 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking On-Policy Self-Distillation for Thinking Models
Jul 06, 2026Self-distillation is a promising recipe for self-improvement in language models. In this setting, a model can serve as its own teacher when given privileged information, such as a solution to a math problem. This seems especially appealing for thinking models, which can use test-time reasoning to absorb the privileged information. Surprisingly, we show that privileged self-distillation degrades thinking models on long reasoning traces: across five Qwen3 and OLMo thinking models evaluated on AIME24, AIME25, and HMMT25, privileged-context distillation causes a relative drop of up to 17% in avg@16 accuracy. The degradation scales with the amount of privileged context withheld from the student and is most pronounced at long rollout budgets, where thinking models otherwise obtain their largest gains. This failure mode is not specific to self-distillation: on-policy distillation (OPD) improves thinking models, but privileged OPD reverses these gains. Our diagnostics link this failure mode to how privileged teacher context reshapes learning at high-entropy forking positions, where multiple continuations remain plausible and may lead to different reasoning paths. Privileged context lowers fork rates in thinking-model rollouts but not in instruction-model rollouts. This leads to an interesting dichotomy, where privileged context can help instruction-tuned models but hurts stronger thinking models. The effect is visible when the student begins a self-correction branch, where privileged OPD penalizes sampled reconsideration tokens that vanilla OPD supports. Thinking models trained with a privileged teacher produce fewer verification, backtracking, and hedging markers, even after length normalization. These findings indicate that self-distillation for strong thinking models requires attention to token-level signal, especially around correction and reasoning steps.
Do Thinking Tokens Help with Safety?
Jun 23, 2026Today's reasoning models use thinking tokens to attain stronger performance on benchmarks than their instruction-tuned counterparts. It is also generally believed that this more "deliberative" mode should improve alignment and safety, by providing the model a safe space to consider whether its planned answer to a request violates its safety principles. We present evidence that this intuition is not always correct. Across frontier open-weight reasoning models spanning GPT-OSS, Qwen, Olmo, and Phi families, we find that the eventual refusal/compliance outcome is already strongly predictable via a trained head on the first token's hidden representation ($0.84$-$0.95$ AUROC and $\sim88\%$ balanced accuracy for predicting refusal/compliance) before any visible thinking. The thinking process turns out to be more akin to prefix completion than to deliberative revision, with the final outcome rarely changing after the first $\sim20\%$ of thinking, despite giving the appearance of deliberation at the text level ($\sim74\%$ of text-level deliberations occur when the response distribution is already locked to one refusal/compliance side). We also find that existing inference-time and training-based safety interventions, despite being motivated by the goal of inducing deliberation, largely shift model behavior toward over-refusal while suppressing already-scarce deliberation signals. Our results suggest that safety behavior in current reasoning models is much less deliberative than commonly assumed, and highlight the need for methods that induce real safety deliberation.
Goedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Jun 04, 2026We introduce Goedel-Architect, an agentic framework for formal theorem proving in Lean 4 centered on blueprint generation and refinement. A blueprint is a dependency graph of definitions and lemmas that builds up to the main theorem. First, Goedel-Architect generates a blueprint of formally stated definitions and lemmas, along with declared dependencies. This blueprint is optionally guided by a natural language proof. Then, a tool-equipped Lean prover component closes each open lemma node in parallel using relevant dependencies. Failed lemmas in turn drive refinement of the global blueprint. This strategy contrasts with other mainstream approaches which use recursive lemma decomposition, and can inefficiently loop on dead-end strategies. Using the open-weight DeepSeek-V4-Flash (284B-A13B) as the backbone, Goedel-Architect attains 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench. With an optional natural-language proof seeding the initial blueprint on the harder problems, we additionally close the remaining two MiniF2F-test problems (reaching 100%), lift PutnamBench to 88.8% (597/672), and solve 4/6 on IMO 2025, 11/12 on Putnam 2025, and 3/6 on USAMO 2026. This represents state-of-the-art performance for an open-source pipeline at a price point up to 500x less than comparable open-source pipelines.
