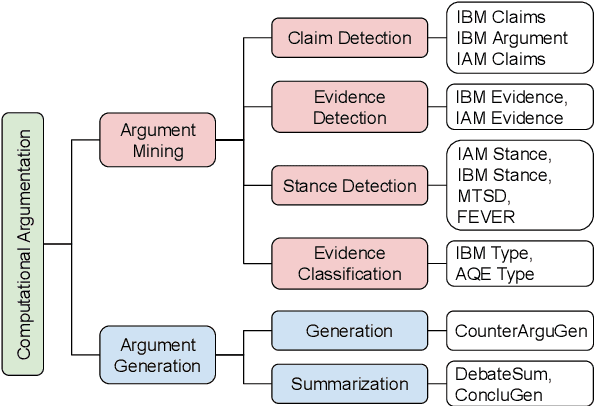
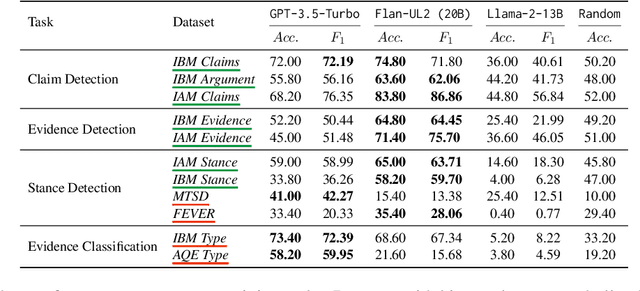
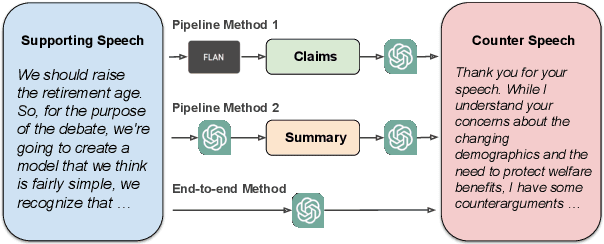
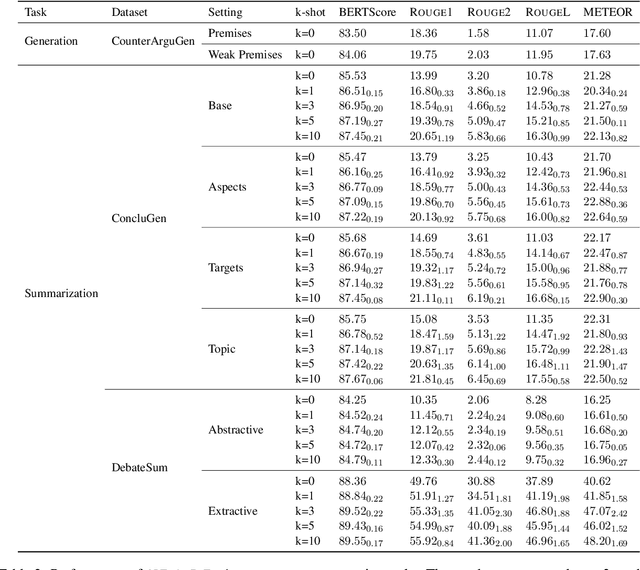
Computational argumentation has become an essential tool in various fields, including artificial intelligence, law, and public policy. It is an emerging research field in natural language processing (NLP) that attracts increasing attention. Research on computational argumentation mainly involves two types of tasks: argument mining and argument generation. As large language models (LLMs) have demonstrated strong abilities in understanding context and generating natural language, it is worthwhile to evaluate the performance of LLMs on various computational argumentation tasks. This work aims to embark on an assessment of LLMs, such as ChatGPT, Flan models and LLaMA2 models, under zero-shot and few-shot settings within the realm of computational argumentation. We organize existing tasks into 6 main classes and standardise the format of 14 open-sourced datasets. In addition, we present a new benchmark dataset on counter speech generation, that aims to holistically evaluate the end-to-end performance of LLMs on argument mining and argument generation. Extensive experiments show that LLMs exhibit commendable performance across most of these datasets, demonstrating their capabilities in the field of argumentation. We also highlight the limitations in evaluating computational argumentation and provide suggestions for future research directions in this field.
