 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Policy Optimization: Training for Diversity Improves Test-Time Search
May 21, 2026Language models must now generalize out of the box to novel environments and work inside inference-scaling search procedures, such as AlphaEvolve, that select rollouts with a variety of task-specific reward functions. Unfortunately, the standard paradigm of LLM post-training optimizes a pre-specified scalar reward, often leading current LLMs to produce low-entropy response distributions and thus to struggle at displaying the diversity that inference-time search will require. We propose Vector Policy Optimization (VPO), an RL algorithm that explicitly trains policies to anticipate diverse downstream reward functions and to produce diverse solutions. VPO exploits that rewards are often vector-valued in practice, like per-test-case correctness in code generation or, say, multiple different user personas or reward models. VPO is essentially a drop-in replacement for the GRPO advantage estimator, but it trains the LLM to output a set of solutions where individual solutions specialize to different trade-offs in the vector reward space. Across four tasks, VPO matches or beats the strongest scalar RL baselines on test-time search (e.g. pass@k and best@k), with the gap widening as the search budget grows. For evolutionary search, VPO models unlock problems that GRPO models cannot solve at all. As test-time search becomes more standardized, optimizing for diversity may need to become the default post-training objective.
FlowCompile: An Optimizing Compiler for Structured LLM Workflows
May 13, 2026Structured LLM workflows, where specialized LLM sub-agents execute according to a predefined graph, have become a powerful abstraction for solving complex tasks. Optimizing such workflows, i.e., selecting configurations for each sub-agent to balance accuracy and latency, is challenging due to the combinatorial design space over model choices, reasoning budgets, and workflow structures. Existing cost-aware methods largely treat workflow optimization as a routing problem, selecting a configuration at inference time for each query according to the accuracy-latency objective used during training. We argue that structured LLM workflows can also be optimized from a compilation perspective: before deployment, the system can globally explore the workflow design space and construct a reusable set of workflow-level configurations spanning diverse accuracy-latency trade-offs. Drawing inspiration from machine learning compilers, we introduce FlowCompile, a structured LLM workflow compiler that performs compile-time design space exploration to identify a high-quality, reusable trade-off set. FlowCompile decomposes a workflow into sub-agents, profiles each sub-agent under diverse configurations, and composes these measurements through a structure-aware proxy to estimate workflow-level accuracy and latency. It then identifies diverse high-quality configurations in a single compile-time pass, without retraining or online adaptation. Experiments across diverse workflows and challenging benchmarks show that FlowCompile consistently outperforms heuristically optimized workflow configurations and routing-based baselines, delivering up to 6.4x speedup. The compiled configuration set further serves as a reusable optimization artifact, enabling flexible deployment under varying runtime preferences and supporting downstream selection or routing.
A Reward-Free Viewpoint on Multi-Objective Reinforcement Learning
Apr 27, 2026Many sequential decision-making tasks involve optimizing multiple conflicting objectives, requiring policies that adapt to different user preferences. In multi-objective reinforcement learning (MORL), one widely studied approach} addresses this by training a single policy network conditioned on preference-weighted rewards. In this paper, we explore a novel algorithmic perspective: leveraging reward-free reinforcement learning (RFRL) for MORL. While RFRL has historically been studied independently of MORL, it learns optimal policies for any possible reward function, making it a natural fit for MORL's challenge of handling unknown user preferences. We propose using the RFRL's training objective as an auxiliary task to enhance MORL, enabling more effective knowledge sharing beyond the multi-objective reward function given at training time. To this end, we adapt a state-of-the-art RFRL algorithm to the MORL setting and introduce a preference-guided exploration strategy that focuses learning on relevant parts of the environment. Through extensive experiments and ablation studies, we demonstrate that our approach significantly outperforms the state-of-the-art MORL methods across diverse MO-Gymnasium tasks, achieving superior performance and data efficiency. This work provides the first systematic adaptation of RFRL to MORL, demonstrating its potential as a scalable and empirically effective solution to multi-objective policy learning.
