 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Characterizing Model Robustness via Natural Input Gradients
Sep 30, 2024Adversarially robust models are locally smooth around each data sample so that small perturbations cannot drastically change model outputs. In modern systems, such smoothness is usually obtained via Adversarial Training, which explicitly enforces models to perform well on perturbed examples. In this work, we show the surprising effectiveness of instead regularizing the gradient with respect to model inputs on natural examples only. Penalizing input Gradient Norm is commonly believed to be a much inferior approach. Our analyses identify that the performance of Gradient Norm regularization critically depends on the smoothness of activation functions, and are in fact extremely effective on modern vision transformers that adopt smooth activations over piecewise linear ones (eg, ReLU), contrary to prior belief. On ImageNet-1k, Gradient Norm training achieves > 90% the performance of state-of-the-art PGD-3 Adversarial Training} (52% vs.~56%), while using only 60% computation cost of the state-of-the-art without complex adversarial optimization. Our analyses also highlight the relationship between model robustness and properties of natural input gradients, such as asymmetric sample and channel statistics. Surprisingly, we find model robustness can be significantly improved by simply regularizing its gradients to concentrate on image edges without explicit conditioning on the gradient norm.
CycleGAN with Better Cycles
Aug 27, 2024CycleGAN provides a framework to train image-to-image translation with unpaired datasets using cycle consistency loss [4]. While results are great in many applications, the pixel level cycle consistency can potentially be problematic and causes unrealistic images in certain cases. In this project, we propose three simple modifications to cycle consistency, and show that such an approach achieves better results with fewer artifacts.
The Platonic Representation Hypothesis
May 13, 2024We argue that representations in AI models, particularly deep networks, are converging. First, we survey many examples of convergence in the literature: over time and across multiple domains, the ways by which different neural networks represent data are becoming more aligned. Next, we demonstrate convergence across data modalities: as vision models and language models get larger, they measure distance between datapoints in a more and more alike way. We hypothesize that this convergence is driving toward a shared statistical model of reality, akin to Plato's concept of an ideal reality. We term such a representation the platonic representation and discuss several possible selective pressures toward it. Finally, we discuss the implications of these trends, their limitations, and counterexamples to our analysis.
Generalizing Dataset Distillation via Deep Generative Prior
May 03, 2023Dataset Distillation aims to distill an entire dataset's knowledge into a few synthetic images. The idea is to synthesize a small number of synthetic data points that, when given to a learning algorithm as training data, result in a model approximating one trained on the original data. Despite recent progress in the field, existing dataset distillation methods fail to generalize to new architectures and scale to high-resolution datasets. To overcome the above issues, we propose to use the learned prior from pre-trained deep generative models to synthesize the distilled data. To achieve this, we present a new optimization algorithm that distills a large number of images into a few intermediate feature vectors in the generative model's latent space. Our method augments existing techniques, significantly improving cross-architecture generalization in all settings.
Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning
Apr 06, 2023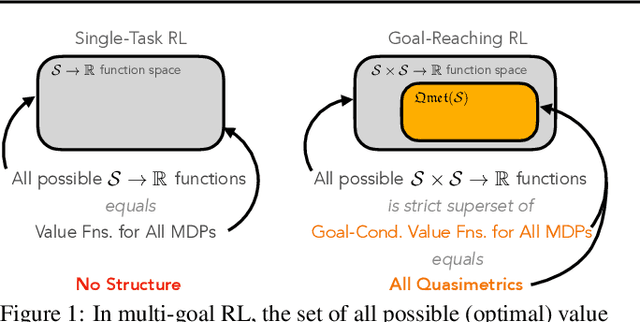
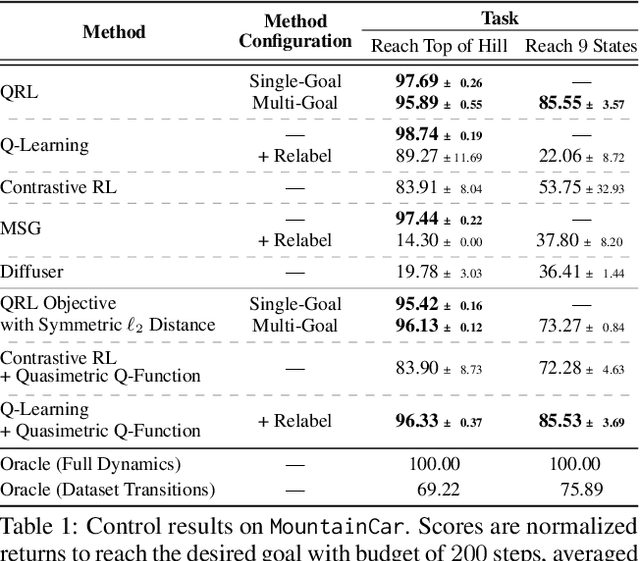
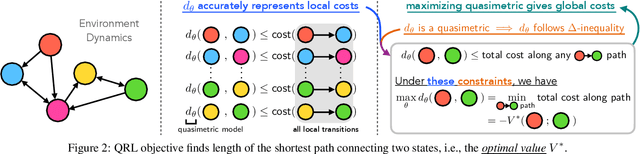
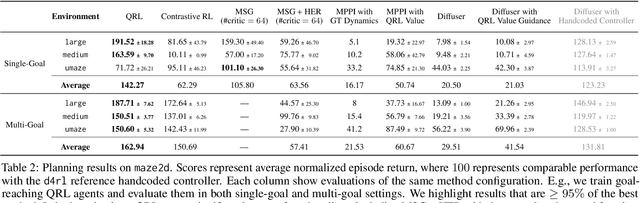
In goal-reaching reinforcement learning (RL), the optimal value function has a particular geometry, called quasimetric structure. This paper introduces Quasimetric Reinforcement Learning (QRL), a new RL method that utilizes quasimetric models to learn optimal value functions. Distinct from prior approaches, the QRL objective is specifically designed for quasimetrics, and provides strong theoretical recovery guarantees. Empirically, we conduct thorough analyses on a discretized MountainCar environment, identifying properties of QRL and its advantages over alternatives. On offline and online goal-reaching benchmarks, QRL also demonstrates improved sample efficiency and performance, across both state-based and image-based observations.
Deep Augmentation: Enhancing Self-Supervised Learning through Transformations in Higher Activation Space
Mar 25, 2023



We introduce Deep Augmentation, an approach to data augmentation using dropout to dynamically transform a targeted layer within a neural network, with the option to use the stop-gradient operation, offering significant improvements in model performance and generalization. We demonstrate the efficacy of Deep Augmentation through extensive experiments on contrastive learning tasks in computer vision and NLP domains, where we observe substantial performance gains with ResNets and Transformers as the underlying models. Our experimentation reveals that targeting deeper layers with Deep Augmentation outperforms augmenting the input data, and the simple network- and data-agnostic nature of this approach enables its seamless integration into computer vision and NLP pipelines.
Steerable Equivariant Representation Learning
Feb 22, 2023



Pre-trained deep image representations are useful for post-training tasks such as classification through transfer learning, image retrieval, and object detection. Data augmentations are a crucial aspect of pre-training robust representations in both supervised and self-supervised settings. Data augmentations explicitly or implicitly promote invariance in the embedding space to the input image transformations. This invariance reduces generalization to those downstream tasks which rely on sensitivity to these particular data augmentations. In this paper, we propose a method of learning representations that are instead equivariant to data augmentations. We achieve this equivariance through the use of steerable representations. Our representations can be manipulated directly in embedding space via learned linear maps. We demonstrate that our resulting steerable and equivariant representations lead to better performance on transfer learning and robustness: e.g. we improve linear probe top-1 accuracy by between 1% to 3% for transfer; and ImageNet-C accuracy by upto 3.4%. We further show that the steerability of our representations provides significant speedup (nearly 50x) for test-time augmentations; by applying a large number of augmentations for out-of-distribution detection, we significantly improve OOD AUC on the ImageNet-C dataset over an invariant representation.
