 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRS-CWC: A Weakly Constrained Multi-Robot System with Controllable Constraint Stiffness for Mobility and Navigation in Unknown 3D Rough Environments
Mar 14, 2025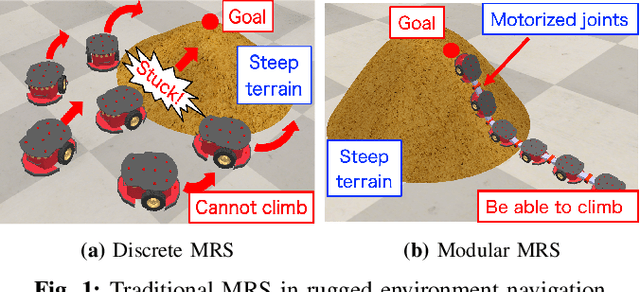
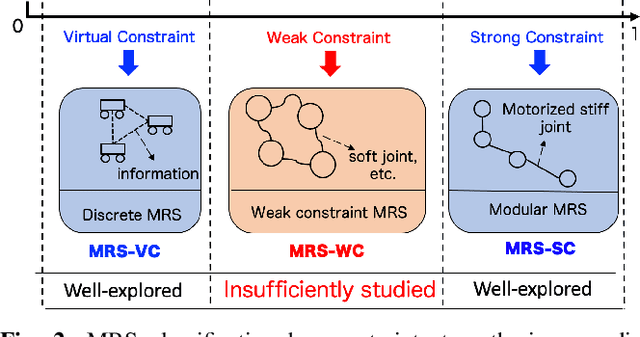
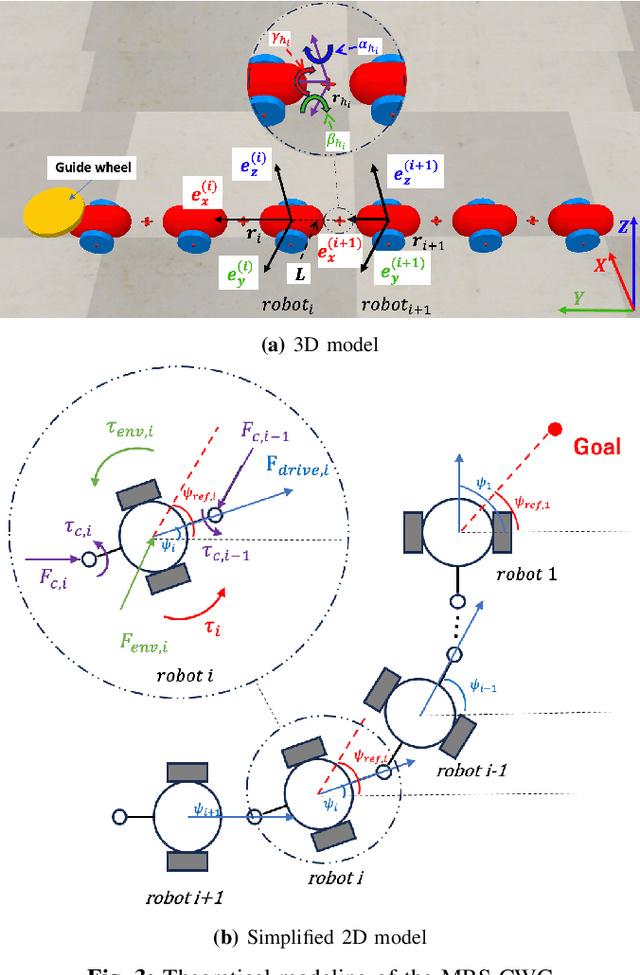
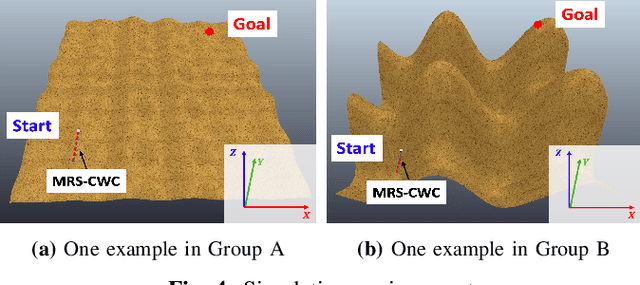
Navigating unknown three-dimensional (3D) rugged environments is challenging for multi-robot systems. Traditional discrete systems struggle with rough terrain due to limited individual mobility, while modular systems--where rigid, controllable constraints link robot units--improve traversal but suffer from high control complexity and reduced flexibility. To address these limitations, we propose the Multi-Robot System with Controllable Weak Constraints (MRS-CWC), where robot units are connected by constraints with dynamically adjustable stiffness. This adaptive mechanism softens or stiffens in real-time during environmental interactions, ensuring a balance between flexibility and mobility. We formulate the system's dynamics and control model and evaluate MRS-CWC against six baseline methods and an ablation variant in a benchmark dataset with 100 different simulation terrains. Results show that MRS-CWC achieves the highest navigation completion rate and ranks second in success rate, efficiency, and energy cost in the highly rugged terrain group, outperforming all baseline methods without relying on environmental modeling, path planning, or complex control. Even where MRS-CWC ranks second, its performance is only slightly behind a more complex ablation variant with