 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvertrained Language Models Are Harder to Fine-Tune
Mar 24, 2025



Large language models are pre-trained on ever-growing token budgets under the assumption that better pre-training performance translates to improved downstream models. In this work, we challenge this assumption and show that extended pre-training can make models harder to fine-tune, leading to degraded final performance. We term this phenomenon catastrophic overtraining. For example, the instruction-tuned OLMo-1B model pre-trained on 3T tokens leads to over 2% worse performance on multiple standard LLM benchmarks than its 2.3T token counterpart. Through controlled experiments and theoretical analysis, we show that catastrophic overtraining arises from a systematic increase in the broad sensitivity of pre-trained parameters to modifications, including but not limited to fine-tuning. Our findings call for a critical reassessment of pre-training design that considers the downstream adaptability of the model.
Metadata Conditioning Accelerates Language Model Pre-training
Jan 03, 2025



The vast diversity of styles, domains, and quality levels present in language model pre-training corpora is essential in developing general model capabilities, but efficiently learning and deploying the correct behaviors exemplified in each of these heterogeneous data sources is challenging. To address this, we propose a new method, termed Metadata Conditioning then Cooldown (MeCo), to incorporate additional learning cues during pre-training. MeCo first provides metadata (e.g., URLs like en.wikipedia.org) alongside the text during training and later uses a cooldown phase with only the standard text, thereby enabling the model to function normally even without metadata. MeCo significantly accelerates pre-training across different model scales (600M to 8B parameters) and training sources (C4, RefinedWeb, and DCLM). For instance, a 1.6B language model trained with MeCo matches the downstream task performance of standard pre-training while using 33% less data. Additionally, MeCo enables us to steer language models by conditioning the inference prompt on either real or fabricated metadata that encodes the desired properties of the output: for example, prepending wikipedia.org to reduce harmful generations or factquizmaster.com (fabricated) to improve common knowledge task performance. We also demonstrate that MeCo is compatible with different types of metadata, such as model-generated topics. MeCo is remarkably simple, adds no computational overhead, and demonstrates promise in producing more capable and steerable language models.
Provable unlearning in topic modeling and downstream tasks
Nov 20, 2024Machine unlearning algorithms are increasingly important as legal concerns arise around the provenance of training data, but verifying the success of unlearning is often difficult. Provable guarantees for unlearning are often limited to supervised learning settings. In this paper, we provide the first theoretical guarantees for unlearning in the pre-training and fine-tuning paradigm by studying topic models, simple bag-of-words language models that can be adapted to solve downstream tasks like retrieval and classification. First, we design a provably effective unlearning algorithm for topic models that incurs a computational overhead independent of the size of the original dataset. Our analysis additionally quantifies the deletion capacity of the model -- i.e., the number of examples that can be unlearned without incurring a significant cost in model performance. Finally, we formally extend our analyses to account for adaptation to a given downstream task. In particular, we design an efficient algorithm to perform unlearning after fine-tuning the topic model via a linear head. Notably, we show that it is easier to unlearn pre-training data from models that have been fine-tuned to a particular task, and one can unlearn this data without modifying the base model.
Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws
Oct 15, 2024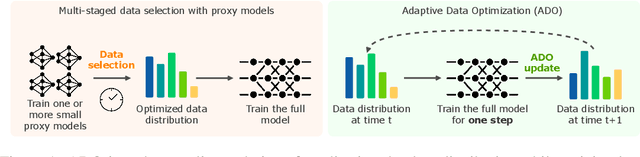
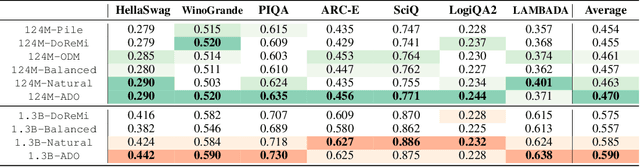
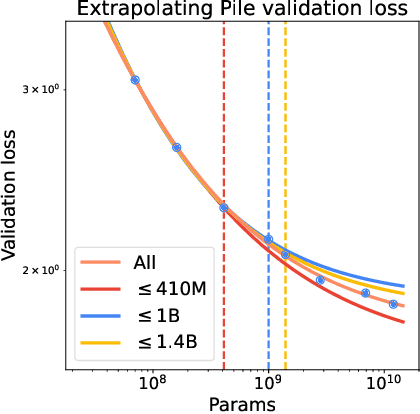
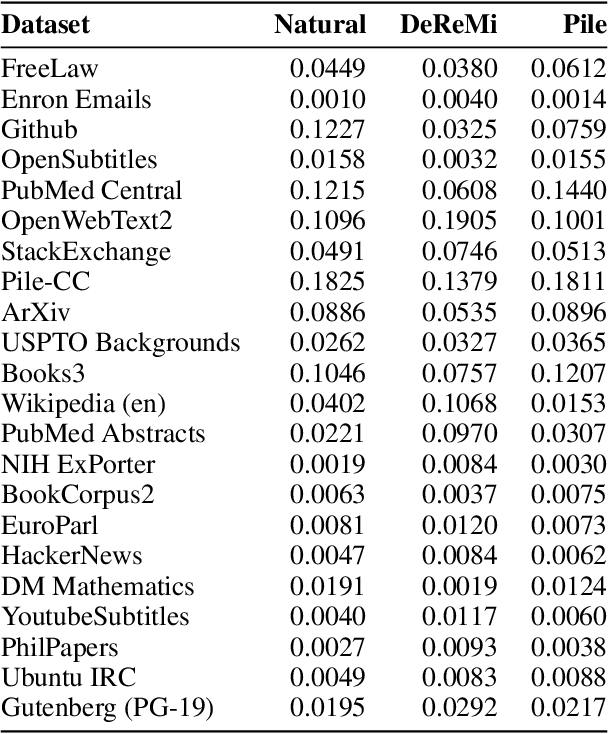
