 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025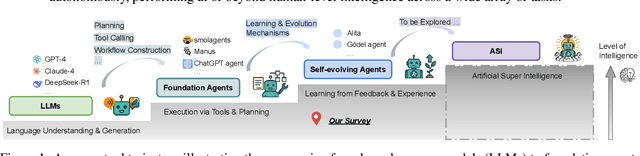

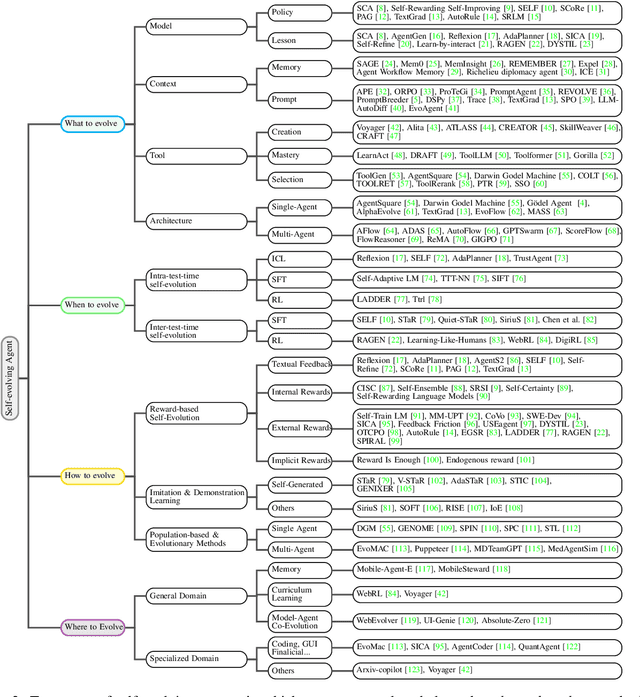
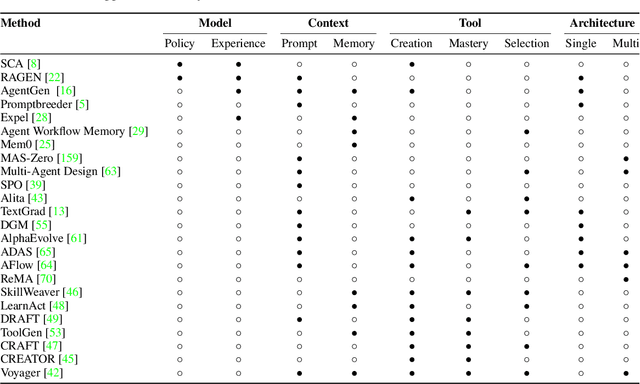
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
Are Large Language Models Reliable AI Scientists? Assessing Reverse-Engineering of Black-Box Systems
May 23, 2025Using AI to create autonomous researchers has the potential to accelerate scientific discovery. A prerequisite for this vision is understanding how well an AI model can identify the underlying structure of a black-box system from its behavior. In this paper, we explore how well a large language model (LLM) learns to identify a black-box function from passively observed versus actively collected data. We investigate the reverse-engineering capabilities of LLMs across three distinct types of black-box systems, each chosen to represent different problem domains where future autonomous AI researchers may have considerable impact: Program, Formal Language, and Math Equation. Through extensive experiments, we show that LLMs fail to extract information from observations, reaching a performance plateau that falls short of the ideal of Bayesian inference. However, we demonstrate that prompting LLMs to not only observe but also intervene -- actively querying the black-box with specific inputs to observe the resulting output -- improves performance by allowing LLMs to test edge cases and refine their beliefs. By providing the intervention data from one LLM to another, we show that this improvement is partly a result of engaging in the process of generating effective interventions, paralleling results in the literature on human learning. Further analysis reveals that engaging in intervention can help LLMs escape from two common failure modes: overcomplication, where the LLM falsely assumes prior knowledge about the black-box, and overlooking, where the LLM fails to incorporate observations. These insights provide practical guidance for helping LLMs more effectively reverse-engineer black-box systems, supporting their use in making new discoveries.
Using the Tools of Cognitive Science to Understand Large Language Models at Different Levels of Analysis
Mar 17, 2025Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical difficulties in understanding the human mind, we argue that methods developed in cognitive science can be useful for understanding large language models. We propose a framework for applying these methods based on Marr's three levels of analysis. By revisiting established cognitive science techniques relevant to each level and illustrating their potential to yield insights into the behavior and internal organization of large language models, we aim to provide a toolkit for making sense of these new kinds of minds.