environmental modeling and path planning. Finally, we develop a physical prototype and validate its feasibility in a constructed rugged environment. For videos, simulation benchmarks, and code, please visit https://wyd0817.github.io/project-mrs-cwc/.
DART-LLM: Dependency-Aware Multi-Robot Task Decomposition and Execution using Large Language Models
Nov 13, 2024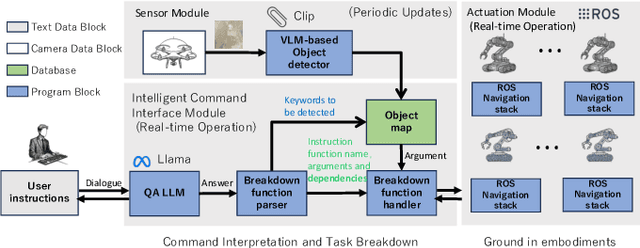
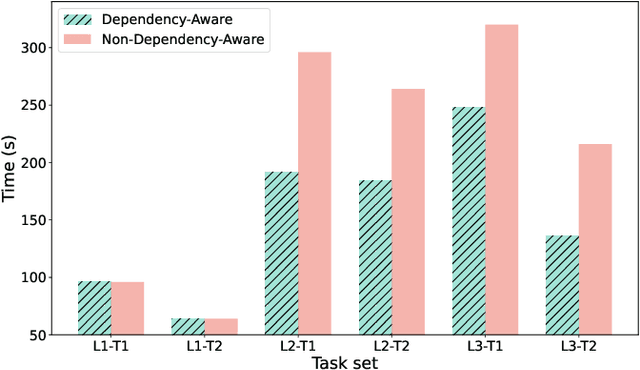
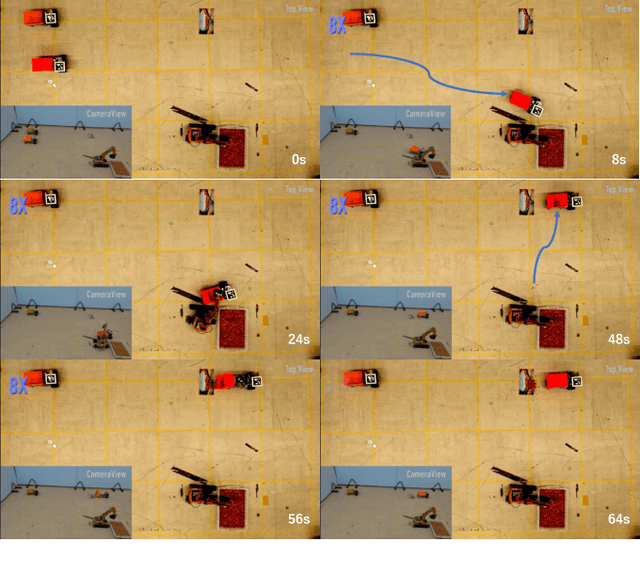
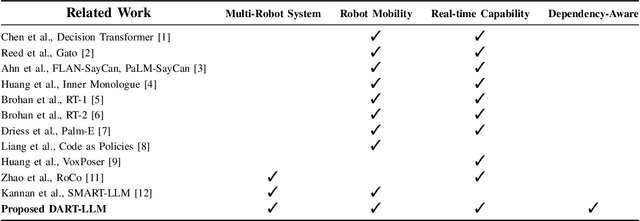
Large Language Models (LLMs) have demonstrated significant reasoning capabilities in robotic systems. However, their deployment in multi-robot systems remains fragmented and struggles to handle complex task dependencies and parallel execution. This study introduces the DART-LLM (Dependency-Aware Multi-Robot Task Decomposition and Execution using Large Language Models) system, designed to address these challenges. DART-LLM utilizes LLMs to parse natural language instructions, decomposing them into multiple subtasks with dependencies to establish complex task sequences, thereby enhancing efficient coordination and parallel execution in multi-robot systems. The system includes the QA LLM module, Breakdown Function modules, Actuation module, and a Vision-Language Model (VLM)-based object detection module, enabling task decomposition and execution from natural language instructions to robotic actions. Experimental results demonstrate that DART-LLM excels in handling long-horizon tasks and collaborative tasks with complex dependencies. Even when using smaller models like Llama 3.1 8B, the system achieves good performance, highlighting DART-LLM's robustness in terms of model size. Please refer to the project website \url{https://wyd0817.github.io/project-dart-llm/} for videos and code.