Semantic-Aware Contrastive Sentence Representation Learning with Large Language Models
Oct 17, 2023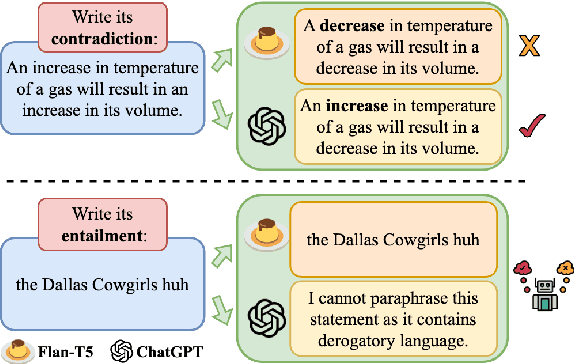
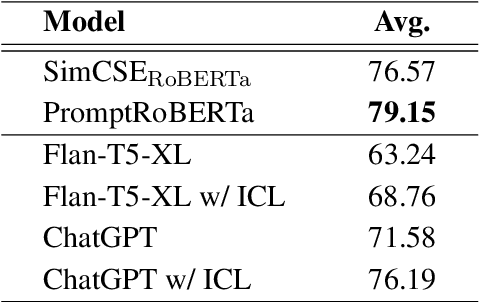
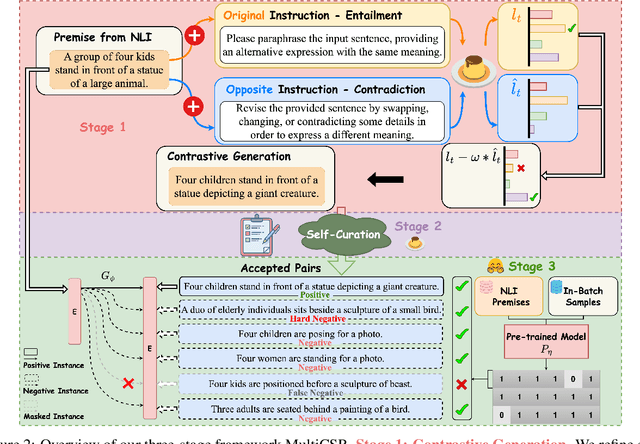

Contrastive learning has been proven to be effective in learning better sentence representations. However, to train a contrastive learning model, large numbers of labeled sentences are required to construct positive and negative pairs explicitly, such as those in natural language inference (NLI) datasets. Unfortunately, acquiring sufficient high-quality labeled data can be both time-consuming and resource-intensive, leading researchers to focus on developing methods for learning unsupervised sentence representations. As there is no clear relationship between these unstructured randomly-sampled sentences, building positive and negative pairs over them is tricky and problematic. To tackle these challenges, in this paper, we propose SemCSR, a semantic-aware contrastive sentence representation framework. By leveraging the generation and evaluation capabilities of large language models (LLMs), we can automatically construct a high-quality NLI-style corpus without any human annotation, and further incorporate the generated sentence pairs into learning a contrastive sentence representation model. Extensive experiments and comprehensive analyses demonstrate the effectiveness of our proposed framework for learning a better sentence representation with LLMs.
AQE: Argument Quadruplet Extraction via a Quad-Tagging Augmented Generative Approach
May 31, 2023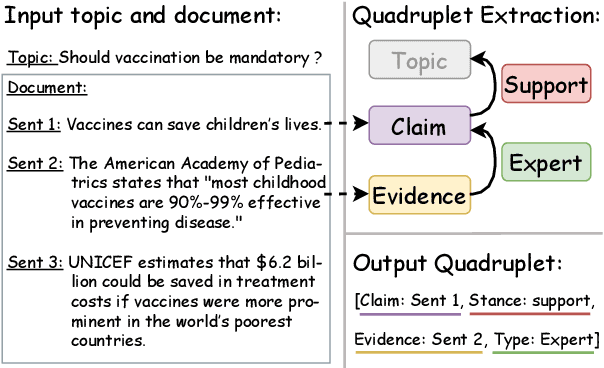
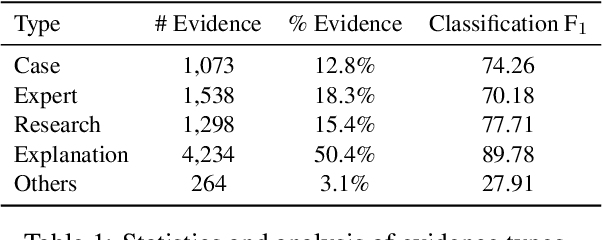
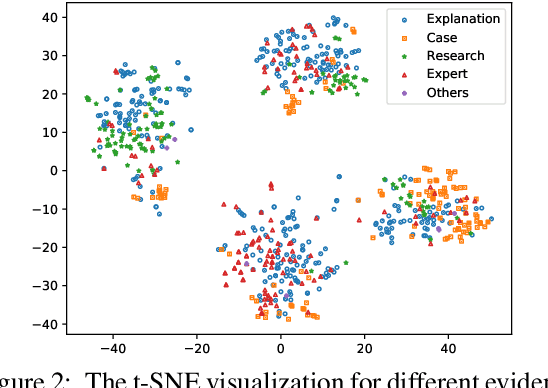
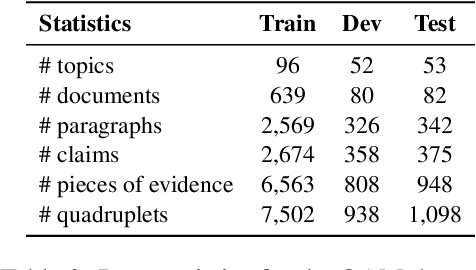
Argument mining involves multiple sub-tasks that automatically identify argumentative elements, such as claim detection, evidence extraction, stance classification, etc. However, each subtask alone is insufficient for a thorough understanding of the argumentative structure and reasoning process. To learn a complete view of an argument essay and capture the interdependence among argumentative components, we need to know what opinions people hold (i.e., claims), why those opinions are valid (i.e., supporting evidence), which source the evidence comes from (i.e., evidence type), and how those claims react to the debating topic (i.e., stance). In this work, we for the first time propose a challenging argument quadruplet extraction task (AQE), which can provide an all-in-one extraction of four argumentative components, i.e., claims, evidence, evidence types, and stances. To support this task, we construct a large-scale and challenging dataset. However, there is no existing method that can solve the argument quadruplet extraction. To fill this gap, we propose a novel quad-tagging augmented generative approach, which leverages a quadruplet tagging module to augment the training of the generative framework. The experimental results on our dataset demonstrate the empirical superiority of our proposed approach over several strong baselines.