Continual Memorization of Factoids in Large Language Models
Nov 11, 2024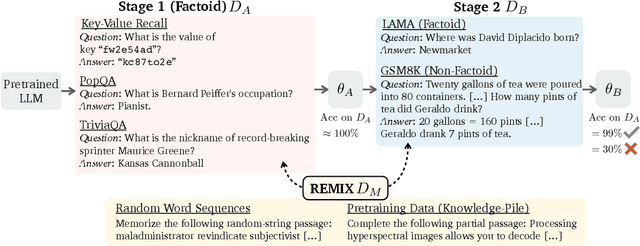
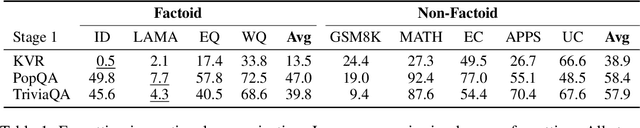
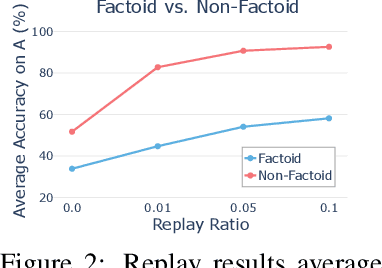
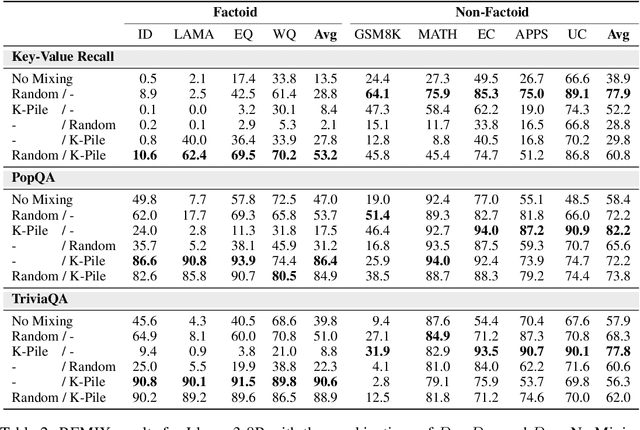
Large language models can absorb a massive amount of knowledge through pretraining, but pretraining is inefficient for acquiring long-tailed or specialized facts. Therefore, fine-tuning on specialized or new knowledge that reflects changes in the world has become popular, though it risks disrupting the model's original capabilities. We study this fragility in the context of continual memorization, where the model is trained on a small set of long-tail factoids (factual associations) and must retain these factoids after multiple stages of subsequent training on other datasets. Through extensive experiments, we show that LLMs suffer from forgetting across a wide range of subsequent tasks, and simple replay techniques do not fully prevent forgetting, especially when the factoid datasets are trained in the later stages. We posit that there are two ways to alleviate forgetting: 1) protect the memorization process as the model learns the factoids, or 2) reduce interference from training in later stages. With this insight, we develop an effective mitigation strategy: REMIX (Random and Generic Data Mixing). REMIX prevents forgetting by mixing generic data sampled from pretraining corpora or even randomly generated word sequences during each stage, despite being unrelated to the memorized factoids in the first stage. REMIX can recover performance from severe forgetting, often outperforming replay-based methods that have access to the factoids from the first stage. We then analyze how REMIX alters the learning process and find that successful forgetting prevention is associated with a pattern: the model stores factoids in earlier layers than usual and diversifies the set of layers that store these factoids. The efficacy of REMIX invites further investigation into the underlying dynamics of memorization and forgetting, opening exciting possibilities for future research.
Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse
Oct 27, 2024Chain-of-thought (CoT) prompting has become a widely used strategy for working with large language and multimodal models. While CoT has been shown to improve performance across many tasks, determining the settings in which it is effective remains an ongoing effort. In particular, it is still an open question in what settings CoT systematically reduces model performance. In this paper, we seek to identify the characteristics of tasks where CoT reduces performance by drawing inspiration from cognitive psychology, looking at cases where (i) verbal thinking or deliberation hurts performance in humans, and (ii) the constraints governing human performance generalize to language models. Three such cases are implicit statistical learning, visual recognition, and classifying with patterns containing exceptions. In extensive experiments across all three settings, we find that a diverse collection of state-of-the-art models exhibit significant drop-offs in performance (e.g., up to 36.3% absolute accuracy for OpenAI o1-preview compared to GPT-4o) when using inference-time reasoning compared to zero-shot counterparts. We also identify three tasks that satisfy condition (i) but not (ii), and find that while verbal thinking reduces human performance in these tasks, CoT retains or increases model performance. Overall, our results show that while there is not an exact parallel between the cognitive processes of models and those of humans, considering cases where thinking has negative consequences for human performance can help us identify settings where it negatively impacts models. By connecting the literature on human deliberation with evaluations of CoT, we offer a new tool that can be used in understanding the impact of prompt choices and inference-time reasoning.