State-Free Inference of State-Space Models: The Transfer Function Approach
May 10, 2024We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm that is state-free: unlike other proposed algorithms, state-free inference does not incur any significant memory or computational cost with an increase in state size. We achieve this using properties of the proposed frequency domain transfer function parametrization, which enables direct computation of its corresponding convolutional kernel's spectrum via a single Fast Fourier Transform. Our experimental results across multiple sequence lengths and state sizes illustrates, on average, a 35% training speed improvement over S4 layers -- parametrized in time-domain -- on the Long Range Arena benchmark, while delivering state-of-the-art downstream performances over other attention-free approaches. Moreover, we report improved perplexity in language modeling over a long convolutional Hyena baseline, by simply introducing our transfer function parametrization. Our code is available at https://github.com/ruke1ire/RTF.
Motion Degeneracy in Self-supervised Learning of Elevation Angle Estimation for 2D Forward-Looking Sonar
Aug 01, 2023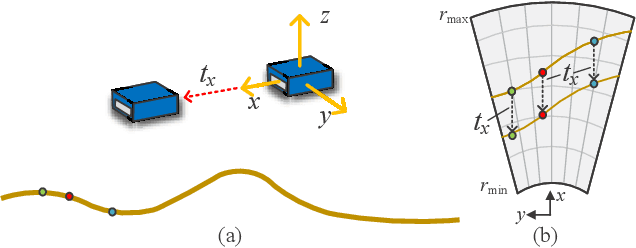
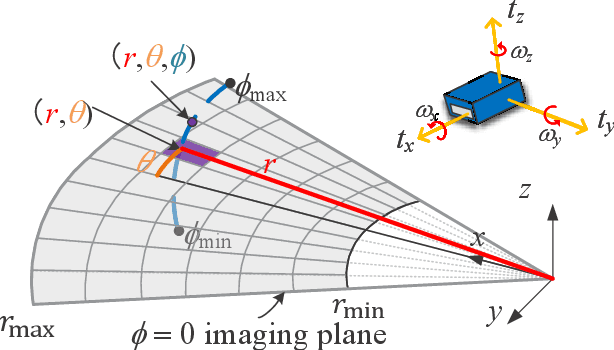
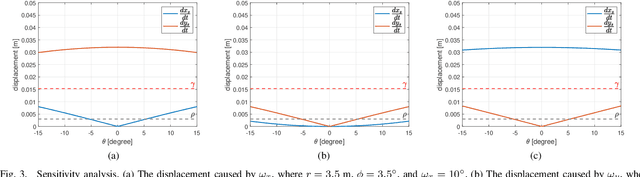
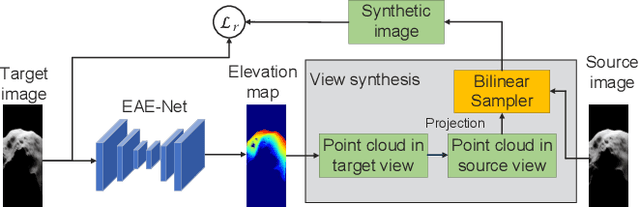