The composition of pretraining data is a key determinant of foundation models' performance, but there is no standard guideline for allocating a limited computational budget across different data sources. Most current approaches either rely on extensive experiments with smaller models or dynamic data adjustments that also require proxy models, both of which significantly increase the workflow complexity and computational overhead. In this paper, we introduce Adaptive Data Optimization (ADO), an algorithm that optimizes data distributions in an online fashion, concurrent with model training. Unlike existing techniques, ADO does not require external knowledge, proxy models, or modifications to the model update. Instead, ADO uses per-domain scaling laws to estimate the learning potential of each domain during training and adjusts the data mixture accordingly, making it more scalable and easier to integrate. Experiments demonstrate that ADO can achieve comparable or better performance than prior methods while maintaining computational efficiency across different computation scales, offering a practical solution for dynamically adjusting data distribution without sacrificing flexibility or increasing costs. Beyond its practical benefits, ADO also provides a new perspective on data collection strategies via scaling laws.
Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization
Oct 11, 2024Direct Preference Optimization (DPO) and its variants are increasingly used for aligning language models with human preferences. Although these methods are designed to teach a model to generate preferred responses more frequently relative to dispreferred responses, prior work has observed that the likelihood of preferred responses often decreases during training. The current work sheds light on the causes and implications of this counter-intuitive phenomenon, which we term likelihood displacement. We demonstrate that likelihood displacement can be catastrophic, shifting probability mass from preferred responses to responses with an opposite meaning. As a simple example, training a model to prefer $\texttt{No}$ over $\texttt{Never}$ can sharply increase the probability of $\texttt{Yes}$. Moreover, when aligning the model to refuse unsafe prompts, we show that such displacement can unintentionally lead to unalignment, by shifting probability mass from preferred refusal responses to harmful responses (e.g., reducing the refusal rate of Llama-3-8B-Instruct from 74.4% to 33.4%). We theoretically characterize that likelihood displacement is driven by preferences that induce similar embeddings, as measured by a centered hidden embedding similarity (CHES) score. Empirically, the CHES score enables identifying which training samples contribute most to likelihood displacement in a given dataset. Filtering out these samples effectively mitigated unintentional unalignment in our experiments. More broadly, our results highlight the importance of curating data with sufficiently distinct preferences, for which we believe the CHES score may prove valuable.
Progressive distillation induces an implicit curriculum
Oct 07, 2024Knowledge distillation leverages a teacher model to improve the training of a student model. A persistent challenge is that a better teacher does not always yield a better student, to which a common mitigation is to use additional supervision from several ``intermediate'' teachers. One empirically validated variant of this principle is progressive distillation, where the student learns from successive intermediate checkpoints of the teacher. Using sparse parity as a sandbox, we identify an implicit curriculum as one mechanism through which progressive distillation accelerates the student's learning. This curriculum is available only through the intermediate checkpoints but not the final converged one, and imparts both empirical acceleration and a provable sample complexity benefit to the student. We then extend our investigation to Transformers trained on probabilistic context-free grammars (PCFGs) and real-world pre-training datasets (Wikipedia and Books). Through probing the teacher model, we identify an analogous implicit curriculum where the model progressively learns features that capture longer context. Our theoretical and empirical findings on sparse parity, complemented by empirical observations on more complex tasks, highlight the benefit of progressive distillation via implicit curriculum across setups.
