 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Surveillance with High-Frequency Radar
Apr 05, 2025

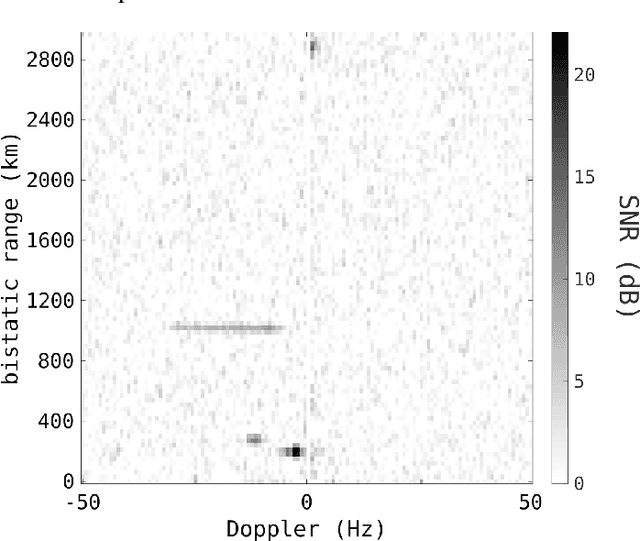

High-Frequency (HF) radar is well suited to the surveillance of low-earth-orbit space. For large targets, a small deployable HF radar is able to match the detection performance of much larger space surveillance radar systems operating at higher frequencies. However, there are some unique challenges associated with the use of HF, including the range--Doppler coupling bias, coarse detection-level localisation, and the presence of meteor returns and other unwanted signals. This paper details the use of HF radar for space surveillance, including signal processing and radar product formation, tracking, ionospheric correction, and orbit determination. It is shown that by fusing measurements from multiple passes, accurate orbital estimates can be obtained. Included are results from recent SpaceFest trials of the Defence Science and Technology Group's HF space surveillance radar, achieving real-time wide-area surveillance in tracking, orbit determination, and cueing of other space surveillance sensors.
What if Eye...? Computationally Recreating Vision Evolution
Jan 25, 2025



Vision systems in nature show remarkable diversity, from simple light-sensitive patches to complex camera eyes with lenses. While natural selection has produced these eyes through countless mutations over millions of years, they represent just one set of realized evolutionary paths. Testing hypotheses about how environmental pressures shaped eye evolution remains challenging since we cannot experimentally isolate individual factors. Computational evolution offers a way to systematically explore alternative trajectories. Here we show how environmental demands drive three fundamental aspects of visual evolution through an artificial evolution framework that co-evolves both physical eye structure and neural processing in embodied agents. First, we demonstrate computational evidence that task specific selection drives bifurcation in eye evolution - orientation tasks like navigation in a maze leads to distributed compound-type eyes while an object discrimination task leads to the emergence of high-acuity camera-type eyes. Second, we reveal how optical innovations like lenses naturally emerge to resolve fundamental tradeoffs between light collection and spatial precision. Third, we uncover systematic scaling laws between visual acuity and neural processing, showing how task complexity drives coordinated evolution of sensory and computational capabilities. Our work introduces a novel paradigm that illuminates evolutionary principles shaping vision by creating targeted single-player games where embodied agents must simultaneously evolve visual systems and learn complex behaviors. Through our unified genetic encoding framework, these embodied agents serve as next-generation hypothesis testing machines while providing a foundation for designing manufacturable bio-inspired vision systems.
Self-Assembly of a Biologically Plausible Learning Circuit
Dec 28, 2024