2D forward-looking sonar is a crucial sensor for underwater robotic perception. A well-known problem in this field is estimating missing information in the elevation direction during sonar imaging. There are demands to estimate 3D information per image for 3D mapping and robot navigation during fly-through missions. Recent learning-based methods have demonstrated their strengths, but there are still drawbacks. Supervised learning methods have achieved high-quality results but may require further efforts to acquire 3D ground-truth labels. The existing self-supervised method requires pretraining using synthetic images with 3D supervision. This study aims to realize stable self-supervised learning of elevation angle estimation without pretraining using synthetic images. Failures during self-supervised learning may be caused by motion degeneracy problems. We first analyze the motion field of 2D forward-looking sonar, which is related to the main supervision signal. We utilize a modern learning framework and prove that if the training dataset is built with effective motions, the network can be trained in a self-supervised manner without the knowledge of synthetic data. Both simulation and real experiments validate the proposed method.
2D Forward Looking Sonar Simulation with Ground Echo Modeling
Apr 17, 2023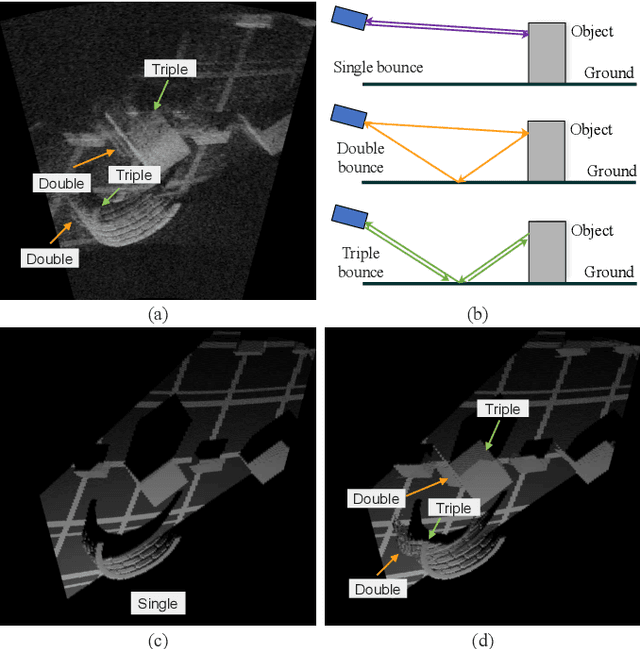

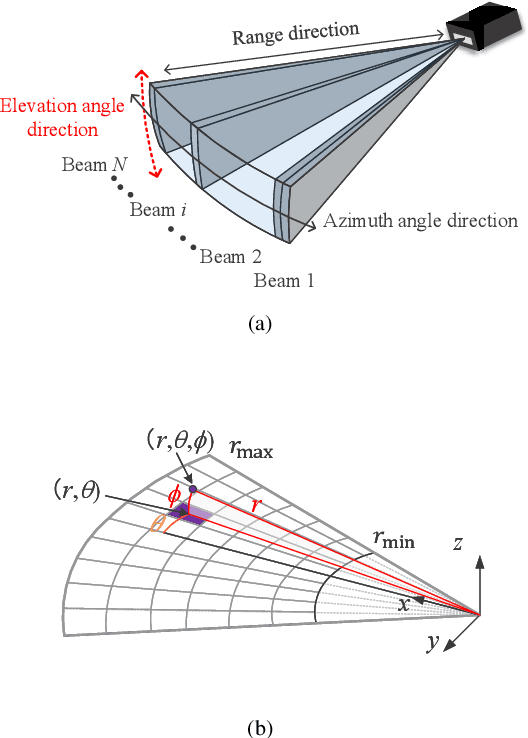
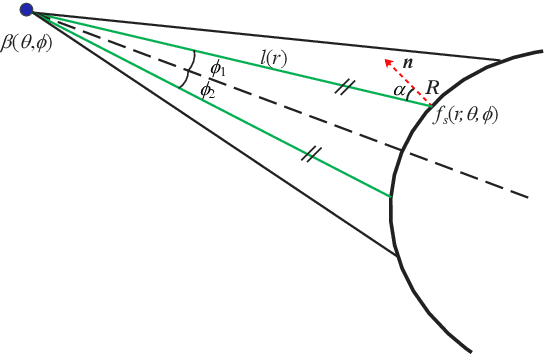
Imaging sonar produces clear images in underwater environments, independent of water turbidity and lighting conditions. The next generation 2D forward looking sonars are compact in size and able to generate high-resolution images which facilitate underwater robotics research. Considering the difficulties and expenses of implementing experiments in