 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Improvement and Reward Learning from Comparative Language Feedback
Oct 08, 2024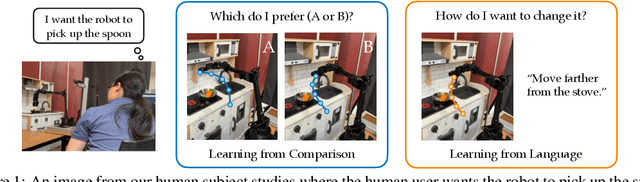
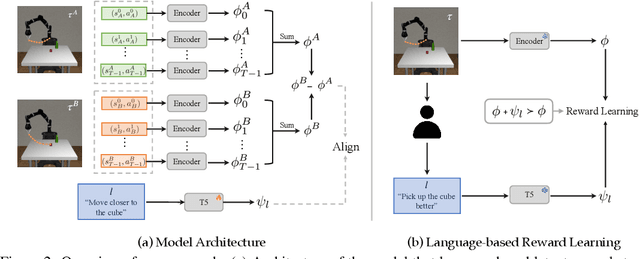
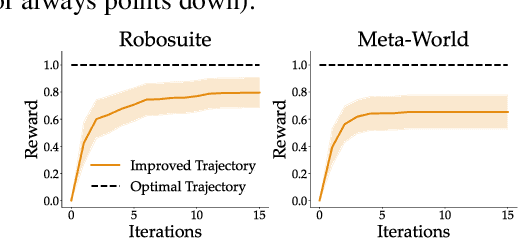
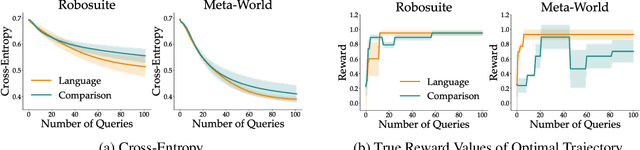
Learning from human feedback has gained traction in fields like robotics and natural language processing in recent years. While prior works mostly rely on human feedback in the form of comparisons, language is a preferable modality that provides more informative insights into user preferences. In this work, we aim to incorporate comparative language feedback to iteratively improve robot trajectories and to learn reward functions that encode human preferences. To achieve this goal, we learn a shared latent space that integrates trajectory data and language feedback, and subsequently leverage the learned latent space to improve trajectories and learn human preferences. To the best of our knowledge, we are the first to incorporate comparative language feedback into reward learning. Our simulation experiments demonstrate the effectiveness of the learned latent space and the success of our learning algorithms. We also conduct human subject studies that show our reward learning algorithm achieves a 23.9% higher subjective score on average and is 11.3% more time-efficient compared to preference-based reward learning, underscoring the superior performance of our method. Our website is at https://liralab.usc.edu/comparative-language-feedback/
A Generalized Acquisition Function for Preference-based Reward Learning
Mar 09, 2024

Preference-based reward learning is a popular technique for teaching robots and autonomous systems how a human user wants them to perform a task. Previous works have shown that actively synthesizing preference queries to maximize information gain about the reward function parameters improves data efficiency. The information gain criterion focuses on precisely identifying all parameters of the reward function. This can potentially be wasteful as many parameters may result in the same reward, and many rewards may result in the same behavior in the downstream tasks. Instead, we show that it is possible to optimize for learning the reward function up to a behavioral equivalence class, such as inducing the same ranking over behaviors, distribution over choices, or other related definitions of what makes two rewards similar. We introduce a tractable framework that can capture such definitions of similarity. Our experiments in a synthetic environment, an assistive robotics environment with domain transfer, and a natural language processing problem with real datasets demonstrate the superior performance of our querying method over the state-of-the-art information gain method.