Over the last four decades, the amazing success of deep learning has been driven by the use of Stochastic Gradient Descent (SGD) as the main optimization technique. The default implementation for the computation of the gradient for SGD is backpropagation, which, with its variations, is used to this day in almost all computer implementations. From the perspective of neuroscientists, however, the consensus is that backpropagation is unlikely to be used by the brain. Though several alternatives have been discussed, none is so far supported by experimental evidence. Here we propose a circuit for updating the weights in a network that is biologically plausible, works as well as backpropagation, and leads to verifiable predictions about the anatomy and the physiology of a characteristic motif of four plastic synapses between ascending and descending cortical streams. A key prediction of our proposal is a surprising property of self-assembly of the basic circuit, emerging from initial random connectivity and heterosynaptic plasticity rules.
ImageNet-RIB Benchmark: Large Pre-Training Datasets Don't Guarantee Robustness after Fine-Tuning
Oct 28, 2024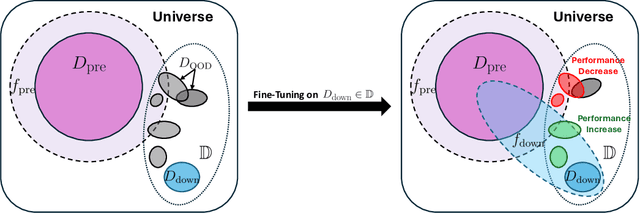
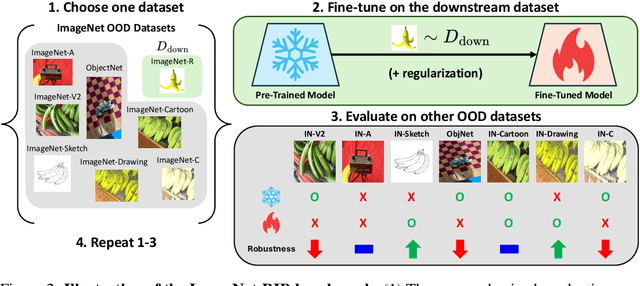

