 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Less, Drive Better: Generalizable End-to-End Autonomous Driving via Foundation Models Stochastic Patch Selection
Jan 15, 2026Recent advances in end-to-end autonomous driving show that policies trained on patch-aligned features extracted from foundation models generalize better to Out-of-Distribution (OOD). We hypothesize that due to the self-attention mechanism, each patch feature implicitly embeds/contains information from all other patches, represented in a different way and intensity, making these descriptors highly redundant. We quantify redundancy in such (BLIP2) features via PCA and cross-patch similarity: $90$% of variance is captured by $17/64$ principal components, and strong inter-token correlations are pervasive. Training on such overlapping information leads the policy to overfit spurious correlations, hurting OOD robustness. We present Stochastic-Patch-Selection (SPS), a simple yet effective approach for learning policies that are more robust, generalizable, and efficient. For every frame, SPS randomly masks a fraction of patch descriptors, not feeding them to the policy model, while preserving the spatial layout of the remaining patches. Thus, the policy is provided with different stochastic but complete views of the (same) scene: every random subset of patches acts like a different, yet still sensible, coherent projection of the world. The policy thus bases its decisions on features that are invariant to which specific tokens survive. Extensive experiments confirm that across all OOD scenarios, our method outperforms the state of the art (SOTA), achieving a $6.2$% average improvement and up to $20.4$% in closed-loop simulations, while being $2.4\times$ faster. We conduct ablations over masking rates and patch-feature reorganization, training and evaluating 9 systems, with 8 of them surpassing prior SOTA. Finally, we show that the same learned policy transfers to a physical, real-world car without any tuning.
ReGen: Generative Robot Simulation via Inverse Design
Nov 06, 2025Simulation plays a key role in scaling robot learning and validating policies, but constructing simulations remains a labor-intensive process. This paper introduces ReGen, a generative simulation framework that automates simulation design via inverse design. Given a robot's behavior -- such as a motion trajectory or an objective function -- and its textual description, ReGen infers plausible scenarios and environments that could have caused the behavior. ReGen leverages large language models to synthesize scenarios by expanding a directed graph that encodes cause-and-effect relationships, relevant entities, and their properties. This structured graph is then translated into a symbolic program, which configures and executes a robot simulation environment. Our framework supports (i) augmenting simulations based on ego-agent behaviors, (ii) controllable, counterfactual scenario generation, (iii) reasoning about agent cognition and mental states, and (iv) reasoning with distinct sensing modalities, such as braking due to faulty GPS signals. We demonstrate ReGen in autonomous driving and robot manipulation tasks, generating more diverse, complex simulated environments compared to existing simulations with high success rates, and enabling controllable generation for corner cases. This approach enhances the validation of robot policies and supports data or simulation augmentation, advancing scalable robot learning for improved generalization and robustness. We provide code and example videos at: https://regen-sim.github.io/
Holistic Surgical Phase Recognition with Hierarchical Input Dependent State Space Models
Jun 26, 2025Surgical workflow analysis is essential in robot-assisted surgeries, yet the long duration of such procedures poses significant challenges for comprehensive video analysis. Recent approaches have predominantly relied on transformer models; however, their quadratic attention mechanism restricts efficient processing of lengthy surgical videos. In this paper, we propose a novel hierarchical input-dependent state space model that leverages the linear scaling property of state space models to enable decision making on full-length videos while capturing both local and global dynamics. Our framework incorporates a temporally consistent visual feature extractor, which appends a state space model head to a visual feature extractor to propagate temporal information. The proposed model consists of two key modules: a local-aggregation state space model block that effectively captures intricate local dynamics, and a global-relation state space model block that models temporal dependencies across the entire video. The model is trained using a hybrid discrete-continuous supervision strategy, where both signals of discrete phase labels and continuous phase progresses are propagated through the network. Experiments have shown that our method outperforms the current state-of-the-art methods by a large margin (+2.8% on Cholec80, +4.3% on MICCAI2016, and +12.9% on Heichole datasets). Code will be publicly available after paper acceptance.
