 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAI Gym for Science: Training Liquid Foundation Models for Drug Discovery
Mar 03, 2026General-purpose large language models (LLMs) that rely on in-context learning do not reliably deliver the scientific understanding and performance required for drug discovery tasks. Simply increasing model size or introducing reasoning tokens does not yield significant performance gains. To address this gap, we introduce the MMAI Gym for Science, a one-stop shop molecular data formats and modalities as well as task-specific reasoning, training, and benchmarking recipes designed to teach foundation models the 'language of molecules' in order to solve practical drug discovery problems. We use MMAI Gym to train an efficient Liquid Foundation Model (LFM) for these applications, demonstrating that smaller, purpose-trained foundation models can outperform substantially larger general-purpose or specialist models on molecular benchmarks. Across essential drug discovery tasks - including molecular optimization, ADMET property prediction, retrosynthesis, drug-target activity prediction, and functional group reasoning - the resulting model achieves near specialist-level performance and, in the majority of settings, surpasses larger models, while remaining more efficient and broadly applicable in the domain.
Online Fine-Tuning of Pretrained Controllers for Autonomous Driving via Real-Time Recurrent RL
Feb 03, 2026Deploying pretrained policies in real-world applications presents substantial challenges that fundamentally limit the practical applicability of learning-based control systems. When autonomous systems encounter environmental changes in system dynamics, sensor drift, or task objectives, fixed policies rapidly degrade in performance. We show that employing Real-Time Recurrent Reinforcement Learning (RTRRL), a biologically plausible algorithm for online adaptation, can effectively fine-tune a pretrained policy to improve autonomous agents' performance on driving tasks. We further show that RTRRL synergizes with a recent biologically inspired recurrent network model, the Liquid-Resistance Liquid-Capacitance RNN. We demonstrate the effectiveness of this closed-loop approach in a simulated CarRacing environment and in a real-world line-following task with a RoboRacer car equipped with an event camera.
Holistic Surgical Phase Recognition with Hierarchical Input Dependent State Space Models
Jun 26, 2025Surgical workflow analysis is essential in robot-assisted surgeries, yet the long duration of such procedures poses significant challenges for comprehensive video analysis. Recent approaches have predominantly relied on transformer models; however, their quadratic attention mechanism restricts efficient processing of lengthy surgical videos. In this paper, we propose a novel hierarchical input-dependent state space model that leverages the linear scaling property of state space models to enable decision making on full-length videos while capturing both local and global dynamics. Our framework incorporates a temporally consistent visual feature extractor, which appends a state space model head to a visual feature extractor to propagate temporal information. The proposed model consists of two key modules: a local-aggregation state space model block that effectively captures intricate local dynamics, and a global-relation state space model block that models temporal dependencies across the entire video. The model is trained using a hybrid discrete-continuous supervision strategy, where both signals of discrete phase labels and continuous phase progresses are propagated through the network. Experiments have shown that our method outperforms the current state-of-the-art methods by a large margin (+2.8% on Cholec80, +4.3% on MICCAI2016, and +12.9% on Heichole datasets). Code will be publicly available after paper acceptance.
Scaling Up Liquid-Resistance Liquid-Capacitance Networks for Efficient Sequence Modeling
May 29, 2025We present LrcSSM, a $\textit{nonlinear}$ recurrent model that processes long sequences as fast as today's linear state-space layers. By forcing the state-transition matrix to be diagonal and learned at every step, the full sequence can be solved in parallel with a single prefix-scan, giving $\mathcal{O}(TD)$ time and memory and only $\mathcal{O}(\log T)$ sequential depth, for input-sequence length $T$ and a state dimension $D$. Moreover, LrcSSM offers a formal gradient-stability guarantee that other input-varying systems such as Liquid-S4 and Mamba do not provide. Lastly, for network depth $L$, as the forward and backward passes cost $\Theta(T\,D\,L)$ FLOPs, with its low sequential depth and parameter count $\Theta(D\,L)$, the model follows the compute-optimal scaling law regime ($\beta \approx 0.42$) recently observed for Mamba, outperforming quadratic-attention Transformers at equal compute while avoiding the memory overhead of FFT-based long convolutions. We show that on a series of long-range forecasting tasks, LrcSSM outperforms LRU, S5 and Mamba.
Enhancing Steering Estimation with Semantic-Aware GNNs
Mar 21, 2025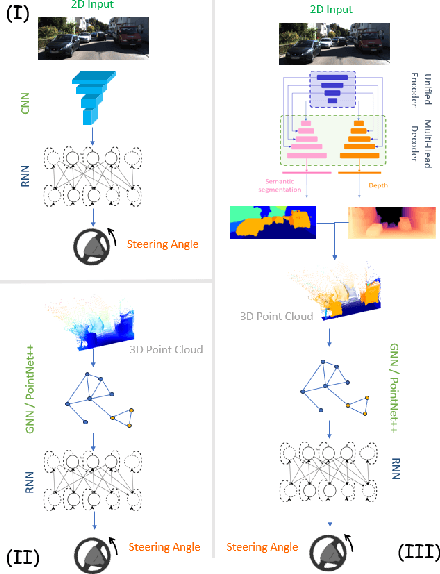
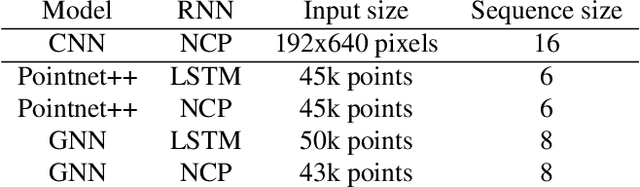