Is GPT-4 a Good Data Analyst?
May 24, 2023



As large language models (LLMs) have demonstrated their powerful capabilities in plenty of domains and tasks, including context understanding, code generation, language generation, data storytelling, etc., many data analysts may raise concerns if their jobs will be replaced by AI. This controversial topic has drawn a lot of attention in public. However, we are still at a stage of divergent opinions without any definitive conclusion. Motivated by this, we raise the research question of "is GPT-4 a good data analyst?" in this work and aim to answer it by conducting head-to-head comparative studies. In detail, we regard GPT-4 as a data analyst to perform end-to-end data analysis with databases from a wide range of domains. We propose a framework to tackle the problems by carefully designing the prompts for GPT-4 to conduct experiments. We also design several task-specific evaluation metrics to systematically compare the performance between several professional human data analysts and GPT-4. Experimental results show that GPT-4 can achieve comparable performance to humans. We also provide in-depth discussions about our results to shed light on further studies before we reach the conclusion that GPT-4 can replace data analysts.
Unlocking Temporal Question Answering for Large Language Models Using Code Execution
May 24, 2023Large language models (LLMs) have made significant progress in natural language processing (NLP), and are utilized extensively in various applications. Recent works, such as chain-of-thought (CoT), have shown that intermediate reasoning steps can improve the performance of LLMs for complex reasoning tasks, such as math problems and symbolic question-answering tasks. However, we notice the challenge that LLMs face when it comes to temporal reasoning. Our preliminary experiments show that generating intermediate reasoning steps does not always boost the performance of complex temporal question-answering tasks. Therefore, we propose a novel framework that combines the extraction capability of LLMs and the logical reasoning capability of a Python solver to tackle this issue. Extensive experiments and analysis demonstrate the effectiveness of our framework in handling intricate time-bound reasoning tasks.
Are Large Language Models Good Evaluators for Abstractive Summarization?
May 22, 2023Human evaluations are often required for abstractive summary evaluations to give fairer judgments. However, they are often time-consuming, costly, inconsistent, and non-reproducible. To overcome these challenges, we explore the potential of using an out-of-the-box LLM (i.e. "gpt-3.5-turbo") for summarization evaluation without manually selecting demonstrations or complex prompt tuning. We compare different evaluation methods, including 2 methods for Likert-scale scoring and 1 method for head-to-head comparisons, to investigate the performance of the LLM as a zero-shot evaluator. We further propose a meta-correlation metric to measure the stability of the LLM's evaluation capability. With extensive experiments, we show that certain prompt formats can produce better results than others. We also bring attention to the LLM's deteriorating evaluation capability with the rising qualities of summaries. In addition, we find that the LLM's evaluation capability also depends on the evaluated dimensions. We discuss the pros and cons of each method, make recommendations, and suggest some future directions for improvement.
Enhancing Few-shot NER with Prompt Ordering based Data Augmentation
May 19, 2023



Recently, data augmentation (DA) methods have been proven to be effective for pre-trained language models (PLMs) in low-resource settings, including few-shot named entity recognition (NER). However, conventional NER DA methods are mostly aimed at sequence labeling models, i.e., token-level classification, and few are compatible with unified autoregressive generation frameworks, which can handle a wider range of NER tasks, such as nested NER. Furthermore, these generation frameworks have a strong assumption that the entities will appear in the target sequence with the same left-to-right order as the source sequence. In this paper, we claim that there is no need to keep this strict order, and more diversified but reasonable target entity sequences can be provided during the training stage as a novel DA method. Nevertheless, a naive mixture of augmented data can confuse the model since one source sequence will then be paired with different target sequences. Therefore, we propose a simple but effective Prompt Ordering based Data Augmentation (PODA) method to improve the training of unified autoregressive generation frameworks under few-shot NER scenarios. Experimental results on three public NER datasets and further analyses demonstrate the effectiveness of our approach.