RobotSmith: Generative Robotic Tool Design for Acquisition of Complex Manipulation Skills
Jun 17, 2025



Endowing robots with tool design abilities is critical for enabling them to solve complex manipulation tasks that would otherwise be intractable. While recent generative frameworks can automatically synthesize task settings, such as 3D scenes and reward functions, they have not yet addressed the challenge of tool-use scenarios. Simply retrieving human-designed tools might not be ideal since many tools (e.g., a rolling pin) are difficult for robotic manipulators to handle. Furthermore, existing tool design approaches either rely on predefined templates with limited parameter tuning or apply generic 3D generation methods that are not optimized for tool creation. To address these limitations, we propose RobotSmith, an automated pipeline that leverages the implicit physical knowledge embedded in vision-language models (VLMs) alongside the more accurate physics provided by physics simulations to design and use tools for robotic manipulation. Our system (1) iteratively proposes tool designs using collaborative VLM agents, (2) generates low-level robot trajectories for tool use, and (3) jointly optimizes tool geometry and usage for task performance. We evaluate our approach across a wide range of manipulation tasks involving rigid, deformable, and fluid objects. Experiments show that our method consistently outperforms strong baselines in terms of both task success rate and overall performance. Notably, our approach achieves a 50.0\% average success rate, significantly surpassing other baselines such as 3D generation (21.4%) and tool retrieval (11.1%). Finally, we deploy our system in real-world settings, demonstrating that the generated tools and their usage plans transfer effectively to physical execution, validating the practicality and generalization capabilities of our approach.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025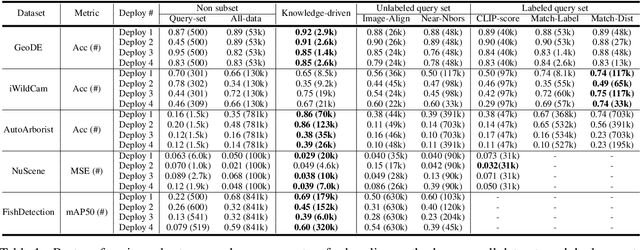
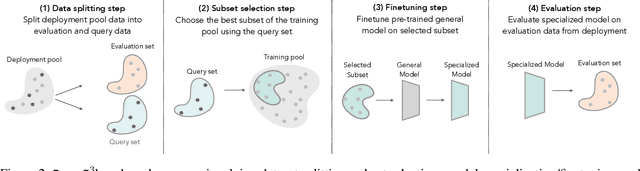
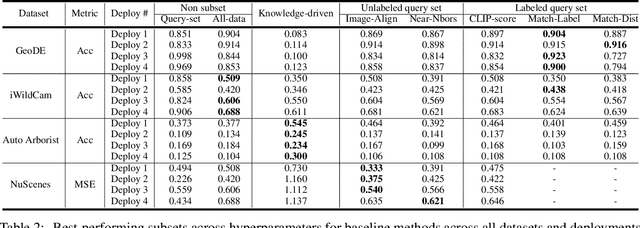
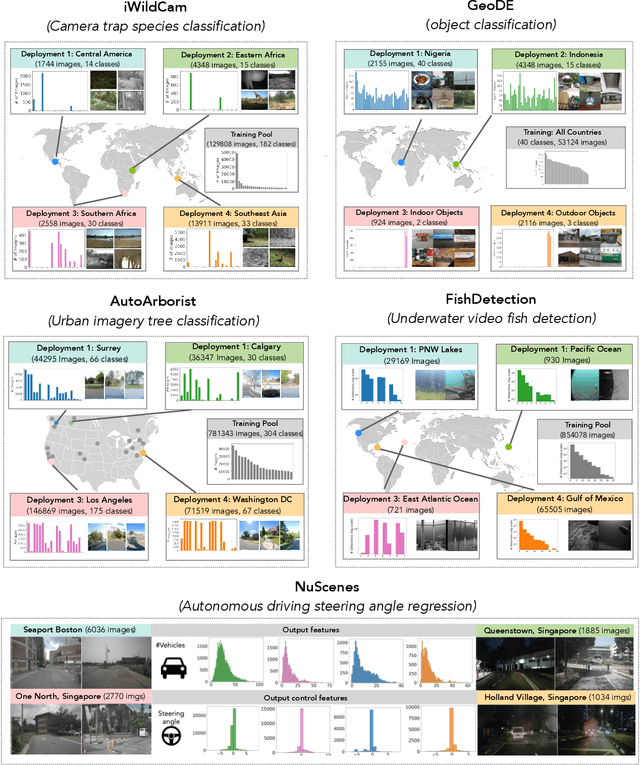
In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
LuciBot: Automated Robot Policy Learning from Generated Videos
Mar 12, 2025Automatically generating training supervision for embodied tasks is crucial, as manual designing is tedious and not scalable. While prior works use large language models (LLMs) or vision-language models (VLMs) to generate rewards, these approaches are largely limited to simple tasks with well-defined rewards, such as pick-and-place. This limitation arises because LLMs struggle to interpret complex scenes compressed into text or code due to their restricted input modality, while VLM-based rewards, though better at visual perception, remain limited by their less expressive output modality. To address these challenges, we leverage the imagination capability of general-purpose video generation models. Given an initial simulation frame and a textual task description, the video generation model produces a video demonstrating task completion with correct semantics. We then extract rich supervisory signals from the generated video, including 6D object pose sequences, 2D segmentations, and estimated depth, to facilitate task learning in simulation. Our approach significantly improves supervision quality for complex embodied tasks, enabling large-scale training in simulators.