When Errors Can Be Beneficial: A Categorization of Imperfect Rewards for Policy Gradient
Apr 28, 2026Training language models via reinforcement learning often relies on imperfect proxy rewards, since ground truth rewards that precisely define the intended behavior are rarely available. Standard metrics for assessing the quality of proxy rewards, such as ranking accuracy, treat incorrect rewards as strictly harmful. In this work, however, we highlight that not all deviations from the ground truth are equal. By theoretically analyzing which outputs attract probability during policy gradient optimization, we categorize reward errors according to their effect on the increase in ground truth reward. The analysis establishes that reward errors, though conventionally viewed as harmful, can also be benign or even beneficial by preventing the policy from stalling around outputs with mediocre ground truth reward. We then present two practical implications of our theory. First, for reinforcement learning from human feedback (RLHF), we develop reward model evaluation metrics that account for the harmfulness of reward errors. Compared to standard ranking accuracy, these metrics typically correlate better with the performance of a language model after RLHF, yet gaps remain in robustly evaluating reward models. Second, we provide insights for reward design in settings with verifiable rewards. A key theme underlying our results is that the effectiveness of a proxy reward function depends heavily on its interaction with the initial policy and learning algorithm.
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Apr 13, 2026Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.
Escaping the Cognitive Well: Efficient Competition Math with Off-the-Shelf Models
Feb 18, 2026In the past year, custom and unreleased math reasoning models reached gold medal performance on the International Mathematical Olympiad (IMO). Similar performance was then reported using large-scale inference on publicly available models but at prohibitive costs (e.g., 3000 USD per problem). In this work, we present an inference pipeline that attains best-in-class performance on IMO-style math problems at an average inference cost orders of magnitude below competing methods while using only general-purpose off-the-shelf models. Our method relies on insights about grader failure in solver-grader pipelines, which we call the Cognitive Well (iterative refinement converging to a wrong solution that the solver as well as the pipeline's internal grader consider to be basically correct). Our pipeline addresses these failure modes through conjecture extraction, wherein candidate lemmas are isolated from generated solutions and independently verified alongside their negations in a fresh environment (context detachment). On IMO-ProofBench Advanced (PB-Adv), our pipeline achieves 67.1 percent performance using Gemini 3.0 Pro with an average cost per question of approximately 31 USD. At the time of evaluation, this represented the state-of-the-art on PB-Adv among both public and unreleased models, and more than doubles the success rate of the next best publicly accessible pipeline, all at a fraction of the cost.
AlgoVeri: An Aligned Benchmark for Verified Code Generation on Classical Algorithms
Feb 10, 2026Vericoding refers to the generation of formally verified code from rigorous specifications. Recent AI models show promise in vericoding, but a unified methodology for cross-paradigm evaluation is lacking. Existing benchmarks test only individual languages/tools (e.g., Dafny, Verus, and Lean) and each covers very different tasks, so the performance numbers are not directly comparable. We address this gap with AlgoVeri, a benchmark that evaluates vericoding of $77$ classical algorithms in Dafny, Verus, and Lean. By enforcing identical functional contracts, AlgoVeri reveals critical capability gaps in verification systems. While frontier models achieve tractable success in Dafny ($40.3$% for Gemini-3 Flash), where high-level abstractions and SMT automation simplify the workflow, performance collapses under the systems-level memory constraints of Verus ($24.7$%) and the explicit proof construction required by Lean (7.8%). Beyond aggregate metrics, we uncover a sharp divergence in test-time compute dynamics: Gemini-3 effectively utilizes iterative repair to boost performance (e.g., tripling pass rates in Dafny), whereas GPT-OSS saturates early. Finally, our error analysis shows that language design affects the refinement trajectory: while Dafny allows models to focus on logical correctness, Verus and Lean trap models in persistent syntactic and semantic barriers. All data and evaluation code can be found at https://github.com/haoyuzhao123/algoveri.
Contextual Drag: How Errors in the Context Affect LLM Reasoning
Feb 04, 2026Central to many self-improvement pipelines for large language models (LLMs) is the assumption that models can improve by reflecting on past mistakes. We study a phenomenon termed contextual drag: the presence of failed attempts in the context biases subsequent generations toward structurally similar errors. Across evaluations of 11 proprietary and open-weight models on 8 reasoning tasks, contextual drag induces 10-20% performance drops, and iterative self-refinement in models with severe contextual drag can collapse into self-deterioration. Structural analysis using tree edit distance reveals that subsequent reasoning trajectories inherit structurally similar error patterns from the context. We demonstrate that neither external feedback nor successful self-verification suffices to eliminate this effect. While mitigation strategies such as fallback-behavior fine-tuning and context denoising yield partial improvements, they fail to fully restore baseline performance, positioning contextual drag as a persistent failure mode in current reasoning architectures.
Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors
Sep 16, 2025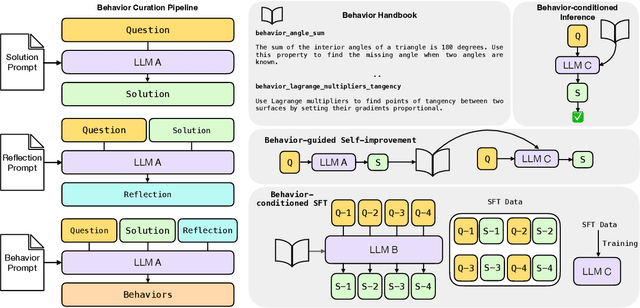



Large language models (LLMs) now solve multi-step problems by emitting extended chains of thought. During the process, they often re-derive the same intermediate steps across problems, inflating token usage and latency. This saturation of the context window leaves less capacity for exploration. We study a simple mechanism that converts recurring reasoning fragments into concise, reusable "behaviors" (name + instruction) via the model's own metacognitive analysis of prior traces. These behaviors are stored in a "behavior handbook" which supplies them to the model in-context at inference or distills them into parameters via supervised fine-tuning. This approach achieves improved test-time reasoning across three different settings - 1) Behavior-conditioned inference: Providing the LLM relevant behaviors in-context during reasoning reduces number of reasoning tokens by up to 46% while matching or improving baseline accuracy; 2) Behavior-guided self-improvement: Without any parameter updates, the model improves its own future reasoning by leveraging behaviors from its own past problem solving attempts. This yields up to 10% higher accuracy than a naive critique-and-revise baseline; and 3) Behavior-conditioned SFT: SFT on behavior-conditioned reasoning traces is more effective at converting non-reasoning models into reasoning models as compared to vanilla SFT. Together, these results indicate that turning slow derivations into fast procedural hints enables LLMs to remember how to reason, not just what to conclude.
Why is Your Language Model a Poor Implicit Reward Model?
Jul 10, 2025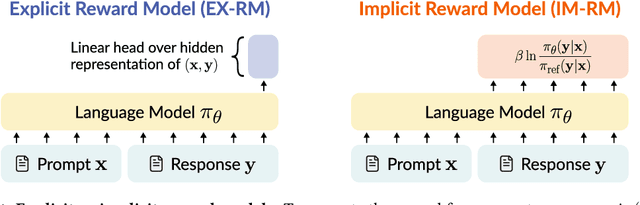
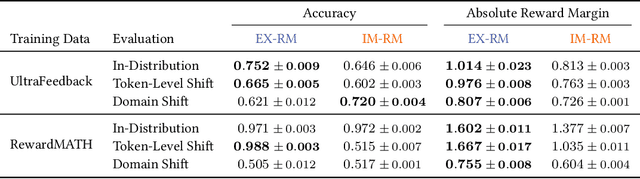
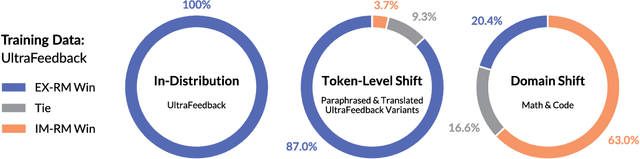
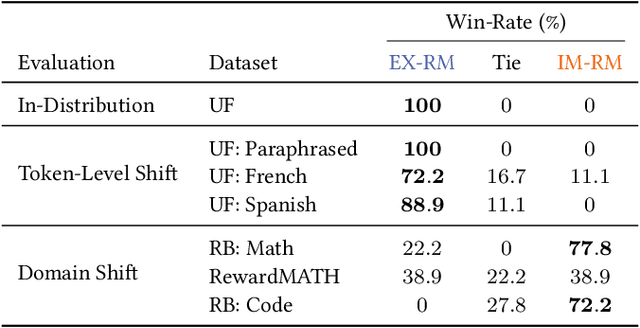
Reward models are key to language model post-training and inference pipelines. Conveniently, recent work showed that every language model defines an implicit reward model (IM-RM), without requiring any architectural changes. However, such IM-RMs tend to generalize worse, especially out-of-distribution, compared to explicit reward models (EX-RMs) that apply a dedicated linear head over the hidden representations of a language model. The existence of a generalization gap is puzzling, as EX-RMs and IM-RMs are nearly identical. They can be trained using the same data, loss function, and language model, and differ only in how the reward is computed. Towards a fundamental understanding of the implicit biases underlying different reward model types, we investigate the root cause of this gap. Our main finding, backed by theory and experiments, is that IM-RMs rely more heavily on superficial token-level cues. Consequently, they often generalize worse than EX-RMs under token-level distribution shifts, as well as in-distribution. Furthermore, we provide evidence against alternative hypotheses for the generalization gap. Most notably, we challenge the intuitive claim that IM-RMs struggle in tasks where generation is harder than verification because they can operate both as a verifier and a generator. Taken together, our results highlight that seemingly minor design choices can substantially impact the generalization behavior of reward models.