Cognitive Model Priors for Predicting Human Decisions
May 22, 2019


Human decision-making underlies all economic behavior. For the past four decades, human decision-making under uncertainty has continued to be explained by theoretical models based on prospect theory, a framework that was awarded the Nobel Prize in Economic Sciences. However, theoretical models of this kind have developed slowly, and robust, high-precision predictive models of human decisions remain a challenge. While machine learning is a natural candidate for solving these problems, it is currently unclear to what extent it can improve predictions obtained by current theories. We argue that this is mainly due to data scarcity, since noisy human behavior requires massive sample sizes to be accurately captured by off-the-shelf machine learning methods. To solve this problem, what is needed are machine learning models with appropriate inductive biases for capturing human behavior, and larger datasets. We offer two contributions towards this end: first, we construct "cognitive model priors" by pretraining neural networks with synthetic data generated by cognitive models (i.e., theoretical models developed by cognitive psychologists). We find that fine-tuning these networks on small datasets of real human decisions results in unprecedented state-of-the-art improvements on two benchmark datasets. Second, we present the first large-scale dataset for human decision-making, containing over 240,000 human judgments across over 13,000 decision problems. This dataset reveals the circumstances where cognitive model priors are useful, and provides a new standard for benchmarking prediction of human decisions under uncertainty.
Predicting human decisions with behavioral theories and machine learning
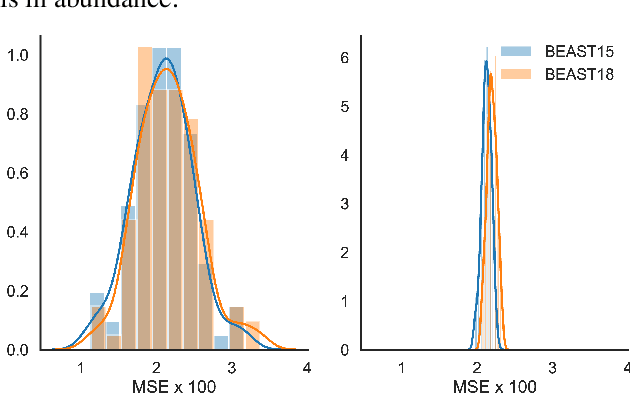
Apr 15, 2019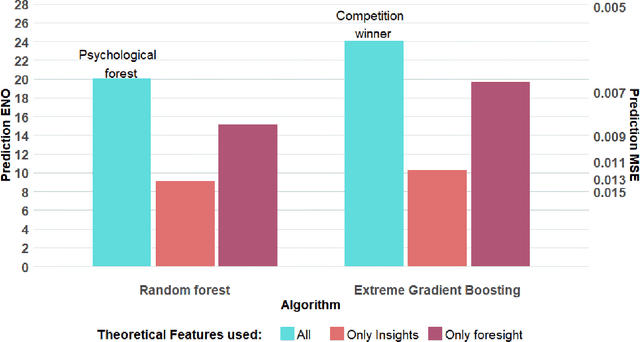
Behavioral decision theories aim to explain human behavior. Can they help predict it? An open tournament for prediction of human choices in fundamental economic decision tasks is presented. The results suggest that integration of certain behavioral theories as features in machine learning systems provides the best predictions. Surprisingly, the most useful theories for prediction build on basic properties of human and animal learning and are very different from mainstream decision theories that focus on deviations from rational choice. Moreover, we find that theoretical features should be based not only on qualitative behavioral insights (e.g. loss aversion), but also on quantitative behavioral foresights generated by functional descriptive models (e.g. Prospect Theory). Our analysis prescribes a recipe for derivation of explainable, useful predictions of human decisions.
