 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Apr 13, 2026Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.
Continual Memorization of Factoids in Large Language Models
Nov 11, 2024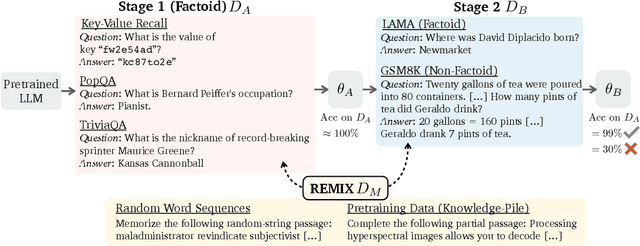
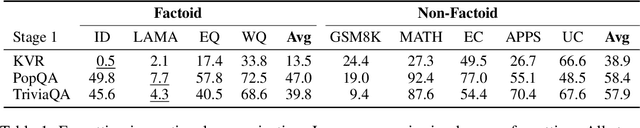
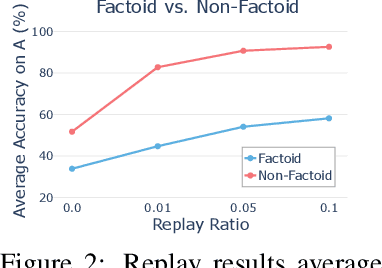
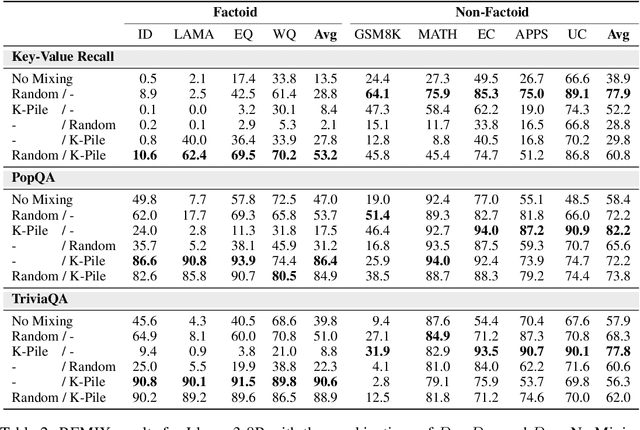
Large language models can absorb a massive amount of knowledge through pretraining, but pretraining is inefficient for acquiring long-tailed or specialized facts. Therefore, fine-tuning on specialized or new knowledge that reflects changes in the world has become popular, though it risks disrupting the model's original capabilities. We study this fragility in the context of continual memorization, where the model is trained on a small set of long-tail factoids (factual associations) and must retain these factoids after multiple stages of subsequent training on other datasets. Through extensive experiments, we show that LLMs suffer from forgetting across a wide range of subsequent tasks, and simple replay techniques do not fully prevent forgetting, especially when the factoid datasets are trained in the later stages. We posit that there are two ways to alleviate forgetting: 1) protect the memorization process as the model learns the factoids, or 2) reduce interference from training in later stages. With this insight, we develop an effective mitigation strategy: REMIX (Random and Generic Data Mixing). REMIX prevents forgetting by mixing generic data sampled from pretraining corpora or even randomly generated word sequences during each stage, despite being unrelated to the memorized factoids in the first stage. REMIX can recover performance from severe forgetting, often outperforming replay-based methods that have access to the factoids from the first stage. We then analyze how REMIX alters the learning process and find that successful forgetting prevention is associated with a pattern: the model stores factoids in earlier layers than usual and diversifies the set of layers that store these factoids. The efficacy of REMIX invites further investigation into the underlying dynamics of memorization and forgetting, opening exciting possibilities for future research.
Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization
Oct 11, 2024Direct Preference Optimization (DPO) and its variants are increasingly used for aligning language models with human preferences. Although these methods are designed to teach a model to generate preferred responses more frequently relative to dispreferred responses, prior work has observed that the likelihood of preferred responses often decreases during training. The current work sheds light on the causes and implications of this counter-intuitive phenomenon, which we term likelihood displacement. We demonstrate that likelihood displacement can be catastrophic, shifting probability mass from preferred responses to responses with an opposite meaning. As a simple example, training a model to prefer $\texttt{No}$ over $\texttt{Never}$ can sharply increase the probability of $\texttt{Yes}$. Moreover, when aligning the model to refuse unsafe prompts, we show that such displacement can unintentionally lead to unalignment, by shifting probability mass from preferred refusal responses to harmful responses (e.g., reducing the refusal rate of Llama-3-8B-Instruct from 74.4% to 33.4%). We theoretically characterize that likelihood displacement is driven by preferences that induce similar embeddings, as measured by a centered hidden embedding similarity (CHES) score. Empirically, the CHES score enables identifying which training samples contribute most to likelihood displacement in a given dataset. Filtering out these samples effectively mitigated unintentional unalignment in our experiments. More broadly, our results highlight the importance of curating data with sufficiently distinct preferences, for which we believe the CHES score may prove valuable.