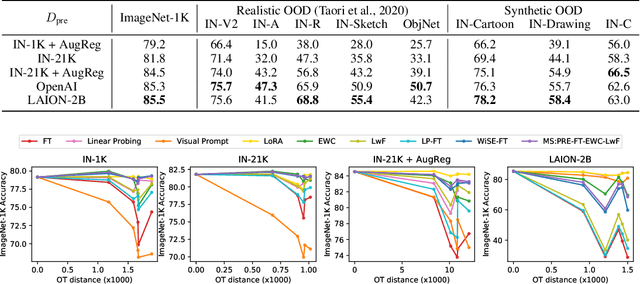
Highly performant large-scale pre-trained models promise to also provide a valuable foundation for learning specialized tasks, by fine-tuning the model to the desired task. By starting from a good general-purpose model, the goal is to achieve both specialization in the target task and maintain robustness. To assess the robustness of models to out-of-distribution samples after fine-tuning on downstream datasets, we introduce a new robust fine-tuning benchmark, ImageNet-RIB (Robustness Inheritance Benchmark). The benchmark consists of a set of related but distinct specialized (downstream) tasks; pre-trained models are fine-tuned on one task in the set and their robustness is assessed on the rest, iterating across all tasks for fine-tuning and assessment. We find that the continual learning methods, EWC and LwF maintain robustness after fine-tuning though fine-tuning generally does reduce performance on generalization to related downstream tasks across models. Not surprisingly, models pre-trained on large and rich datasets exhibit higher initial robustness across datasets and suffer more pronounced degradation during fine-tuning. The distance between the pre-training and downstream datasets, measured by optimal transport, predicts this performance degradation on the pre-training dataset. However, counterintuitively, model robustness after fine-tuning on related downstream tasks is the worst when the pre-training dataset is the richest and the most diverse. This suggests that starting with the strongest foundation model is not necessarily the best approach for performance on specialist tasks. The benchmark thus offers key insights for developing more resilient fine-tuning strategies and building robust machine learning models. https://jd730.github.io/projects/ImageNet-RIB
Training the Untrainable: Introducing Inductive Bias via Representational Alignment
Oct 26, 2024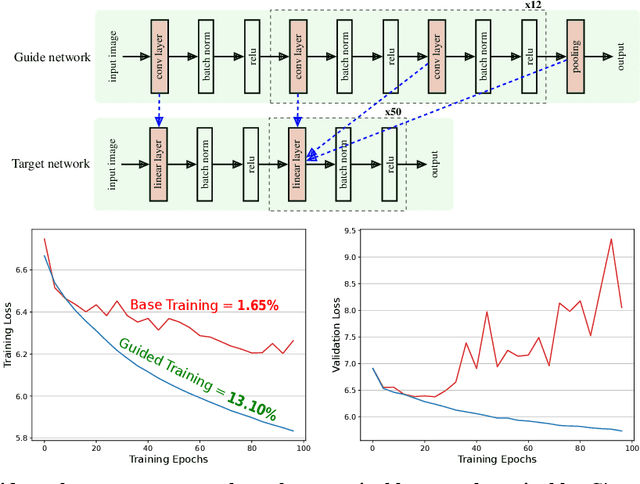
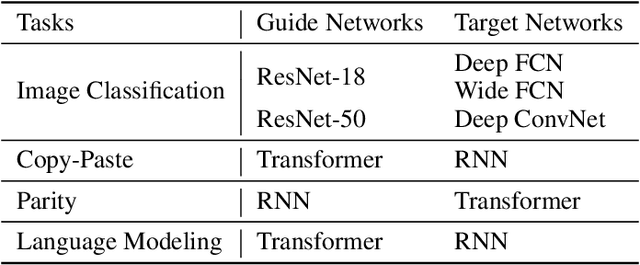
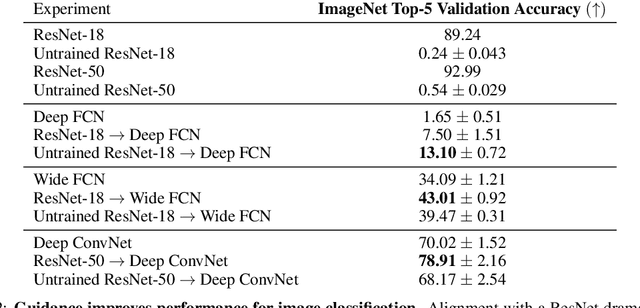
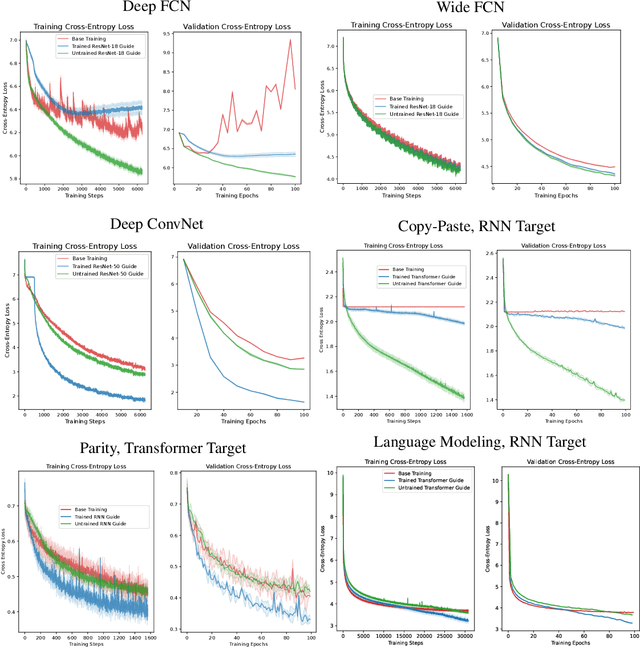
We demonstrate that architectures which traditionally are considered to be ill-suited for a task can be trained using inductive biases from another architecture. Networks are considered untrainable when they overfit, underfit, or converge to poor results even when tuning their hyperparameters. For example, plain fully connected networks overfit on object recognition while deep convolutional networks without residual connections underfit. The traditional answer is to change the architecture to impose some inductive bias, although what that bias is remains unknown. We introduce guidance, where a guide network guides a target network using a neural distance function. The target is optimized to perform well and to match its internal representations, layer-by-layer, to those of the guide; the guide is unchanged. If the guide is trained, this transfers over part of the architectural prior and knowledge of the guide to the target. If the guide is untrained, this transfers over only part of the architectural prior of the guide. In this manner, we can investigate what kinds of priors different architectures place on untrainable networks such as fully connected networks. We demonstrate that this method overcomes the immediate overfitting of fully connected networks on vision tasks, makes plain CNNs competitive to ResNets, closes much of the gap between plain vanilla RNNs and Transformers, and can even help Transformers learn tasks which RNNs can perform more easily. We also discover evidence that better initializations of fully connected networks likely exist to avoid overfitting. Our method provides a mathematical tool to investigate priors and architectures, and in the long term, may demystify the dark art of architecture creation, even perhaps turning architectures into a continuous optimizable parameter of the network.
The Platonic Representation Hypothesis
May 13, 2024We argue that representations in AI models, particularly deep networks, are converging. First, we survey many examples of convergence in the literature: over time and across multiple domains, the ways by which different neural networks represent data are becoming more aligned. Next, we demonstrate convergence across data modalities: as vision models and language models get larger, they measure distance between datapoints in a more and more alike way. We hypothesize that this convergence is driving toward a shared statistical model of reality, akin to Plato's concept of an ideal reality. We term such a representation the platonic representation and discuss several possible selective pressures toward it. Finally, we discuss the implications of these trends, their limitations, and counterexamples to our analysis.
Training Neural Networks from Scratch with Parallel Low-Rank Adapters
Feb 26, 2024The scalability of deep learning models is fundamentally limited by computing resources, memory, and communication. Although methods like low-rank adaptation (LoRA) have reduced the cost of model finetuning, its application in model pre-training remains largely unexplored. This paper explores extending LoRA to model pre-training, identifying the inherent constraints and limitations of standard LoRA in this context. We introduce LoRA-the-Explorer (LTE), a novel bi-level optimization algorithm designed to enable parallel training of multiple low-rank heads across computing nodes, thereby reducing the need for frequent synchronization. Our approach includes extensive experimentation on vision transformers using various vision datasets, demonstrating that LTE is competitive with standard pre-training.
How to guess a gradient
Dec 07, 2023How much can you say about the gradient of a neural network without computing a loss or knowing the label? This may sound like a strange question: surely the answer is "very little." However, in this paper, we show that gradients are more structured than previously thought. Gradients lie in a predictable low-dimensional subspace which depends on the network architecture and incoming features. Exploiting this structure can significantly improve gradient-free optimization schemes based on directional derivatives, which have struggled to scale beyond small networks trained on toy datasets. We study how to narrow the gap in optimization performance between methods that calculate exact gradients and those that use directional derivatives. Furthermore, we highlight new challenges in overcoming the large gap between optimizing with exact gradients and guessing the gradients.
Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks
May 15, 2023