underwater environments, tremendous work has been focused on sonar image simulation. However, sonar artifacts like multi-path reflection were not sufficiently discussed, which cannot be ignored in water tank environments. In this paper, we focus on the influence of echoes from the flat ground. We propose a method to simulate the ground echo effect physically in acoustic images. We model the multi-bounce situations using the single-bounce framework for computation efficiency. We compare the real image captured in the water tank with the synthetic images to validate the proposed methods.
Learning Pseudo Front Depth for 2D Forward-Looking Sonar-based Multi-view Stereo
Jul 30, 2022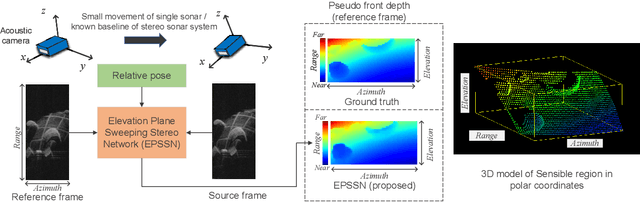
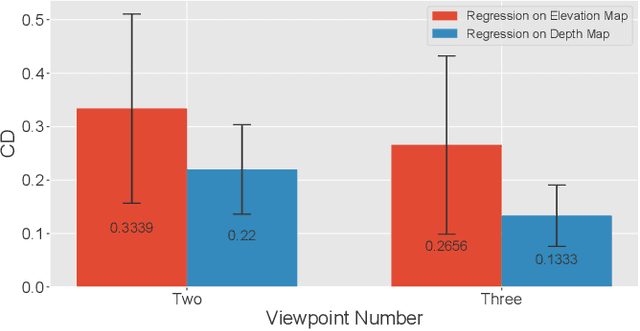
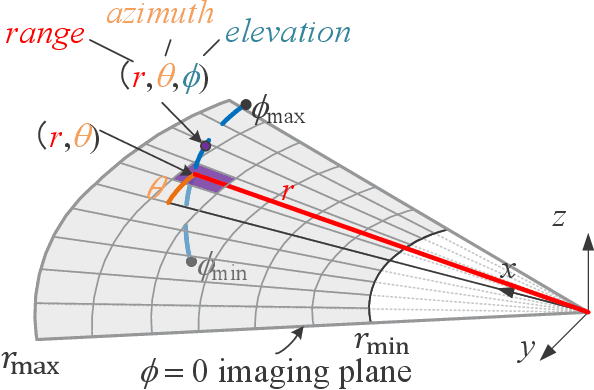
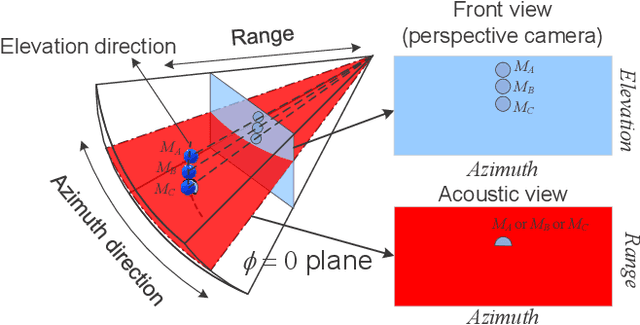
Retrieving the missing dimension information in acoustic images from 2D forward-looking sonar is a well-known problem in the field of underwater robotics. There are works attempting to retrieve 3D information from a single image which allows the robot to generate 3D maps with fly-through motion. However, owing to the unique image formulation principle, estimating 3D information from a single image faces severe ambiguity problems. Classical methods of multi-view stereo can avoid the ambiguity problems, but may require a large number of viewpoints to generate an accurate model. In this work, we propose a novel learning-based multi-view stereo method to estimate 3D information. To better utilize the information from multiple frames, an elevation plane sweeping method is proposed to generate the