Neural Block Sampling
Dec 14, 2017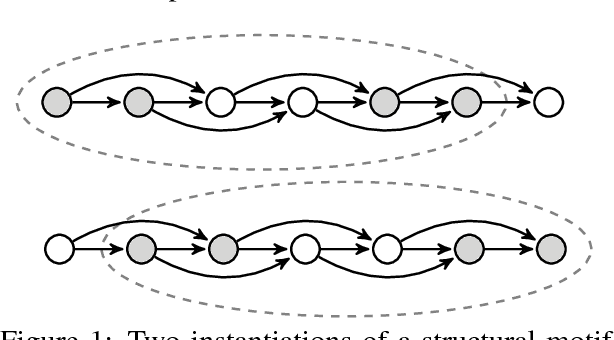
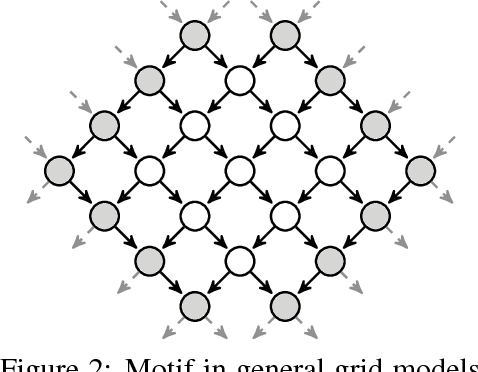
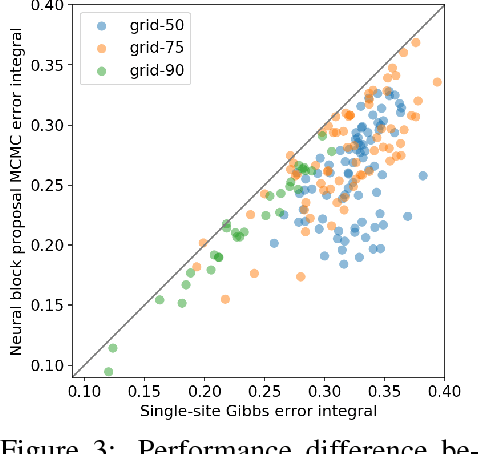

Efficient Monte Carlo inference often requires manual construction of model-specific proposals. We propose an approach to automated proposal construction by training neural networks to provide fast approximations to block Gibbs conditionals. The learned proposals generalize to occurrences of common structural motifs both within a given model and across models, allowing for the construction of a library of learned inference primitives that can accelerate inference on unseen models with no model-specific training required. We explore several applications including open-universe Gaussian mixture models, in which our learned proposals outperform a hand-tuned sampler, and a real-world named entity recognition task, in which our sampler's ability to escape local modes yields higher final F1 scores than single-site Gibbs.
Signal-based Bayesian Seismic Monitoring
Mar 02, 2017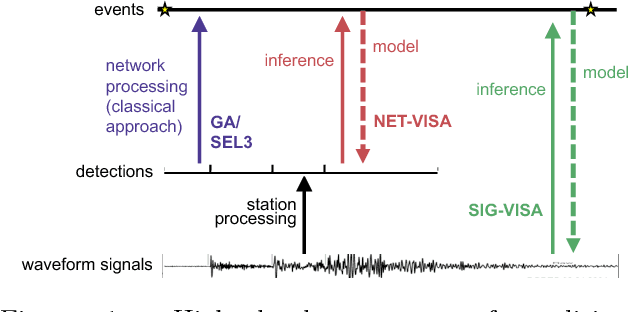


Detecting weak seismic events from noisy sensors is a difficult perceptual task. We formulate this task as Bayesian inference and propose a generative model of seismic events and signals across a network of spatially distributed stations. Our system, SIGVISA, is the first to directly model seismic waveforms, allowing it to incorporate a rich representation of the physics underlying the signal generation process. We use Gaussian processes over wavelet parameters to predict detailed waveform fluctuations based on historical events, while degrading smoothly to simple parametric envelopes in regions with no historical seismicity. Evaluating on data from the western US, we recover three times as many events as previous work, and reduce mean location errors by a factor of four while greatly increasing sensitivity to low-magnitude events.
