 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlien Science: Sampling Coherent but Cognitively Unavailable Research Directions from Idea Atoms
Mar 01, 2026Large language models are adept at synthesizing and recombining familiar material, yet they often fail at a specific kind of creativity that matters most in research: producing ideas that are both coherent and non-obvious to the current community. We formalize this gap through cognitive availability, the likelihood that a research direction would be naturally proposed by a typical researcher given what they have worked on. We introduce a pipeline that (i) decomposes papers into granular conceptual units, (ii) clusters recurring units into a shared vocabulary of idea atoms, and (iii) learns two complementary models: a coherence model that scores whether a set of atoms constitutes a viable direction, and an availability model that scores how likely that direction is to be generated by researchers drawn from the community. We then sample "alien" directions that score high on coherence but low on availability. On a corpus of $\sim$7,500 recent LLM papers from NeurIPS, ICLR and ICML, we validate that (a) conceptual units preserve paper content under reconstruction, (b) idea atoms generalize across papers rather than memorizing paper-specific phrasing, and (c) the Alien sampler produces research directions that are more diverse than LLM baselines while maintaining coherence.
Escaping the Cognitive Well: Efficient Competition Math with Off-the-Shelf Models
Feb 18, 2026In the past year, custom and unreleased math reasoning models reached gold medal performance on the International Mathematical Olympiad (IMO). Similar performance was then reported using large-scale inference on publicly available models but at prohibitive costs (e.g., 3000 USD per problem). In this work, we present an inference pipeline that attains best-in-class performance on IMO-style math problems at an average inference cost orders of magnitude below competing methods while using only general-purpose off-the-shelf models. Our method relies on insights about grader failure in solver-grader pipelines, which we call the Cognitive Well (iterative refinement converging to a wrong solution that the solver as well as the pipeline's internal grader consider to be basically correct). Our pipeline addresses these failure modes through conjecture extraction, wherein candidate lemmas are isolated from generated solutions and independently verified alongside their negations in a fresh environment (context detachment). On IMO-ProofBench Advanced (PB-Adv), our pipeline achieves 67.1 percent performance using Gemini 3.0 Pro with an average cost per question of approximately 31 USD. At the time of evaluation, this represented the state-of-the-art on PB-Adv among both public and unreleased models, and more than doubles the success rate of the next best publicly accessible pipeline, all at a fraction of the cost.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Sep 17, 2025Where do learning signals come from when there is no ground truth in post-training? We propose turning exploration into supervision through Compute as Teacher (CaT), which converts the model's own exploration at inference-time into reference-free supervision by synthesizing a single reference from a group of parallel rollouts and then optimizing toward it. Concretely, the current policy produces a group of rollouts; a frozen anchor (the initial policy) reconciles omissions and contradictions to estimate a reference, turning extra inference-time compute into a teacher signal. We turn this into rewards in two regimes: (i) verifiable tasks use programmatic equivalence on final answers; (ii) non-verifiable tasks use self-proposed rubrics-binary, auditable criteria scored by an independent LLM judge, with reward given by the fraction satisfied. Unlike selection methods (best-of-N, majority, perplexity, or judge scores), synthesis may disagree with the majority and be correct even when all rollouts are wrong; performance scales with the number of rollouts. As a test-time procedure, CaT improves Gemma 3 4B, Qwen 3 4B, and Llama 3.1 8B (up to +27% on MATH-500; +12% on HealthBench). With reinforcement learning (CaT-RL), we obtain further gains (up to +33% and +30%), with the trained policy surpassing the initial teacher signal.
Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors
Sep 16, 2025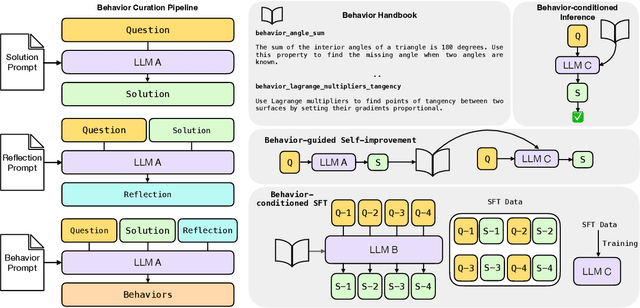



Large language models (LLMs) now solve multi-step problems by emitting extended chains of thought. During the process, they often re-derive the same intermediate steps across problems, inflating token usage and latency. This saturation of the context window leaves less capacity for exploration. We study a simple mechanism that converts recurring reasoning fragments into concise, reusable "behaviors" (name + instruction) via the model's own metacognitive analysis of prior traces. These behaviors are stored in a "behavior handbook" which supplies them to the model in-context at inference or distills them into parameters via supervised fine-tuning. This approach achieves improved test-time reasoning across three different settings - 1) Behavior-conditioned inference: Providing the LLM relevant behaviors in-context during reasoning reduces number of reasoning tokens by up to 46% while matching or improving baseline accuracy; 2) Behavior-guided self-improvement: Without any parameter updates, the model improves its own future reasoning by leveraging behaviors from its own past problem solving attempts. This yields up to 10% higher accuracy than a naive critique-and-revise baseline; and 3) Behavior-conditioned SFT: SFT on behavior-conditioned reasoning traces is more effective at converting non-reasoning models into reasoning models as compared to vanilla SFT. Together, these results indicate that turning slow derivations into fast procedural hints enables LLMs to remember how to reason, not just what to conclude.
Auto-Bench: An Automated Benchmark for Scientific Discovery in LLMs
Feb 21, 2025Given the remarkable performance of Large Language Models (LLMs), an important question arises: Can LLMs conduct human-like scientific research and discover new knowledge, and act as an AI scientist? Scientific discovery is an iterative process that demands efficient knowledge updating and encoding. It involves understanding the environment, identifying new hypotheses, and reasoning about actions; however, no standardized benchmark specifically designed for scientific discovery exists for LLM agents. In response to these limitations, we introduce a novel benchmark, \textit{Auto-Bench}, that encompasses necessary aspects to evaluate LLMs for scientific discovery in both natural and social sciences. Our benchmark is based on the principles of causal graph discovery. It challenges models to uncover hidden structures and make optimal decisions, which includes generating valid justifications. By engaging interactively with an oracle, the models iteratively refine their understanding of underlying interactions, the chemistry and social interactions, through strategic interventions. We evaluate state-of-the-art LLMs, including GPT-4, Gemini, Qwen, Claude, and Llama, and observe a significant performance drop as the problem complexity increases, which suggests an important gap between machine and human intelligence that future development of LLMs need to take into consideration.
Generalizing from SIMPLE to HARD Visual Reasoning: Can We Mitigate Modality Imbalance in VLMs?
Jan 05, 2025



While Vision Language Models (VLMs) are impressive in tasks such as visual question answering (VQA) and image captioning, their ability to apply multi-step reasoning to images has lagged, giving rise to perceptions of modality imbalance or brittleness. Towards systematic study of such issues, we introduce a synthetic framework for assessing the ability of VLMs to perform algorithmic visual reasoning (AVR), comprising three tasks: Table Readout, Grid Navigation, and Visual Analogy. Each has two levels of difficulty, SIMPLE and HARD, and even the SIMPLE versions are difficult for frontier VLMs. We seek strategies for training on the SIMPLE version of the tasks that improve performance on the corresponding HARD task, i.e., S2H generalization. This synthetic framework, where each task also has a text-only version, allows a quantification of the modality imbalance, and how it is impacted by training strategy. Ablations highlight the importance of explicit image-to-text conversion in promoting S2H generalization when using auto-regressive training. We also report results of mechanistic study of this phenomenon, including a measure of gradient alignment that seems to identify training strategies that promote better S2H generalization.