Articulate AnyMesh: Open-Vocabulary 3D Articulated Objects Modeling
Feb 04, 2025



3D articulated objects modeling has long been a challenging problem, since it requires to capture both accurate surface geometries and semantically meaningful and spatially precise structures, parts, and joints. Existing methods heavily depend on training data from a limited set of handcrafted articulated object categories (e.g., cabinets and drawers), which restricts their ability to model a wide range of articulated objects in an open-vocabulary context. To address these limitations, we propose Articulate Anymesh, an automated framework that is able to convert any rigid 3D mesh into its articulated counterpart in an open-vocabulary manner. Given a 3D mesh, our framework utilizes advanced Vision-Language Models and visual prompting techniques to extract semantic information, allowing for both the segmentation of object parts and the construction of functional joints. Our experiments show that Articulate Anymesh can generate large-scale, high-quality 3D articulated objects, including tools, toys, mechanical devices, and vehicles, significantly expanding the coverage of existing 3D articulated object datasets. Additionally, we show that these generated assets can facilitate the acquisition of new articulated object manipulation skills in simulation, which can then be transferred to a real robotic system. Our Github website is https://articulate-anymesh.github.io.
Embodied Red Teaming for Auditing Robotic Foundation Models
Nov 27, 2024

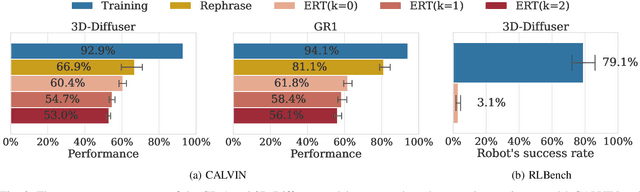
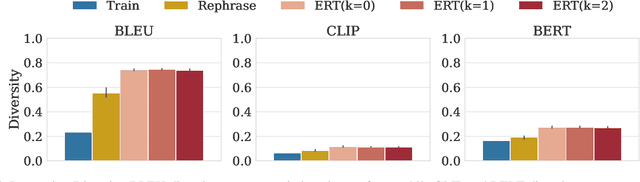
Language-conditioned robot models (i.e., robotic foundation models) enable robots to perform a wide range of tasks based on natural language instructions. Despite strong performance on existing benchmarks, evaluating the safety and effectiveness of these models is challenging due to the complexity of testing all possible language variations. Current benchmarks have two key limitations: they rely on a limited set of human-generated instructions, missing many challenging cases, and they focus only on task performance without assessing safety, such as avoiding damage. To address these gaps, we introduce Embodied Red Teaming (ERT), a new evaluation method that generates diverse and challenging instructions to test these models. ERT uses automated red teaming techniques with Vision Language Models (VLMs) to create contextually grounded, difficult instructions. Experimental results show that state-of-the-art models frequently fail or behave unsafely on ERT tests, underscoring the shortcomings of current benchmarks in evaluating real-world performance and safety. Code and videos are available at: https://sites.google.com/view/embodiedredteam.