MUSE: Machine Unlearning Six-Way Evaluation for Language Models
Jul 08, 2024Language models (LMs) are trained on vast amounts of text data, which may include private and copyrighted content. Data owners may request the removal of their data from a trained model due to privacy or copyright concerns. However, exactly unlearning only these datapoints (i.e., retraining with the data removed) is intractable in modern-day models. This has led to the development of many approximate unlearning algorithms. The evaluation of the efficacy of these algorithms has traditionally been narrow in scope, failing to precisely quantify the success and practicality of the algorithm from the perspectives of both the model deployers and the data owners. We address this issue by proposing MUSE, a comprehensive machine unlearning evaluation benchmark that enumerates six diverse desirable properties for unlearned models: (1) no verbatim memorization, (2) no knowledge memorization, (3) no privacy leakage, (4) utility preservation on data not intended for removal, (5) scalability with respect to the size of removal requests, and (6) sustainability over sequential unlearning requests. Using these criteria, we benchmark how effectively eight popular unlearning algorithms on 7B-parameter LMs can unlearn Harry Potter books and news articles. Our results demonstrate that most algorithms can prevent verbatim memorization and knowledge memorization to varying degrees, but only one algorithm does not lead to severe privacy leakage. Furthermore, existing algorithms fail to meet deployer's expectations because they often degrade general model utility and also cannot sustainably accommodate successive unlearning requests or large-scale content removal. Our findings identify key issues with the practicality of existing unlearning algorithms on language models, and we release our benchmark to facilitate further evaluations: muse-bench.github.io
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs
Jun 26, 2024



Chart understanding plays a pivotal role when applying Multimodal Large Language Models (MLLMs) to real-world tasks such as analyzing scientific papers or financial reports. However, existing datasets often focus on oversimplified and homogeneous charts with template-based questions, leading to an over-optimistic measure of progress. We demonstrate that although open-source models can appear to outperform strong proprietary models on these benchmarks, a simple stress test with slightly different charts or questions can deteriorate performance by up to 34.5%. In this work, we propose CharXiv, a comprehensive evaluation suite involving 2,323 natural, challenging, and diverse charts from arXiv papers. CharXiv includes two types of questions: 1) descriptive questions about examining basic chart elements and 2) reasoning questions that require synthesizing information across complex visual elements in the chart. To ensure quality, all charts and questions are handpicked, curated, and verified by human experts. Our results reveal a substantial, previously underestimated gap between the reasoning skills of the strongest proprietary model (i.e., GPT-4o), which achieves 47.1% accuracy, and the strongest open-source model (i.e., InternVL Chat V1.5), which achieves 29.2%. All models lag far behind human performance of 80.5%, underscoring weaknesses in the chart understanding capabilities of existing MLLMs. We hope CharXiv facilitates future research on MLLM chart understanding by providing a more realistic and faithful measure of progress. Project page and leaderboard: https://charxiv.github.io/
Preference Learning Algorithms Do Not Learn Preference Rankings
May 29, 2024Preference learning algorithms (e.g., RLHF and DPO) are frequently used to steer LLMs to produce generations that are more preferred by humans, but our understanding of their inner workings is still limited. In this work, we study the conventional wisdom that preference learning trains models to assign higher likelihoods to more preferred outputs than less preferred outputs, measured via $\textit{ranking accuracy}$. Surprisingly, we find that most state-of-the-art preference-tuned models achieve a ranking accuracy of less than 60% on common preference datasets. We furthermore derive the $\textit{idealized ranking accuracy}$ that a preference-tuned LLM would achieve if it optimized the DPO or RLHF objective perfectly. We demonstrate that existing models exhibit a significant $\textit{alignment gap}$ -- $\textit{i.e.}$, a gap between the observed and idealized ranking accuracies. We attribute this discrepancy to the DPO objective, which is empirically and theoretically ill-suited to fix even mild ranking errors in the reference model, and derive a simple and efficient formula for quantifying the difficulty of learning a given preference datapoint. Finally, we demonstrate that ranking accuracy strongly correlates with the empirically popular win rate metric when the model is close to the reference model used in the objective, shedding further light on the differences between on-policy (e.g., RLHF) and off-policy (e.g., DPO) preference learning algorithms.
LESS: Selecting Influential Data for Targeted Instruction Tuning
Feb 20, 2024



Instruction tuning has unlocked powerful capabilities in large language models (LLMs), effectively using combined datasets to develop generalpurpose chatbots. However, real-world applications often require a specialized suite of skills (e.g., reasoning). The challenge lies in identifying the most relevant data from these extensive datasets to effectively develop specific capabilities, a setting we frame as targeted instruction tuning. We propose LESS, an optimizer-aware and practically efficient algorithm to effectively estimate data influences and perform Low-rank gradiEnt Similarity Search for instruction data selection. Crucially, LESS adapts existing influence formulations to work with the Adam optimizer and variable-length instruction data. LESS first constructs a highly reusable and transferable gradient datastore with low-dimensional gradient features and then selects examples based on their similarity to few-shot examples embodying a specific capability. Experiments show that training on a LESS-selected 5% of the data can often outperform training on the full dataset across diverse downstream tasks. Furthermore, the selected data is highly transferable: smaller models can be leveraged to select useful data for larger models and models from different families. Our qualitative analysis shows that our method goes beyond surface form cues to identify data that exemplifies the necessary reasoning skills for the intended downstream application.