Gaussian Process Random Fields
Oct 31, 2015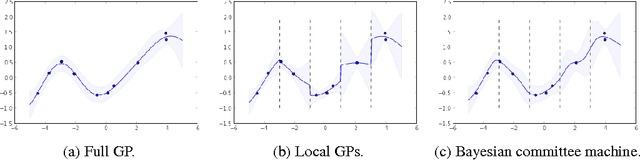
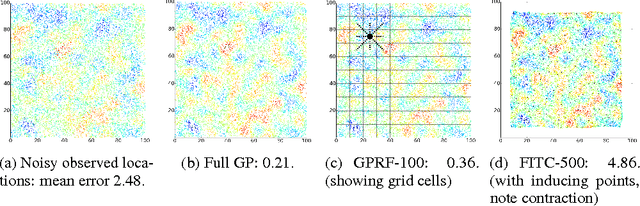
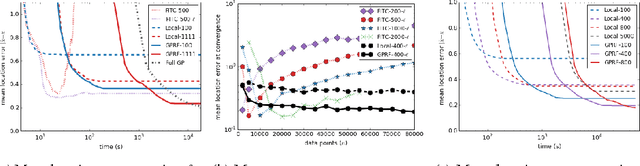
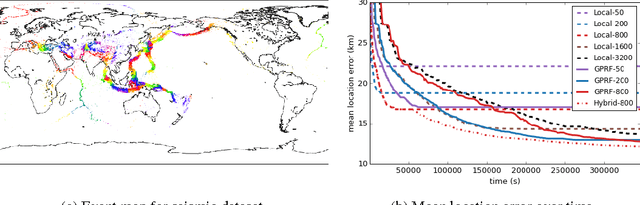
Gaussian processes have been successful in both supervised and unsupervised machine learning tasks, but their computational complexity has constrained practical applications. We introduce a new approximation for large-scale Gaussian processes, the Gaussian Process Random Field (GPRF), in which local GPs are coupled via pairwise potentials. The GPRF likelihood is a simple, tractable, and parallelizeable approximation to the full GP marginal likelihood, enabling latent variable modeling and hyperparameter selection on large datasets. We demonstrate its effectiveness on synthetic spatial data as well as a real-world application to seismic event location.
The Extended Parameter Filter
May 08, 2013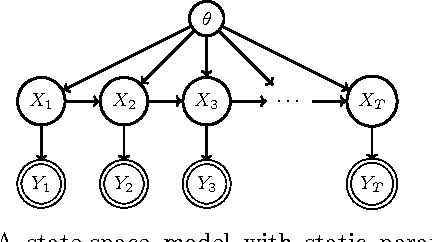
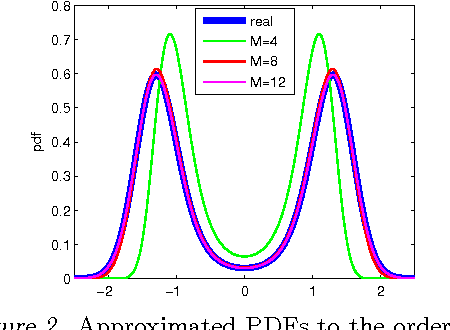
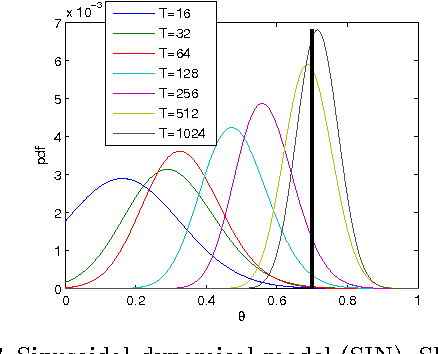

The parameters of temporal models, such as dynamic Bayesian networks, may be modelled in a Bayesian context as static or atemporal variables that influence transition probabilities at every time step. Particle filters fail for models that include such variables, while methods that use Gibbs sampling of parameter variables may incur a per-sample cost that grows linearly with the length of the observation sequence. Storvik devised a method for incremental computation of exact sufficient statistics that, for some cases, reduces the per-sample cost to a constant. In this paper, we demonstrate a connection between Storvik's filter and a Kalman filter in parameter space and establish more general conditions under which Storvik's filter works. Drawing on an analogy to the extended Kalman filter, we develop and analyze, both theoretically and experimentally, a Taylor approximation to the parameter posterior that allows Storvik's method to be applied to a broader class of models. Our experiments on both synthetic examples and real applications show improvement over existing methods.