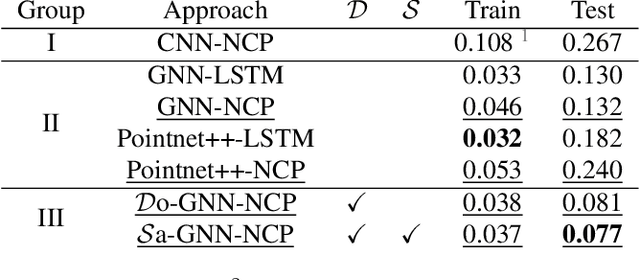
Steering estimation is a critical task in autonomous driving, traditionally relying on 2D image-based models. In this work, we explore the advantages of incorporating 3D spatial information through hybrid architectures that combine 3D neural network models with recurrent neural networks (RNNs) for temporal modeling, using LiDAR-based point clouds as input. We systematically evaluate four hybrid 3D models, all of which outperform the 2D-only baseline, with the Graph Neural Network (GNN) - RNN model yielding the best results. To reduce reliance on LiDAR, we leverage a pretrained unified model to estimate depth from monocular images, reconstructing pseudo-3D point clouds. We then adapt the GNN-RNN model, originally designed for LiDAR-based point clouds, to work with these pseudo-3D representations, achieving comparable or even superior performance compared to the LiDAR-based model. Additionally, the unified model provides semantic labels for each point, enabling a more structured scene representation. To further optimize graph construction, we introduce an efficient connectivity strategy where connections are predominantly formed between points of the same semantic class, with only 20\% of inter-class connections retained. This targeted approach reduces graph complexity and computational cost while preserving critical spatial relationships. Finally, we validate our approach on the KITTI dataset, achieving a 71% improvement over 2D-only models. Our findings highlight the advantages of 3D spatial information and efficient graph construction for steering estimation, while maintaining the cost-effectiveness of monocular images and avoiding the expense of LiDAR-based systems.
Human Insights Driven Latent Space for Different Driving Perspectives: A Unified Encoder for Efficient Multi-Task Inference
Sep 16, 2024



Autonomous driving holds great potential to transform road safety and traffic efficiency by minimizing human error and reducing congestion. A key challenge in realizing this potential is the accurate estimation of steering angles, which is essential for effective vehicle navigation and control. Recent breakthroughs in deep learning have made it possible to estimate steering angles directly from raw camera inputs. However, the limited available navigation data can hinder optimal feature learning, impacting the system's performance in complex driving scenarios. In this paper, we propose a shared encoder trained on multiple computer vision tasks critical for urban navigation, such as depth, pose, and 3D scene flow estimation, as well as semantic, instance, panoptic, and motion segmentation. By incorporating diverse visual information used by humans during navigation, this unified encoder might enhance steering angle estimation. To achieve effective multi-task learning within a single encoder, we introduce a multi-scale feature network for pose estimation to improve depth learning. Additionally, we employ knowledge distillation from a multi-backbone model pretrained on these navigation tasks to stabilize training and boost performance. Our findings demonstrate that a shared backbone trained on diverse visual tasks is capable of providing overall perception capabilities. While our performance in steering angle estimation is comparable to existing methods, the integration of human-like perception through multi-task learning holds significant potential for advancing autonomous driving systems. More details and the pretrained model are available at https://hi-computervision.github.io/uni-encoder/.
Gaussian Splatting to Real World Flight Navigation Transfer with Liquid Networks
Jun 21, 2024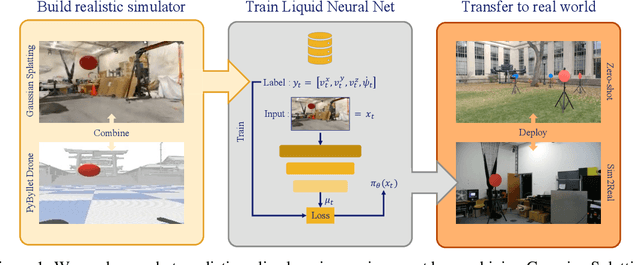