Finding Transformer Circuits with Edge Pruning
Jun 24, 2024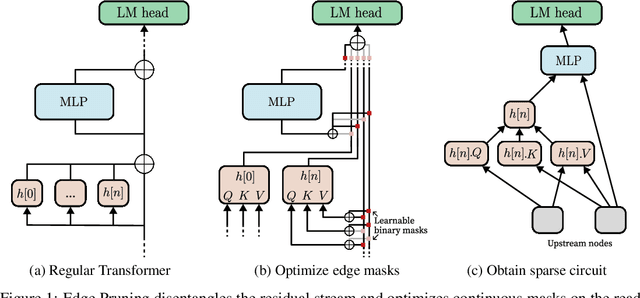
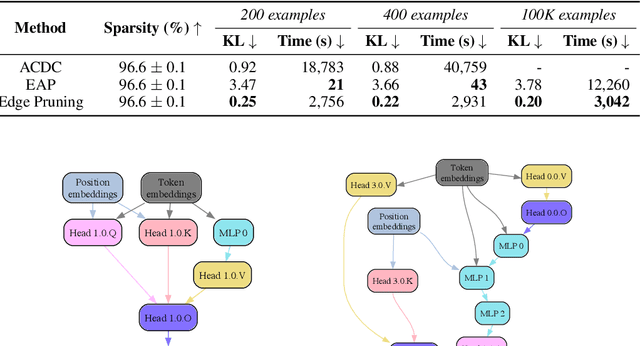
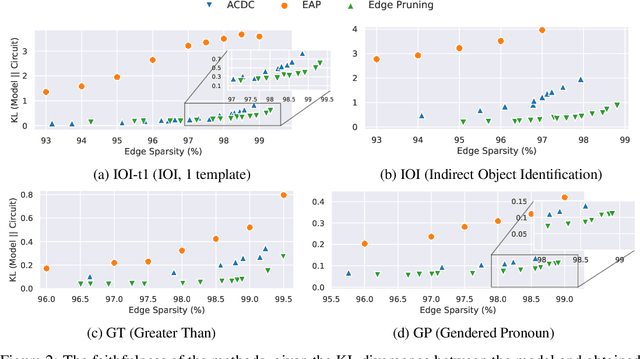
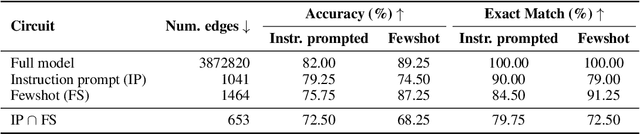
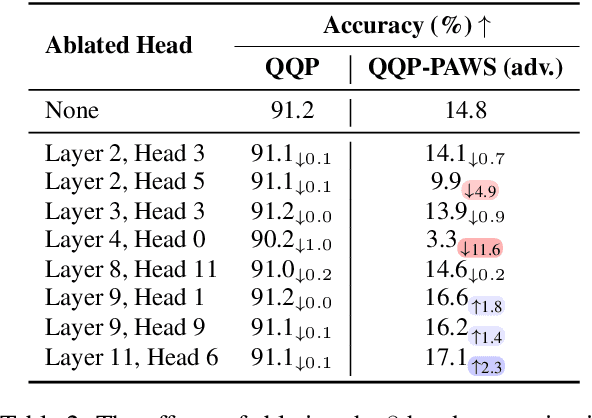
The path to interpreting a language model often proceeds via analysis of circuits -- sparse computational subgraphs of the model that capture specific aspects of its behavior. Recent work has automated the task of discovering circuits. Yet, these methods have practical limitations, as they rely either on inefficient search algorithms or inaccurate approximations. In this paper, we frame automated circuit discovery as an optimization problem and propose *Edge Pruning* as an effective and scalable solution. Edge Pruning leverages gradient-based pruning techniques, but instead of removing neurons or components, it prunes the \emph{edges} between components. Our method finds circuits in GPT-2 that use less than half the number of edges compared to circuits found by previous methods while being equally faithful to the full model predictions on standard circuit-finding tasks. Edge Pruning is efficient even with as many as 100K examples, outperforming previous methods in speed and producing substantially better circuits. It also perfectly recovers the ground-truth circuits in two models compiled with Tracr. Thanks to its efficiency, we scale Edge Pruning to CodeLlama-13B, a model over 100x the scale that prior methods operate on. We use this setting for a case study comparing the mechanisms behind instruction prompting and in-context learning. We find two circuits with more than 99.96% sparsity that match the performance of the full model and reveal that the mechanisms in the two settings overlap substantially. Our case study shows that Edge Pruning is a practical and scalable tool for interpretability and sheds light on behaviors that only emerge in large models.