TreeBoN: Enhancing Inference-Time Alignment with Speculative Tree-Search and Best-of-N Sampling
Oct 18, 2024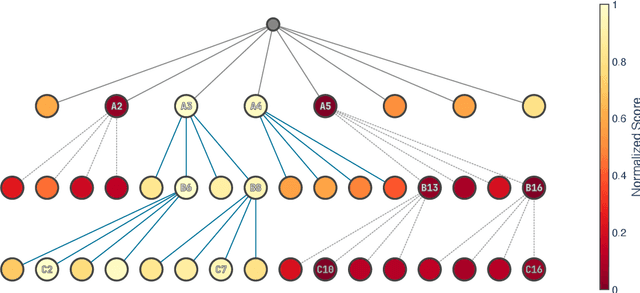

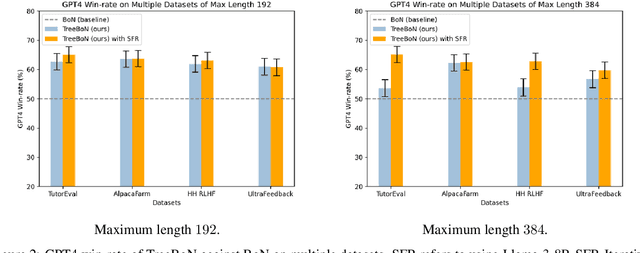

Inference-time alignment enhances the performance of large language models without requiring additional training or fine-tuning but presents challenges due to balancing computational efficiency with high-quality output. Best-of-N (BoN) sampling, as a simple yet powerful approach, generates multiple responses and selects the best one, achieving improved performance but with a high computational cost. We propose TreeBoN, a novel framework that integrates a speculative tree-search strategy into Best-of-N (BoN) Sampling. TreeBoN maintains a set of parent nodes, iteratively branching and pruning low-quality responses, thereby reducing computational overhead while maintaining high output quality. Our approach also leverages token-level rewards from Direct Preference Optimization (DPO) to guide tree expansion and prune low-quality paths. We evaluate TreeBoN using AlpacaFarm, UltraFeedback, GSM8K, HH-RLHF, and TutorEval datasets, demonstrating consistent improvements. Specifically, TreeBoN achieves a 65% win rate at maximum lengths of 192 and 384 tokens, outperforming standard BoN with the same computational cost. Furthermore, TreeBoN achieves around a 60% win rate across longer responses, showcasing its scalability and alignment efficacy.
Dr. GPT in Campus Counseling: Understanding Higher Education Students' Opinions on LLM-assisted Mental Health Services
Sep 26, 2024In response to the increasing mental health challenges faced by college students, we sought to understand their perspectives on how AI applications, particularly Large Language Models (LLMs), can be leveraged to enhance their mental well-being. Through pilot interviews with ten diverse students, we explored their opinions on the use of LLMs across five fictional scenarios: General Information Inquiry, Initial Screening, Reshaping Patient-Expert Dynamics, Long-term Care, and Follow-up Care. Our findings revealed that students' acceptance of LLMs varied by scenario, with participants highlighting both potential benefits, such as proactive engagement and personalized follow-up care, and concerns, including limitations in training data and emotional support. These insights inform how AI technology should be designed and implemented to effectively support and enhance students' mental well-being, particularly in scenarios where LLMs can complement traditional methods, while maintaining empathy and respecting individual preferences.