Simulators are powerful tools for autonomous robot learning as they offer scalable data generation, flexible design, and optimization of trajectories. However, transferring behavior learned from simulation data into the real world proves to be difficult, usually mitigated with compute-heavy domain randomization methods or further model fine-tuning. We present a method to improve generalization and robustness to distribution shifts in sim-to-real visual quadrotor navigation tasks. To this end, we first build a simulator by integrating Gaussian Splatting with quadrotor flight dynamics, and then, train robust navigation policies using Liquid neural networks. In this way, we obtain a full-stack imitation learning protocol that combines advances in 3D Gaussian splatting radiance field rendering, crafty programming of expert demonstration training data, and the task understanding capabilities of Liquid networks. Through a series of quantitative flight tests, we demonstrate the robust transfer of navigation skills learned in a single simulation scene directly to the real world. We further show the ability to maintain performance beyond the training environment under drastic distribution and physical environment changes. Our learned Liquid policies, trained on single target manoeuvres curated from a photorealistic simulated indoor flight only, generalize to multi-step hikes onboard a real hardware platform outdoors.
State-Free Inference of State-Space Models: The Transfer Function Approach
May 10, 2024We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm that is state-free: unlike other proposed algorithms, state-free inference does not incur any significant memory or computational cost with an increase in state size. We achieve this using properties of the proposed frequency domain transfer function parametrization, which enables direct computation of its corresponding convolutional kernel's spectrum via a single Fast Fourier Transform. Our experimental results across multiple sequence lengths and state sizes illustrates, on average, a 35% training speed improvement over S4 layers -- parametrized in time-domain -- on the Long Range Arena benchmark, while delivering state-of-the-art downstream performances over other attention-free approaches. Moreover, we report improved perplexity in language modeling over a long convolutional Hyena baseline, by simply introducing our transfer function parametrization. Our code is available at https://github.com/ruke1ire/RTF.
Exploring Latent Pathways: Enhancing the Interpretability of Autonomous Driving with a Variational Autoencoder
Apr 02, 2024Autonomous driving presents a complex challenge, which is usually addressed with artificial intelligence models that are end-to-end or modular in nature. Within the landscape of modular approaches, a bio-inspired neural circuit policy model has emerged as an innovative control module, offering a compact and inherently interpretable system to infer a steering wheel command from abstract visual features. Here, we take a leap forward by integrating a variational autoencoder with the neural circuit policy controller, forming a solution that directly generates steering commands from input camera images. By substituting the traditional convolutional neural network approach to feature extraction with a variational autoencoder, we enhance the system's interpretability, enabling a more transparent and understandable decision-making process. In addition to the architectural shift toward a variational autoencoder, this study introduces the automatic latent perturbation tool, a novel contribution designed to probe and elucidate the latent features within the variational autoencoder. The automatic latent perturbation tool automates the interpretability process, offering granular insights into how specific latent variables influence the overall model's behavior. Through a series of numerical experiments, we demonstrate the interpretative power of the variational autoencoder-neural circuit policy model and the utility of the automatic latent perturbation tool in making the inner workings of autonomous driving systems more transparent.
Leveraging Low-Rank and Sparse Recurrent Connectivity for Robust Closed-Loop Control
Oct 05, 2023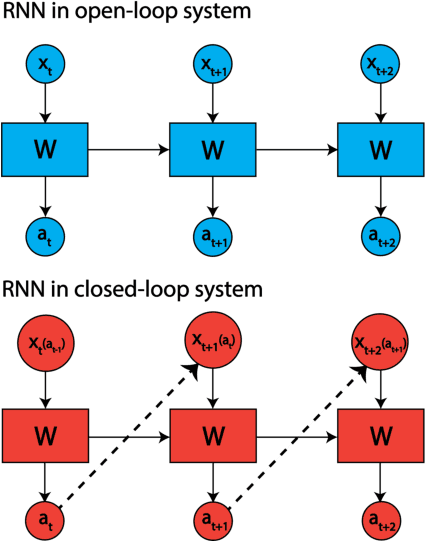

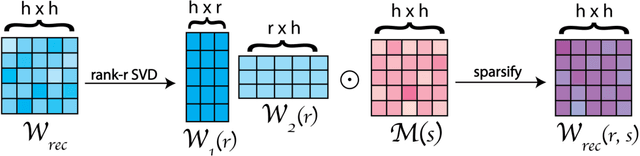

Developing autonomous agents that can interact with changing environments is an open challenge in machine learning. Robustness is particularly important in these settings as agents are often fit offline on expert demonstrations but deployed online where they must generalize to the closed feedback loop within the environment. In this work, we explore the application of recurrent neural networks to tasks of this nature and understand how a parameterization of their recurrent connectivity influences robustness in closed-loop settings. Specifically, we represent the recurrent connectivity as a function of rank and sparsity and show both theoretically and empirically that modulating these two variables has desirable effects on network dynamics. The proposed low-rank, sparse connectivity induces an interpretable prior on the network that proves to be most amenable for a class of models known as closed-form continuous-time neural networks (CfCs). We find that CfCs with fewer parameters can outperform their full-rank, fully-connected counterparts in the online setting under distribution shift. This yields memory-efficient and robust agents while opening a new perspective on how we can modulate network dynamics through connectivity.