Data for Mathematical Copilots: Better Ways of Presenting Proofs for Machine Learning
Dec 19, 2024

The suite of datasets commonly used to train and evaluate the mathematical capabilities of AI-based mathematical copilots (primarily large language models) exhibit several shortcomings. These limitations include a restricted scope of mathematical complexity, typically not exceeding lower undergraduate-level mathematics, binary rating protocols and other issues, which makes comprehensive proof-based evaluation suites difficult. We systematically explore these limitations and contend that enhancing the capabilities of large language models, or any forthcoming advancements in AI-based mathematical assistants (copilots or "thought partners"), necessitates a paradigm shift in the design of mathematical datasets and the evaluation criteria of mathematical ability: It is necessary to move away from result-based datasets (theorem statement to theorem proof) and convert the rich facets of mathematical research practice to data LLMs can train on. Examples of these are mathematical workflows (sequences of atomic, potentially subfield-dependent tasks that are often performed when creating new mathematics), which are an important part of the proof-discovery process. Additionally, we advocate for mathematical dataset developers to consider the concept of "motivated proof", introduced by G. P\'olya in 1949, which can serve as a blueprint for datasets that offer a better proof learning signal, alleviating some of the mentioned limitations. Lastly, we introduce math datasheets for datasets, extending the general, dataset-agnostic variants of datasheets: We provide a questionnaire designed specifically for math datasets that we urge dataset creators to include with their datasets. This will make creators aware of potential limitations of their datasets while at the same time making it easy for readers to assess it from the point of view of training and evaluating mathematical copilots.
A Systematic Examination of Preference Learning through the Lens of Instruction-Following
Dec 18, 2024Preference learning is a widely adopted post-training technique that aligns large language models (LLMs) to human preferences and improves specific downstream task capabilities. In this work we systematically investigate how specific attributes of preference datasets affect the alignment and downstream performance of LLMs in instruction-following tasks. We use a novel synthetic data generation pipeline to generate 48,000 unique instruction-following prompts with combinations of 23 verifiable constraints that enable fine-grained and automated quality assessments of model responses. With our synthetic prompts, we use two preference dataset curation methods - rejection sampling (RS) and Monte Carlo Tree Search (MCTS) - to obtain pairs of (chosen, rejected) responses. Then, we perform experiments investigating the effects of (1) the presence of shared prefixes between the chosen and rejected responses, (2) the contrast and quality of the chosen, rejected responses and (3) the complexity of the training prompts. Our experiments reveal that shared prefixes in preference pairs, as generated by MCTS, provide marginal but consistent improvements and greater stability across challenging training configurations. High-contrast preference pairs generally outperform low-contrast pairs; however, combining both often yields the best performance by balancing diversity and learning efficiency. Additionally, training on prompts of moderate difficulty leads to better generalization across tasks, even for more complex evaluation scenarios, compared to overly challenging prompts. Our findings provide actionable insights into optimizing preference data curation for instruction-following tasks, offering a scalable and effective framework for enhancing LLM training and alignment.
Reasoning Robustness of LLMs to Adversarial Typographical Errors
Nov 08, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning using Chain-of-Thought (CoT) prompting. However, CoT can be biased by users' instruction. In this work, we study the reasoning robustness of LLMs to typographical errors, which can naturally occur in users' queries. We design an Adversarial Typo Attack ($\texttt{ATA}$) algorithm that iteratively samples typos for words that are important to the query and selects the edit that is most likely to succeed in attacking. It shows that LLMs are sensitive to minimal adversarial typographical changes. Notably, with 1 character edit, Mistral-7B-Instruct's accuracy drops from 43.7% to 38.6% on GSM8K, while with 8 character edits the performance further drops to 19.2%. To extend our evaluation to larger and closed-source LLMs, we develop the $\texttt{R$^2$ATA}$ benchmark, which assesses models' $\underline{R}$easoning $\underline{R}$obustness to $\underline{\texttt{ATA}}$. It includes adversarial typographical questions derived from three widely used reasoning datasets-GSM8K, BBH, and MMLU-by applying $\texttt{ATA}$ to open-source LLMs. $\texttt{R$^2$ATA}$ demonstrates remarkable transferability and causes notable performance drops across multiple super large and closed-source LLMs.