Decocted Experience Improves Test-Time Inference in LLM Agents
Apr 06, 2026There is growing interest in improving LLMs without updating model parameters. One well-established direction is test-time scaling, where increased inference-time computation (e.g., longer reasoning, sampling, or search) is used to improve performance. However, for complex reasoning and agentic tasks, naively scaling test-time compute can substantially increase cost and still lead to wasted budget on suboptimal exploration. In this paper, we explore \emph{context} as a complementary scaling axis for improving LLM performance, and systematically study how to construct better inputs that guide reasoning through \emph{experience}. We show that effective context construction critically depends on \emph{decocted experience}. We present a detailed analysis of experience-augmented agents, studying how to derive context from experience, how performance scales with accumulated experience, what characterizes good context, and which data structures best support context construction. We identify \emph{decocted experience} as a key mechanism for effective context construction: extracting essence from experience, organizing it coherently, and retrieving salient information to build effective context. We validate our findings across reasoning and agentic tasks, including math reasoning, web browsing, and software engineering.
Pushing Forward Pareto Frontiers of Proactive Agents with Behavioral Agentic Optimization
Feb 11, 2026Proactive large language model (LLM) agents aim to actively plan, query, and interact over multiple turns, enabling efficient task completion beyond passive instruction following and making them essential for real-world, user-centric applications. Agentic reinforcement learning (RL) has recently emerged as a promising solution for training such agents in multi-turn settings, allowing interaction strategies to be learned from feedback. However, existing pipelines face a critical challenge in balancing task performance with user engagement, as passive agents can not efficiently adapt to users' intentions while overuse of human feedback reduces their satisfaction. To address this trade-off, we propose BAO, an agentic RL framework that combines behavior enhancement to enrich proactive reasoning and information-gathering capabilities with behavior regularization to suppress inefficient or redundant interactions and align agent behavior with user expectations. We evaluate BAO on multiple tasks from the UserRL benchmark suite, and demonstrate that it substantially outperforms proactive agentic RL baselines while achieving comparable or even superior performance to commercial LLM agents, highlighting its effectiveness for training proactive, user-aligned LLM agents in complex multi-turn scenarios. Our website: https://proactive-agentic-rl.github.io/.
BOAD: Discovering Hierarchical Software Engineering Agents via Bandit Optimization
Dec 29, 2025Large language models (LLMs) have shown strong reasoning and coding capabilities, yet they struggle to generalize to real-world software engineering (SWE) problems that are long-horizon and out of distribution. Existing systems often rely on a single agent to handle the entire workflow-interpreting issues, navigating large codebases, and implementing fixes-within one reasoning chain. Such monolithic designs force the model to retain irrelevant context, leading to spurious correlations and poor generalization. Motivated by how human engineers decompose complex problems, we propose structuring SWE agents as orchestrators coordinating specialized sub-agents for sub-tasks such as localization, editing, and validation. The challenge lies in discovering effective hierarchies automatically: as the number of sub-agents grows, the search space becomes combinatorial, and it is difficult to attribute credit to individual sub-agents within a team. We address these challenges by formulating hierarchy discovery as a multi-armed bandit (MAB) problem, where each arm represents a candidate sub-agent and the reward measures its helpfulness when collaborating with others. This framework, termed Bandit Optimization for Agent Design (BOAD), enables efficient exploration of sub-agent designs under limited evaluation budgets. On SWE-bench-Verified, BOAD outperforms single-agent and manually designed multi-agent systems. On SWE-bench-Live, featuring more recent and out-of-distribution issues, our 36B system ranks second on the leaderboard at the time of evaluation, surpassing larger models such as GPT-4 and Claude. These results demonstrate that automatically discovered hierarchical multi-agent systems significantly improve generalization on challenging long-horizon SWE tasks. Code is available at https://github.com/iamxjy/BOAD-SWE-Agent.
Tailored Primitive Initialization is the Secret Key to Reinforcement Learning
Nov 16, 2025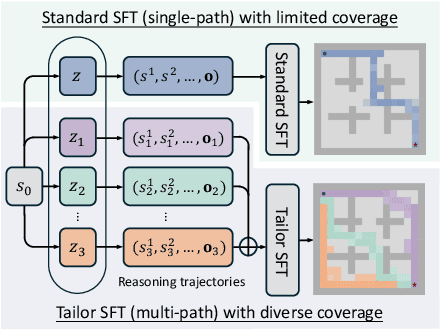

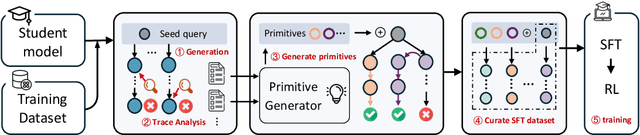
Reinforcement learning (RL) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). While RL has demonstrated substantial performance gains, it still faces key challenges, including low sampling efficiency and a strong dependence on model initialization: some models achieve rapid improvements with minimal RL steps, while others require significant training data to make progress. In this work, we investigate these challenges through the lens of reasoning token coverage and argue that initializing LLMs with diverse, high-quality reasoning primitives is essential for achieving stable and sample-efficient RL training. We propose Tailor, a finetuning pipeline that automatically discovers and curates novel reasoning primitives, thereby expanding the coverage of reasoning-state distributions before RL. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that Tailor generates more diverse and higher-quality warm-start data, resulting in higher downstream RL performance.