The Heuristic Core: Understanding Subnetwork Generalization in Pretrained Language Models
Mar 06, 2024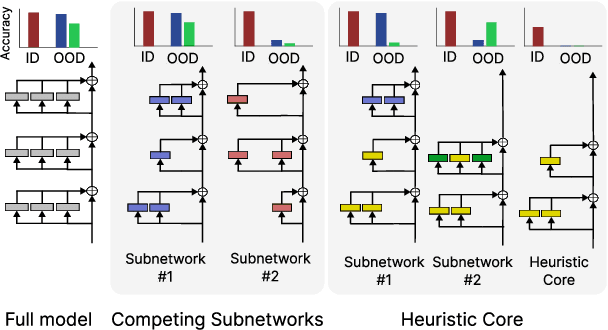


Prior work has found that pretrained language models (LMs) fine-tuned with different random seeds can achieve similar in-domain performance but generalize differently on tests of syntactic generalization. In this work, we show that, even within a single model, we can find multiple subnetworks that perform similarly in-domain, but generalize vastly differently. To better understand these phenomena, we investigate if they can be understood in terms of "competing subnetworks": the model initially represents a variety of distinct algorithms, corresponding to different subnetworks, and generalization occurs when it ultimately converges to one. This explanation has been used to account for generalization in simple algorithmic tasks. Instead of finding competing subnetworks, we find that all subnetworks -- whether they generalize or not -- share a set of attention heads, which we refer to as the heuristic core. Further analysis suggests that these attention heads emerge early in training and compute shallow, non-generalizing features. The model learns to generalize by incorporating additional attention heads, which depend on the outputs of the "heuristic" heads to compute higher-level features. Overall, our results offer a more detailed picture of the mechanisms for syntactic generalization in pretrained LMs.
Improving Language Understanding from Screenshots
Feb 21, 2024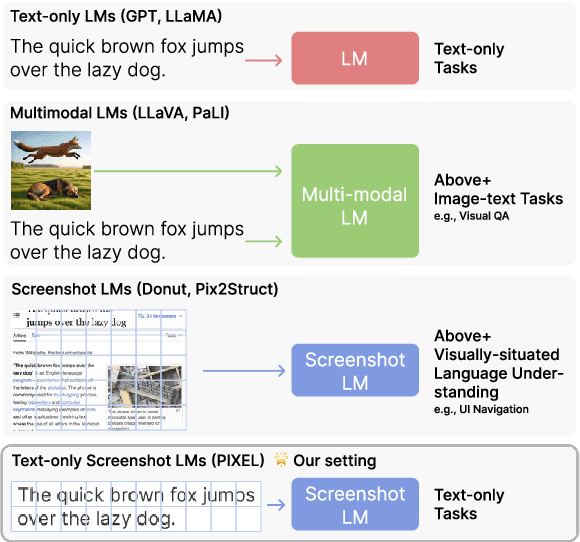
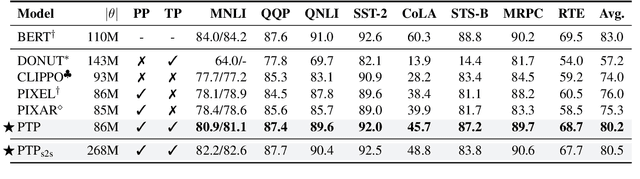
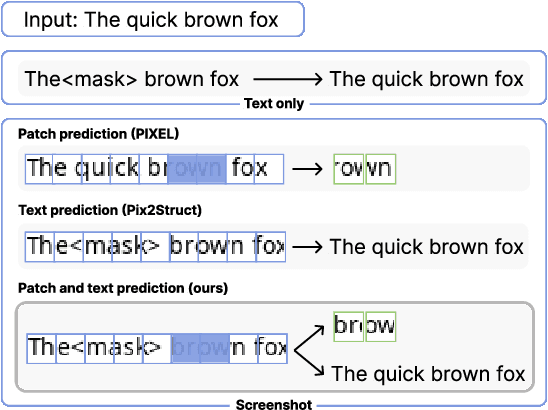
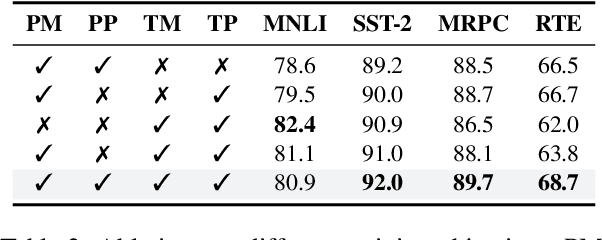
An emerging family of language models (LMs), capable of processing both text and images within a single visual view, has the promise to unlock complex tasks such as chart understanding and UI navigation. We refer to these models as screenshot language models. Despite their appeal, existing screenshot LMs substantially lag behind text-only models on language understanding tasks. To close this gap, we adopt a simplified setting where the model inputs are plain-text-rendered screenshots, and we focus on improving the text ability of screenshot LMs. We propose a novel Patch-and-Text Prediction (PTP) objective, which masks and recovers both image patches of screenshots and text within screenshots. We also conduct extensive ablation studies on masking rates and patch sizes, as well as designs for improving training stability. Our pre-trained model, while solely taking visual inputs, achieves comparable performance with BERT on 6 out of 8 GLUE tasks (within 2%) and improves up to 8% over prior work. Additionally, we extend PTP to train autoregressive screenshot LMs and demonstrate its effectiveness--our models can significantly reduce perplexity by utilizing the screenshot context. Together, we hope our findings can inspire future research on developing powerful screenshot LMs and extending their reach to broader applications.
