 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Capturing the Complexity of Human Strategic Decision-Making with Machine Learning
Aug 15, 2024Understanding how people behave in strategic settings--where they make decisions based on their expectations about the behavior of others--is a long-standing problem in the behavioral sciences. We conduct the largest study to date of strategic decision-making in the context of initial play in two-player matrix games, analyzing over 90,000 human decisions across more than 2,400 procedurally generated games that span a much wider space than previous datasets. We show that a deep neural network trained on these data predicts people's choices better than leading theories of strategic behavior, indicating that there is systematic variation that is not explained by those theories. We then modify the network to produce a new, interpretable behavioral model, revealing what the original network learned about people: their ability to optimally respond and their capacity to reason about others are dependent on the complexity of individual games. This context-dependence is critical in explaining deviations from the rational Nash equilibrium, response times, and uncertainty in strategic decisions. More broadly, our results demonstrate how machine learning can be applied beyond prediction to further help generate novel explanations of complex human behavior.
Large Language Models Assume People are More Rational than We Really are
Jun 24, 2024

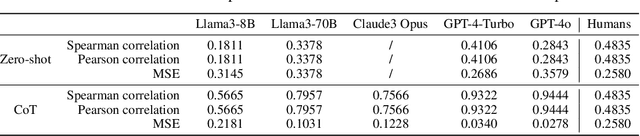

In order for AI systems to communicate effectively with people, they must understand how we make decisions. However, people's decisions are not always rational, so the implicit internal models of human decision-making in Large Language Models (LLMs) must account for this. Previous empirical evidence seems to suggest that these implicit models are accurate -- LLMs offer believable proxies of human behavior, acting how we expect humans would in everyday interactions. However, by comparing LLM behavior and predictions to a large dataset of human decisions, we find that this is actually not the case: when both simulating and predicting people's choices, a suite of cutting-edge LLMs (GPT-4o & 4-Turbo, Llama-3-8B & 70B, Claude 3 Opus) assume that people are more rational than we really are. Specifically, these models deviate from human behavior and align more closely with a classic model of rational choice -- expected value theory. Interestingly, people also tend to assume that other people are rational when interpreting their behavior. As a consequence, when we compare the inferences that LLMs and people draw from the decisions of others using another psychological dataset, we find that these inferences are highly correlated. Thus, the implicit decision-making models of LLMs appear to be aligned with the human expectation that other people will act rationally, rather than with how people actually act.
The Universal Law of Generalization Holds for Naturalistic Stimuli
Jun 14, 2023



Shepard's universal law of generalization is a remarkable hypothesis about how intelligent organisms should perceive similarity. In its broadest form, the universal law states that the level of perceived similarity between a pair of stimuli should decay as a concave function of their distance when embedded in an appropriate psychological space. While extensively studied, evidence in support of the universal law has relied on low-dimensional stimuli and small stimulus sets that are very different from their real-world counterparts. This is largely because pairwise comparisons -- as required for similarity judgments -- scale quadratically in the number of stimuli. We provide direct evidence for the universal law in a naturalistic high-dimensional regime by analyzing an existing dataset of 214,200 human similarity judgments and a newly collected dataset of 390,819 human generalization judgments (N=2406 US participants) across three sets of natural images.
End-to-end Deep Prototype and Exemplar Models for Predicting Human Behavior
Jul 17, 2020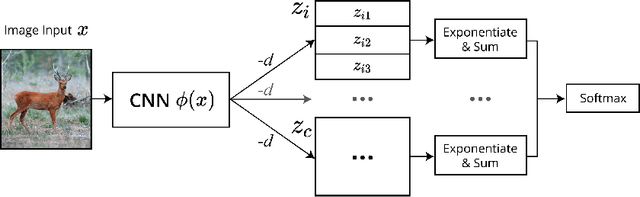



Traditional models of category learning in psychology focus on representation at the category level as opposed to the stimulus level, even though the two are likely to interact. The stimulus representations employed in such models are either hand-designed by the experimenter, inferred circuitously from human judgments, or borrowed from pretrained deep neural networks that are themselves competing models of category learning. In this work, we extend classic prototype and exemplar models to learn both stimulus and category representations jointly from raw input. This new class of models can be parameterized by deep neural networks (DNN) and trained end-to-end. Following their namesakes, we refer to them as Deep Prototype Models, Deep Exemplar Models, and Deep Gaussian Mixture Models. Compared to typical DNNs, we find that their cognitively inspired counterparts both provide better intrinsic fit to human behavior and improve ground-truth classification.