ReGen: Generative Robot Simulation via Inverse Design
Nov 06, 2025Simulation plays a key role in scaling robot learning and validating policies, but constructing simulations remains a labor-intensive process. This paper introduces ReGen, a generative simulation framework that automates simulation design via inverse design. Given a robot's behavior -- such as a motion trajectory or an objective function -- and its textual description, ReGen infers plausible scenarios and environments that could have caused the behavior. ReGen leverages large language models to synthesize scenarios by expanding a directed graph that encodes cause-and-effect relationships, relevant entities, and their properties. This structured graph is then translated into a symbolic program, which configures and executes a robot simulation environment. Our framework supports (i) augmenting simulations based on ego-agent behaviors, (ii) controllable, counterfactual scenario generation, (iii) reasoning about agent cognition and mental states, and (iv) reasoning with distinct sensing modalities, such as braking due to faulty GPS signals. We demonstrate ReGen in autonomous driving and robot manipulation tasks, generating more diverse, complex simulated environments compared to existing simulations with high success rates, and enabling controllable generation for corner cases. This approach enhances the validation of robot policies and supports data or simulation augmentation, advancing scalable robot learning for improved generalization and robustness. We provide code and example videos at: https://regen-sim.github.io/
Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS
Aug 19, 2025Test-time scaling (TTS) for large language models (LLMs) has thus far fallen into two largely separate paradigms: (1) reinforcement learning (RL) methods that optimize sparse outcome-based rewards, yet suffer from instability and low sample efficiency; and (2) search-based techniques guided by independently trained, static process reward models (PRMs), which require expensive human- or LLM-generated labels and often degrade under distribution shifts. In this paper, we introduce AIRL-S, the first natural unification of RL-based and search-based TTS. Central to AIRL-S is the insight that the reward function learned during RL training inherently represents the ideal PRM for guiding downstream search. Specifically, we leverage adversarial inverse reinforcement learning (AIRL) combined with group relative policy optimization (GRPO) to learn a dense, dynamic PRM directly from correct reasoning traces, entirely eliminating the need for labeled intermediate process data. At inference, the resulting PRM simultaneously serves as the critic for RL rollouts and as a heuristic to effectively guide search procedures, facilitating robust reasoning chain extension, mitigating reward hacking, and enhancing cross-task generalization. Experimental results across eight benchmarks, including mathematics, scientific reasoning, and code generation, demonstrate that our unified approach improves performance by 9 % on average over the base model, matching GPT-4o. Furthermore, when integrated into multiple search algorithms, our PRM consistently outperforms all baseline PRMs trained with labeled data. These results underscore that, indeed, your reward function for RL is your best PRM for search, providing a robust and cost-effective solution to complex reasoning tasks in LLMs.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025
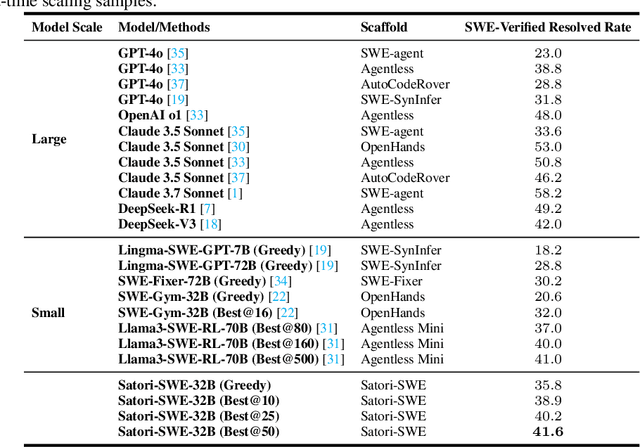
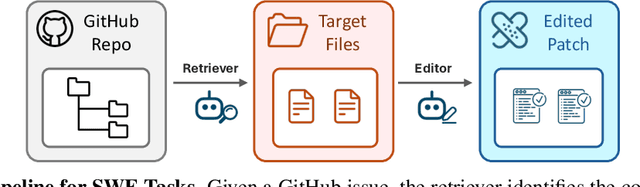

Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.