Benchmarking and Improving Text-to-SQL Generation under Ambiguity
Oct 20, 2023
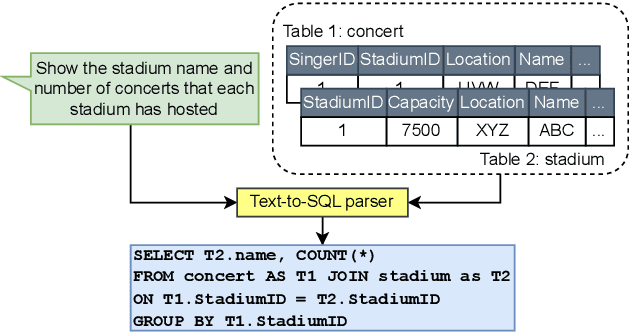

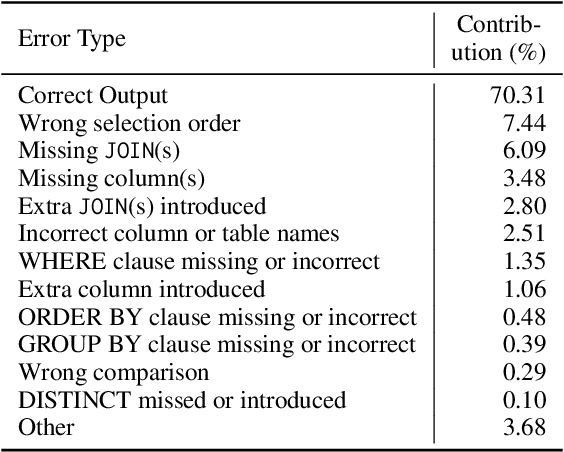
Research in Text-to-SQL conversion has been largely benchmarked against datasets where each text query corresponds to one correct SQL. However, natural language queries over real-life databases frequently involve significant ambiguity about the intended SQL due to overlapping schema names and multiple confusing relationship paths. To bridge this gap, we develop a novel benchmark called AmbiQT with over 3000 examples where each text is interpretable as two plausible SQLs due to lexical and/or structural ambiguity. When faced with ambiguity, an ideal top-$k$ decoder should generate all valid interpretations for possible disambiguation by the user. We evaluate several Text-to-SQL systems and decoding algorithms, including those employing state-of-the-art LLMs, and find them to be far from this ideal. The primary reason is that the prevalent beam search algorithm and its variants, treat SQL queries as a string and produce unhelpful token-level diversity in the top-$k$. We propose LogicalBeam, a new decoding algorithm that navigates the SQL logic space using a blend of plan-based template generation and constrained infilling. Counterfactually generated plans diversify templates while in-filling with a beam-search that branches solely on schema names provides value diversity. LogicalBeam is up to $2.5$ times more effective than state-of-the-art models at generating all candidate SQLs in the top-$k$ ranked outputs. It also enhances the top-$5$ Exact and Execution Match Accuracies on SPIDER and Kaggle DBQA.
Zero-Shot Opinion Summarization with GPT-3
Nov 29, 2022



Very large language models such as GPT-3 have shown impressive performance across a wide variety of tasks, including text summarization. In this paper, we show that this strong performance extends to opinion summarization. We explore several pipeline methods for applying GPT-3 to summarize a large collection of user reviews in a zero-shot fashion, notably approaches based on recursive summarization and selecting salient content to summarize through supervised clustering or extraction. On two datasets, an aspect-oriented summarization dataset of hotel reviews and a generic summarization dataset of Amazon and Yelp reviews, we show that the GPT-3 models achieve very strong performance in human evaluation. We argue that standard evaluation metrics do not reflect this, and evaluate against several new measures targeting faithfulness, factuality, and genericity to contrast these different methods.