UBSoft: A Simulation Platform for Robotic Skill Learning in Unbounded Soft Environments
Nov 19, 2024It is desired to equip robots with the capability of interacting with various soft materials as they are ubiquitous in the real world. While physics simulations are one of the predominant methods for data collection and robot training, simulating soft materials presents considerable challenges. Specifically, it is significantly more costly than simulating rigid objects in terms of simulation speed and storage requirements. These limitations typically restrict the scope of studies on soft materials to small and bounded areas, thereby hindering the learning of skills in broader spaces. To address this issue, we introduce UBSoft, a new simulation platform designed to support unbounded soft environments for robot skill acquisition. Our platform utilizes spatially adaptive resolution scales, where simulation resolution dynamically adjusts based on proximity to active robotic agents. Our framework markedly reduces the demand for extensive storage space and computation costs required for large-scale scenarios involving soft materials. We also establish a set of benchmark tasks in our platform, including both locomotion and manipulation tasks, and conduct experiments to evaluate the efficacy of various reinforcement learning algorithms and trajectory optimization techniques, both gradient-based and sampling-based. Preliminary results indicate that sampling-based trajectory optimization generally achieves better results for obtaining one trajectory to solve the task. Additionally, we conduct experiments in real-world environments to demonstrate that advancements made in our UBSoft simulator could translate to improved robot interactions with large-scale soft material. More videos can be found at https://vis-www.cs.umass.edu/ubsoft/.
Architect: Generating Vivid and Interactive 3D Scenes with Hierarchical 2D Inpainting
Nov 14, 2024

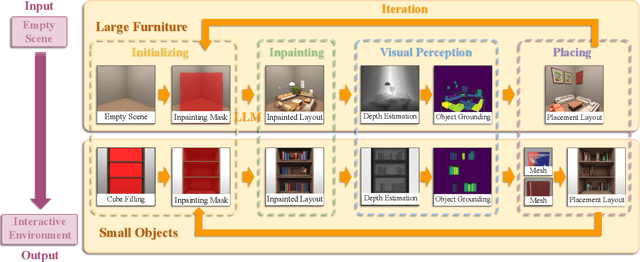
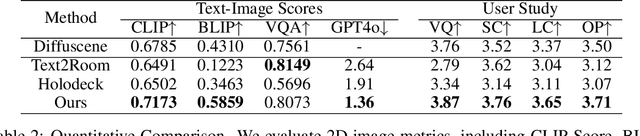
Creating large-scale interactive 3D environments is essential for the development of Robotics and Embodied AI research. Current methods, including manual design, procedural generation, diffusion-based scene generation, and large language model (LLM) guided scene design, are hindered by limitations such as excessive human effort, reliance on predefined rules or training datasets, and limited 3D spatial reasoning ability. Since pre-trained 2D image generative models better capture scene and object configuration than LLMs, we address these challenges by introducing Architect, a generative framework that creates complex and realistic 3D embodied environments leveraging diffusion-based 2D image inpainting. In detail, we utilize foundation visual perception models to obtain each generated object from the image and leverage pre-trained depth estimation models to lift the generated 2D image to 3D space. Our pipeline is further extended to a hierarchical and iterative inpainting process to continuously generate placement of large furniture and small objects to enrich the scene. This iterative structure brings the flexibility for our method to generate or refine scenes from various starting points, such as text, floor plans, or pre-arranged environments.