This work examines the challenges of training neural networks using vector quantization using straight-through estimation. We find that a primary cause of training instability is the discrepancy between the model embedding and the code-vector distribution. We identify the factors that contribute to this issue, including the codebook gradient sparsity and the asymmetric nature of the commitment loss, which leads to misaligned code-vector assignments. We propose to address this issue via affine re-parameterization of the code vectors. Additionally, we introduce an alternating optimization to reduce the gradient error introduced by the straight-through estimation. Moreover, we propose an improvement to the commitment loss to ensure better alignment between the codebook representation and the model embedding. These optimization methods improve the mathematical approximation of the straight-through estimation and, ultimately, the model performance. We demonstrate the effectiveness of our methods on several common model architectures, such as AlexNet, ResNet, and ViT, across various tasks, including image classification and generative modeling.
System identification of neural systems: If we got it right, would we know?
Feb 13, 2023

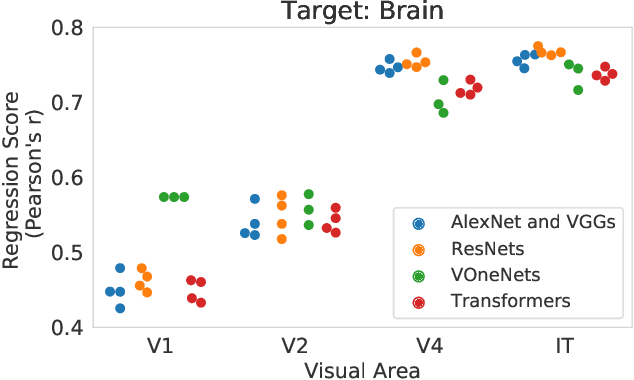
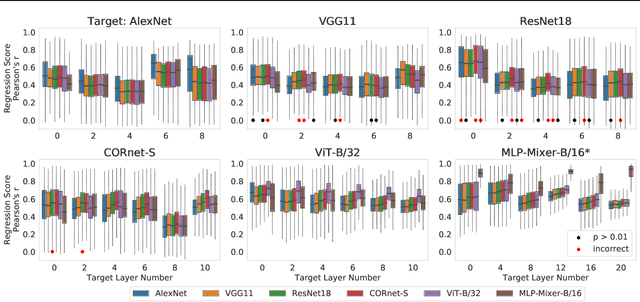
Artificial neural networks are being proposed as models of parts of the brain. The networks are compared to recordings of biological neurons, and good performance in reproducing neural responses is considered to support the model's validity. A key question is how much this system identification approach tells us about brain computation. Does it validate one model architecture over another? We evaluate the most commonly used comparison techniques, such as a linear encoding model and centered kernel alignment, to correctly identify a model by replacing brain recordings with known ground truth models. System identification performance is quite variable; it also depends significantly on factors independent of the ground truth architecture, such as stimuli images. In addition, we show the limitations of using functional similarity scores in identifying higher-level architectural motifs.