depth-azimuth-elevation cost volume. The volume after regularization can be considered as a probabilistic volumetric representation of the target. Instead of performing regression on the elevation angles, we use pseudo front depth from the cost volume to represent the 3D information which can avoid the 2D-3D problem in acoustic imaging. High-accuracy results can be generated with only two or three images. Synthetic datasets were generated to simulate various underwater targets. We also built the first real dataset with accurate ground truth in a large scale water tank. Experimental results demonstrate the superiority of our method, compared to other state-of-the-art methods.
Continuous-Depth Neural Models for Dynamic Graph Prediction
Jun 22, 2021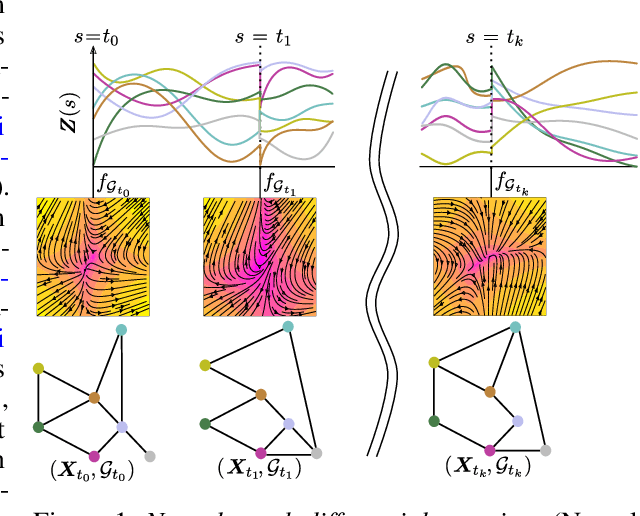

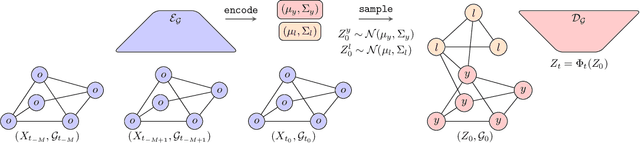
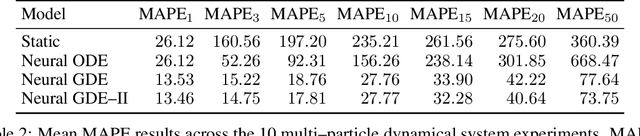
We introduce the framework of continuous-depth graph neural networks (GNNs). Neural graph differential equations (Neural GDEs) are formalized as the counterpart to GNNs where the input-output relationship is determined by a continuum of GNN layers, blending discrete topological structures and differential equations. The proposed framework is shown to be compatible with static GNN models and is extended to dynamic and stochastic settings through hybrid dynamical system theory. Here, Neural GDEs improve performance by exploiting the underlying dynamics geometry, further introducing the ability to accommodate irregularly sampled data. Results prove the effectiveness of the proposed models across applications, such as traffic forecasting or prediction in genetic regulatory networks.