Procedural Image Programs for Representation Learning
Nov 29, 2022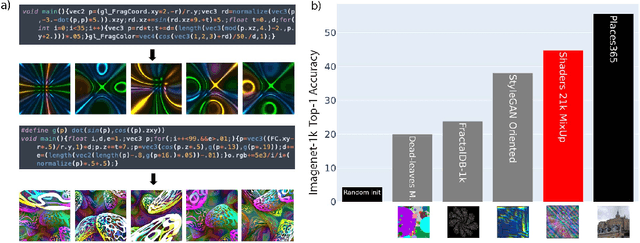
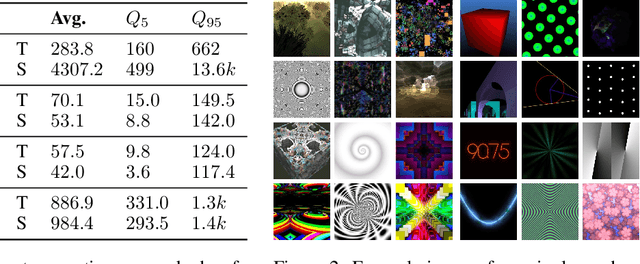
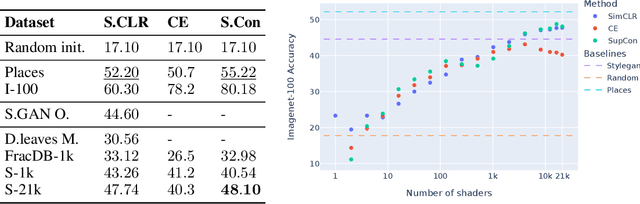
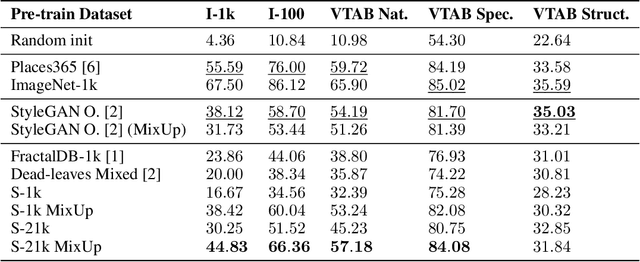
Learning image representations using synthetic data allows training neural networks without some of the concerns associated with real images, such as privacy and bias. Existing work focuses on a handful of curated generative processes which require expert knowledge to design, making it hard to scale up. To overcome this, we propose training with a large dataset of twenty-one thousand programs, each one generating a diverse set of synthetic images. These programs are short code snippets, which are easy to modify and fast to execute using OpenGL. The proposed dataset can be used for both supervised and unsupervised representation learning, and reduces the gap between pre-training with real and procedurally generated images by 38%.
* 29 pages, Accepted in the Conference on Neural Information Processing Systems 2022 (NeurIPS 2022)
Improved Representation of Asymmetrical Distances with Interval Quasimetric Embeddings
Nov 28, 2022



Asymmetrical distance structures (quasimetrics) are ubiquitous in our lives and are gaining more attention in machine learning applications. Imposing such quasimetric structures in model representations has been shown to improve many tasks, including reinforcement learning (RL) and causal relation learning. In this work, we present four desirable properties in such quasimetric models, and show how prior works fail at them. We propose Interval Quasimetric Embedding (IQE), which is designed to satisfy all four criteria. On three quasimetric learning experiments, IQEs show strong approximation and generalization abilities, leading to better performance and improved efficiency over prior methods. Project Page: https://www.tongzhouwang.info/interval_quasimetric_embedding Quasimetric Learning Code Package: https://www.github.com/quasimetric-learning/torch-quasimetric