Scaling up Psychology via Scientific Regret Minimization: A Case Study in Moral Decision-Making
Oct 16, 2019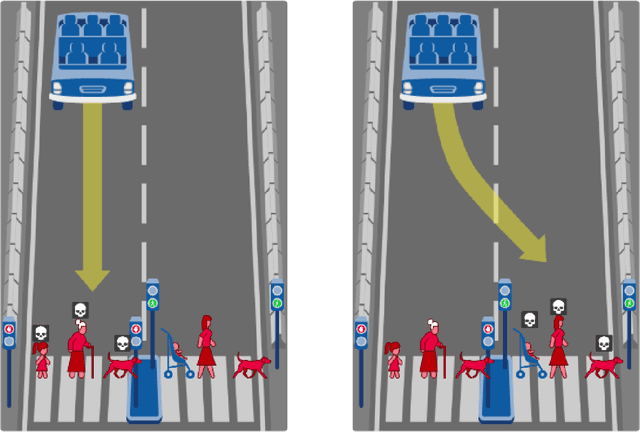
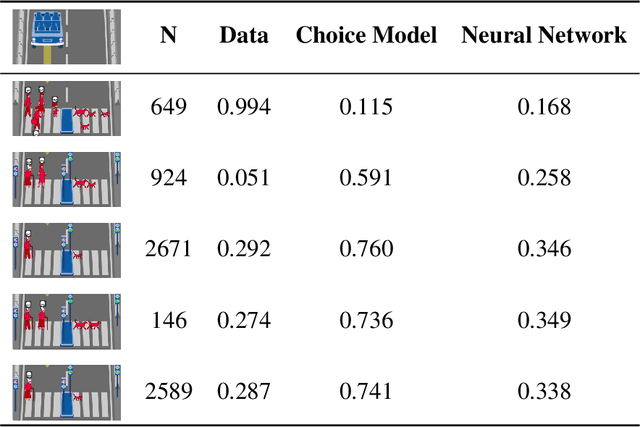
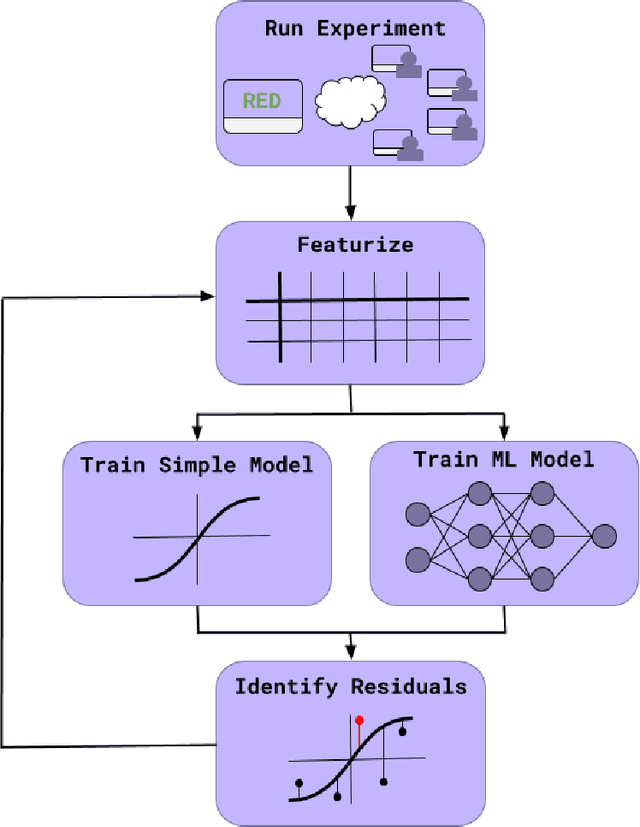
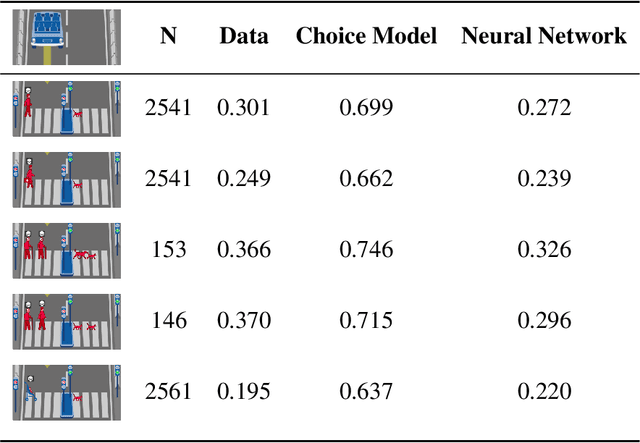
Do large datasets provide value to psychologists? Without a systematic methodology for working with such datasets, there is a valid concern that analyses will produce noise artifacts rather than true effects. In this paper, we offer a way to enable researchers to systematically build models and identify novel phenomena in large datasets. One traditional approach is to analyze the residuals of models---the biggest errors they make in predicting the data---to discover what might be missing from those models. However, once a dataset is sufficiently large, machine learning algorithms approximate the true underlying function better than the data, suggesting instead that the predictions of these data-driven models should be used to guide model-building. We call this approach "Scientific Regret Minimization" (SRM) as it focuses on minimizing errors for cases that we know should have been predictable. We demonstrate this methodology on a subset of the Moral Machine dataset, a public collection of roughly forty million moral decisions. Using SRM, we found that incorporating a set of deontological principles that capture dimensions along which groups of agents can vary (e.g. sex and