Large Language Models Assume People are More Rational than We Really are
Jun 24, 2024In order for AI systems to communicate effectively with people, they must understand how we make decisions. However, people's decisions are not always rational, so the implicit internal models of human decision-making in Large Language Models (LLMs) must account for this. Previous empirical evidence seems to suggest that these implicit models are accurate -- LLMs offer believable proxies of human behavior, acting how we expect humans would in everyday interactions. However, by comparing LLM behavior and predictions to a large dataset of human decisions, we find that this is actually not the case: when both simulating and predicting people's choices, a suite of cutting-edge LLMs (GPT-4o & 4-Turbo, Llama-3-8B & 70B, Claude 3 Opus) assume that people are more rational than we really are. Specifically, these models deviate from human behavior and align more closely with a classic model of rational choice -- expected value theory. Interestingly, people also tend to assume that other people are rational when interpreting their behavior. As a consequence, when we compare the inferences that LLMs and people draw from the decisions of others using another psychological dataset, we find that these inferences are highly correlated. Thus, the implicit decision-making models of LLMs appear to be aligned with the human expectation that other people will act rationally, rather than with how people actually act.
Language Models as Science Tutors
Feb 16, 2024



NLP has recently made exciting progress toward training language models (LMs) with strong scientific problem-solving skills. However, model development has not focused on real-life use-cases of LMs for science, including applications in education that require processing long scientific documents. To address this, we introduce TutorEval and TutorChat. TutorEval is a diverse question-answering benchmark consisting of questions about long chapters from STEM textbooks, written by experts. TutorEval helps measure real-life usability of LMs as scientific assistants, and it is the first benchmark combining long contexts, free-form generation, and multi-disciplinary scientific knowledge. Moreover, we show that fine-tuning base models with existing dialogue datasets leads to poor performance on TutorEval. Therefore, we create TutorChat, a dataset of 80,000 long synthetic dialogues about textbooks. We use TutorChat to fine-tune Llemma models with 7B and 34B parameters. These LM tutors specialized in math have a 32K-token context window, and they excel at TutorEval while performing strongly on GSM8K and MATH. Our datasets build on open-source materials, and we release our models, data, and evaluations.
CORGI-PM: A Chinese Corpus For Gender Bias Probing and Mitigation
Jan 01, 2023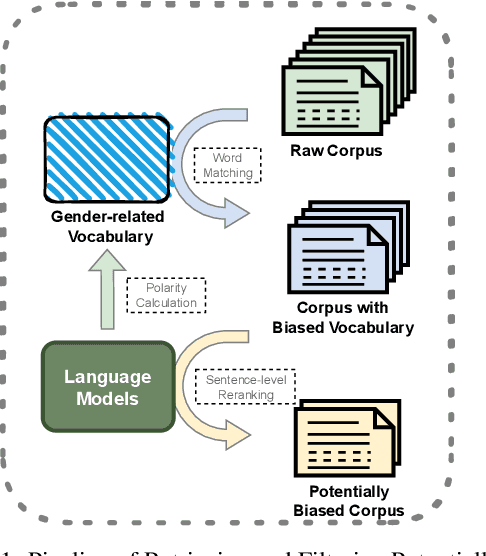
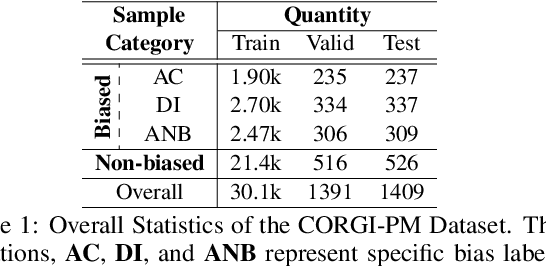
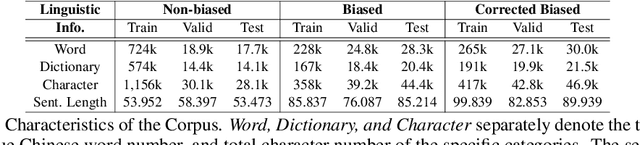
As natural language processing (NLP) for gender bias becomes a significant interdisciplinary topic, the prevalent data-driven techniques such as large-scale language models suffer from data inadequacy and biased corpus, especially for languages with insufficient resources such as Chinese. To this end, we propose a Chinese cOrpus foR Gender bIas Probing and Mitigation CORGI-PM, which contains 32.9k sentences with high-quality labels derived by following an annotation scheme specifically developed for gender bias in the Chinese context. Moreover, we address three challenges for automatic textual gender bias mitigation, which requires the models to detect, classify, and mitigate textual gender bias. We also conduct experiments with state-of-the-art language models to provide baselines. To our best knowledge, CORGI-PM is the first sentence-level Chinese corpus for gender bias probing and mitigation.