Neural Hybrid Automata: Learning Dynamics with Multiple Modes and Stochastic Transitions
Jun 08, 2021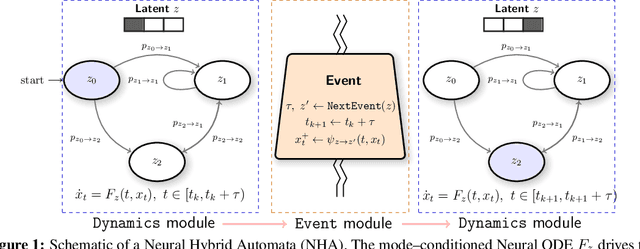
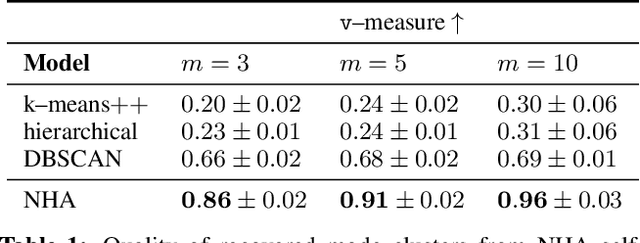
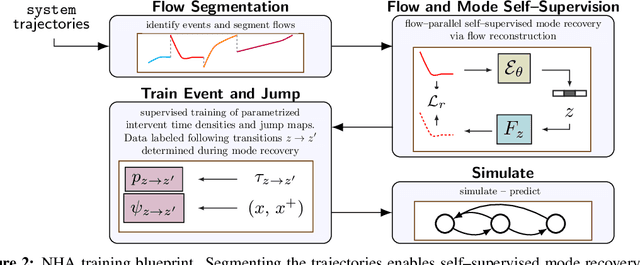
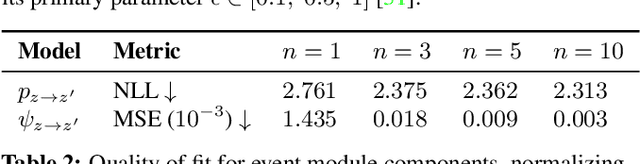
Effective control and prediction of dynamical systems often require appropriate handling of continuous-time and discrete, event-triggered processes. Stochastic hybrid systems (SHSs), common across engineering domains, provide a formalism for dynamical systems subject to discrete, possibly stochastic, state jumps and multi-modal continuous-time flows. Despite the versatility and importance of SHSs across applications, a general procedure for the explicit learning of both discrete events and multi-mode continuous dynamics remains an open problem. This work introduces Neural Hybrid Automata (NHAs), a recipe for learning SHS dynamics without a priori knowledge on the number of modes and inter-modal transition dynamics. NHAs provide a systematic inference method based on normalizing flows, neural differential equations and self-supervision. We showcase NHAs on several tasks, including mode recovery and flow learning in systems with stochastic transitions, and end-to-end learning of hierarchical robot controllers.