age) improves a computational model of human moral judgment. Furthermore, we were able to identify and independently validate three interesting moral phenomena: criminal dehumanization, age of responsibility, and asymmetric notions of responsibility.
Human uncertainty makes classification more robust
Aug 19, 2019
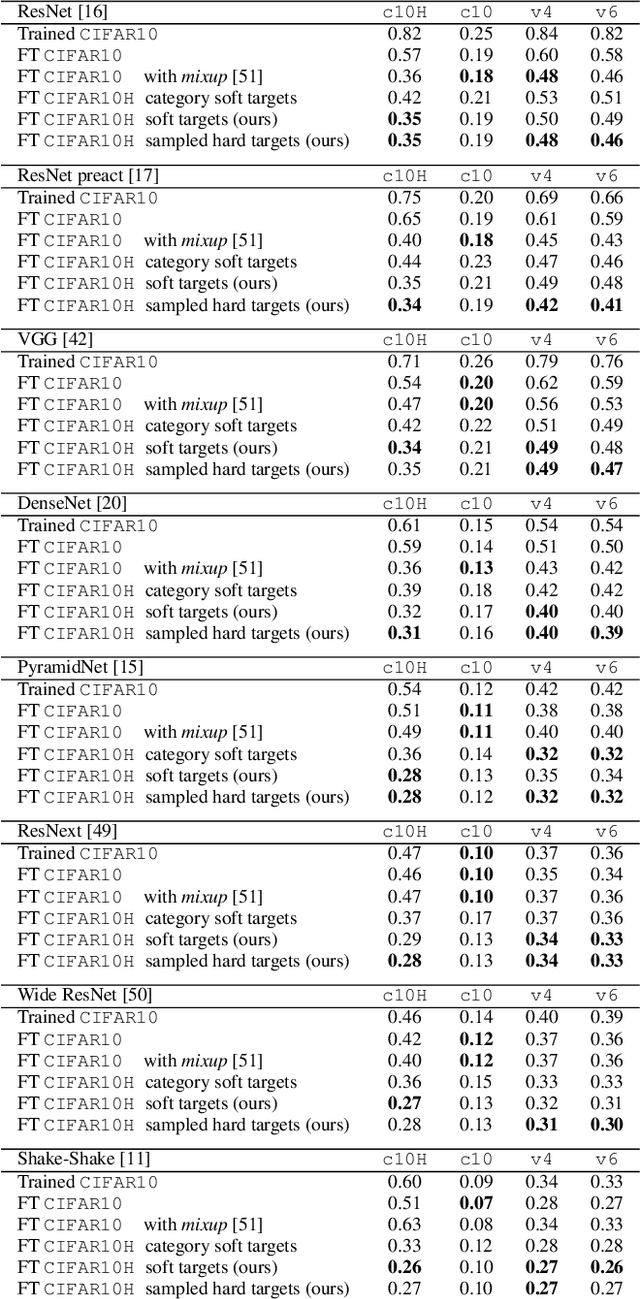
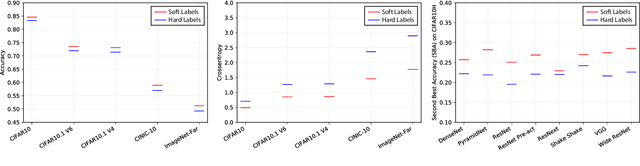
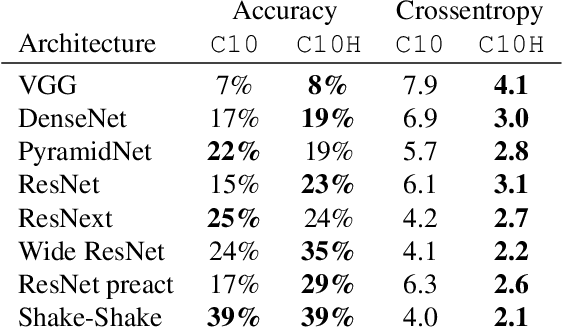
The classification performance of deep neural networks has begun to asymptote at near-perfect levels. However, their ability to generalize outside the training set and their robustness to adversarial attacks have not. In this paper, we make progress on this problem by training with full label distributions that reflect human perceptual uncertainty. We first present a new benchmark dataset which we call CIFAR10H, containing a full distribution of human labels for each image of the CIFAR10 test set. We then show that, while contemporary classifiers fail to exhibit human-like uncertainty on their own, explicit training on our dataset closes this gap, supports improved generalization to increasingly out-of-training-distribution test datasets, and confers robustness to adversarial attacks.
Cognitive Model Priors for Predicting Human Decisions
May 22, 2019


Human decision-making underlies all economic behavior. For the past four decades, human decision-making under uncertainty has continued to be explained by theoretical models based on prospect theory, a framework that was awarded the Nobel Prize in Economic Sciences. However, theoretical models of this kind have developed slowly, and robust, high-precision predictive models of human decisions remain a challenge. While machine learning is a natural candidate for solving these problems, it is currently unclear to what extent it can improve predictions obtained by current theories. We argue that this is mainly due to data scarcity, since noisy human behavior requires massive sample sizes to be accurately captured by off-the-shelf machine learning methods. To solve this problem, what is needed are machine learning models with appropriate inductive biases for capturing human behavior, and larger datasets. We offer two contributions towards this end: first, we construct "cognitive model priors" by pretraining neural networks with synthetic data generated by cognitive models (i.e., theoretical models developed by cognitive psychologists). We find that fine-tuning these networks on small datasets of real human decisions results in unprecedented state-of-the-art improvements on two benchmark datasets. Second, we present the first large-scale dataset for human decision-making, containing over 240,000 human judgments across over 13,000 decision problems. This dataset reveals the circumstances where cognitive model priors are useful, and provides a new standard for benchmarking prediction of human decisions under uncertainty.
Capturing human categorization of natural images at scale by combining deep networks and cognitive models
Apr 26, 2019
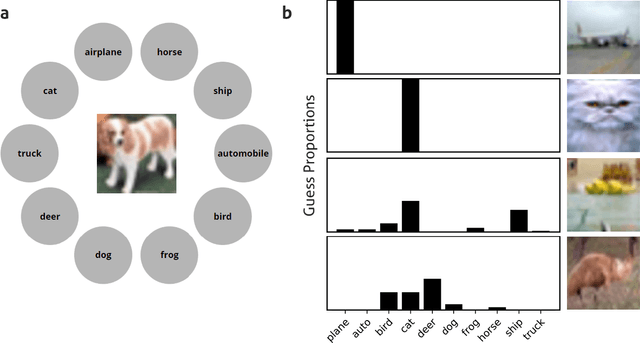
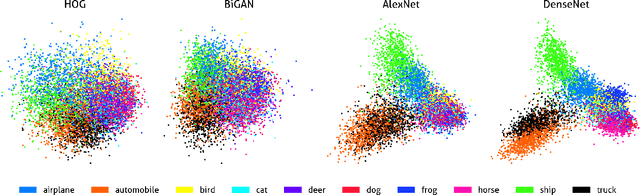

Human categorization is one of the most important and successful targets of cognitive modeling in psychology, yet decades of development and assessment of competing models have been contingent on small sets of simple, artificial experimental stimuli. Here we extend this modeling paradigm to the domain of natural images, revealing the crucial role that stimulus representation plays in categorization and its implications for conclusions about how people form categories. Applying psychological models of categorization to natural images required two significant advances. First, we conducted the first large-scale experimental study of human categorization, involving over 500,000 human categorization judgments of 10,000 natural images from ten non-overlapping object categories. Second, we addressed the traditional bottleneck of representing high-dimensional images in cognitive models by exploring the best of current supervised and unsupervised deep and shallow machine learning methods. We find that selecting sufficiently expressive, data-driven representations is crucial to capturing human categorization, and using these representations allows simple models that represent categories with abstract prototypes to outperform the more complex memory-based exemplar accounts of categorization that have dominated in studies using less naturalistic stimuli.
Predicting human decisions with behavioral theories and machine learning
Apr 15, 2019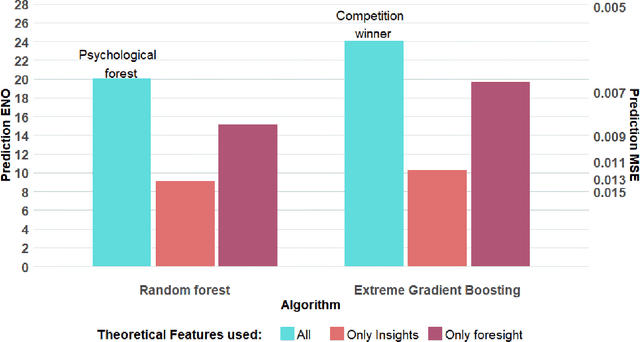
Behavioral decision theories aim to explain human behavior. Can they help predict it? An open tournament for prediction of human choices in fundamental economic decision tasks is presented. The results suggest that integration of certain behavioral theories as features in machine learning systems provides the best predictions. Surprisingly, the most useful theories for prediction build on basic properties of human and animal learning and are very different from mainstream decision theories that focus on deviations from rational choice. Moreover, we find that theoretical features should be based not only on qualitative behavioral insights (e.g. loss aversion), but also on quantitative behavioral foresights generated by functional descriptive models (e.g. Prospect Theory). Our analysis prescribes a recipe for derivation of explainable, useful predictions of human decisions.