Differentiable Multiple Shooting Layers
Jun 07, 2021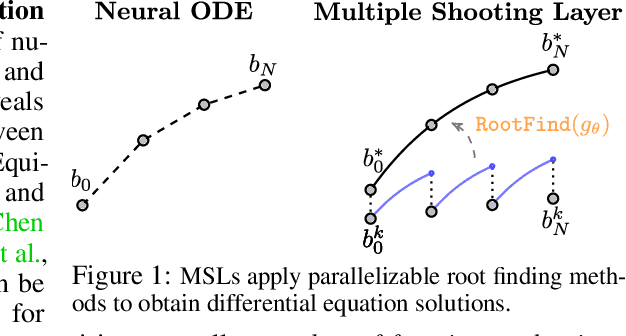
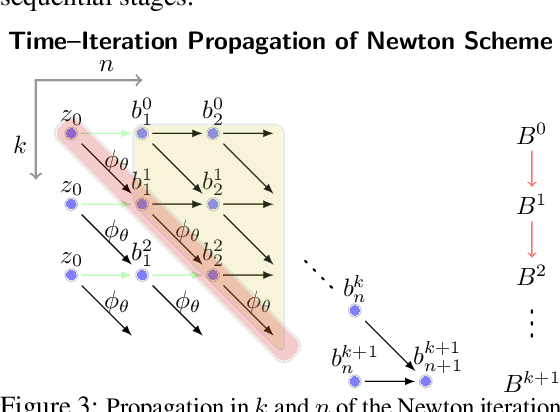
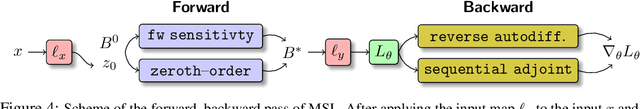

We detail a novel class of implicit neural models. Leveraging time-parallel methods for differential equations, Multiple Shooting Layers (MSLs) seek solutions of initial value problems via parallelizable root-finding algorithms. MSLs broadly serve as drop-in replacements for neural ordinary differential equations (Neural ODEs) with improved efficiency in number of function evaluations (NFEs) and wall-clock inference time. We develop the algorithmic framework of MSLs, analyzing the different choices of solution methods from a theoretical and computational perspective. MSLs are showcased in long horizon optimal control of ODEs and PDEs and as latent models for sequence generation. Finally, we investigate the speedups obtained through application of MSL inference in neural controlled differential equations (Neural CDEs) for time series classification of medical data.
Learning Stochastic Optimal Policies via Gradient Descent
Jun 07, 2021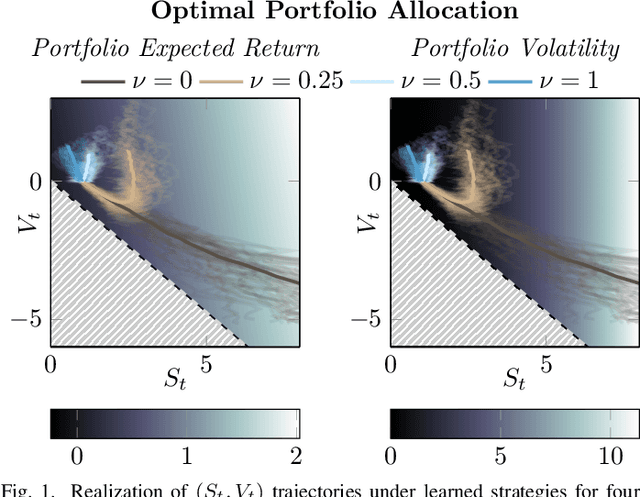
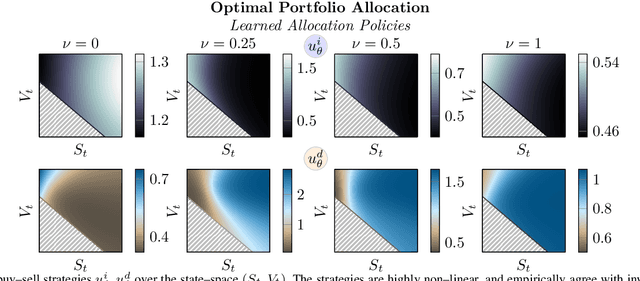
We systematically develop a learning-based treatment of stochastic optimal control (SOC), relying on direct optimization of parametric control policies. We propose a derivation of adjoint sensitivity results for stochastic differential equations through direct application of variational calculus. Then, given an objective function for a predetermined task specifying the desiderata for the controller, we optimize their parameters via iterative gradient descent methods. In doing so, we extend the range of applicability of classical SOC techniques, often requiring strict assumptions on the functional form of system and control. We verify the performance of the proposed approach on a continuous-time, finite horizon portfolio optimization with proportional transaction costs.