 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Height Estimation Using a Single Acoustic Camera for Compensation in 2D Seabed Mosaicking
Nov 19, 2024



This letter proposes a novel approach for compensating target height data in 2D seabed mosaicking for low-visibility underwater perception. Acoustic cameras are effective sensors for sensing the marine environments due to their high-resolution imaging capabilities and robustness to darkness and turbidity. However, the loss of elevation angle during the imaging process results in a lack of target height information in the original acoustic camera images, leading to a simplistic 2D representation of the seabed mosaicking. In perceiving cluttered and unexplored marine environments, target height data is crucial for avoiding collisions with marine robots. This study proposes a novel approach for estimating seabed target height using a single acoustic camera and integrates height data into 2D seabed mosaicking to compensate for the missing 3D dimension of seabed targets. Unlike classic methods that model the loss of elevation angle to achieve seabed 3D reconstruction, this study focuses on utilizing available acoustic cast shadow clues and simple sensor motion to quickly estimate target height. The feasibility of our proposal is verified through a water tank experiment and a simulation experiment.
HR-INR: Continuous Space-Time Video Super-Resolution via Event Camera
May 22, 2024Continuous space-time video super-resolution (C-STVSR) aims to simultaneously enhance video resolution and frame rate at an arbitrary scale. Recently, implicit neural representation (INR) has been applied to video restoration, representing videos as implicit fields that can be decoded at an arbitrary scale. However, the highly ill-posed nature of C-STVSR limits the effectiveness of current INR-based methods: they assume linear motion between frames and use interpolation or feature warping to generate features at arbitrary spatiotemporal positions with two consecutive frames. This restrains C-STVSR from capturing rapid and nonlinear motion and long-term dependencies (involving more than two frames) in complex dynamic scenes. In this paper, we propose a novel C-STVSR framework, called HR-INR, which captures both holistic dependencies and regional motions based on INR. It is assisted by an event camera, a novel sensor renowned for its high temporal resolution and low latency. To fully utilize the rich temporal information from events, we design a feature extraction consisting of (1) a regional event feature extractor - taking events as inputs via the proposed event temporal pyramid representation to capture the regional nonlinear motion and (2) a holistic event-frame feature extractor for long-term dependence and continuity motion. We then propose a novel INR-based decoder with spatiotemporal embeddings to capture long-term dependencies with a larger temporal perception field. We validate the effectiveness and generalization of our method on four datasets (both simulated and real data), showing the superiority of our method.
Four years of multi-modal odometry and mapping on the rail vehicles
Aug 22, 2023Precise, seamless, and efficient train localization as well as long-term railway environment monitoring is the essential property towards reliability, availability, maintainability, and safety (RAMS) engineering for railroad systems. Simultaneous localization and mapping (SLAM) is right at the core of solving the two problems concurrently. In this end, we propose a high-performance and versatile multi-modal framework in this paper, targeted for the odometry and mapping task for various rail vehicles. Our system is built atop an inertial-centric state estimator that tightly couples light detection and ranging (LiDAR), visual, optionally satellite navigation and map-based localization information with the convenience and extendibility of loosely coupled methods. The inertial sensors IMU and wheel encoder are treated as the primary sensor, which achieves the observations from subsystems to constrain the accelerometer and gyroscope biases. Compared to point-only LiDAR-inertial methods, our approach leverages more geometry information by introducing both track plane and electric power pillars into state estimation. The Visual-inertial subsystem also utilizes the environmental structure information by employing both lines and points. Besides, the method is capable of handling sensor failures by automatic reconfiguration bypassing failure modules. Our proposed method has been extensively tested in the long-during railway environments over four years, including general-speed, high-speed and metro, both passenger and freight traffic are investigated. Further, we aim to share, in an open way, the experience, problems, and successes of our group with the robotics community so that those that work in such environments can avoid these errors. In this view, we open source some of the datasets to benefit the research community.
A LiDAR-Inertial SLAM Tightly-Coupled with Dropout-Tolerant GNSS Fusion for Autonomous Mine Service Vehicles
Aug 22, 2023Multi-modal sensor integration has become a crucial prerequisite for the real-world navigation systems. Recent studies have reported successful deployment of such system in many fields. However, it is still challenging for navigation tasks in mine scenes due to satellite signal dropouts, degraded perception, and observation degeneracy. To solve this problem, we propose a LiDAR-inertial odometry method in this paper, utilizing both Kalman filter and graph optimization. The front-end consists of multiple parallel running LiDAR-inertial odometries, where the laser points, IMU, and wheel odometer information are tightly fused in an error-state Kalman filter. Instead of the commonly used feature points, we employ surface elements for registration. The back-end construct a pose graph and jointly optimize the pose estimation results from inertial, LiDAR odometry, and global navigation satellite system (GNSS). Since the vehicle has a long operation time inside the tunnel, the largely accumulated drift may be not fully by the GNSS measurements. We hereby leverage a loop closure based re-initialization process to achieve full alignment. In addition, the system robustness is improved through handling data loss, stream consistency, and estimation error. The experimental results show that our system has a good tolerance to the long-period degeneracy with the cooperation different LiDARs and surfel registration, achieving meter-level accuracy even for tens of minutes running during GNSS dropouts.
Motion Degeneracy in Self-supervised Learning of Elevation Angle Estimation for 2D Forward-Looking Sonar
Aug 01, 2023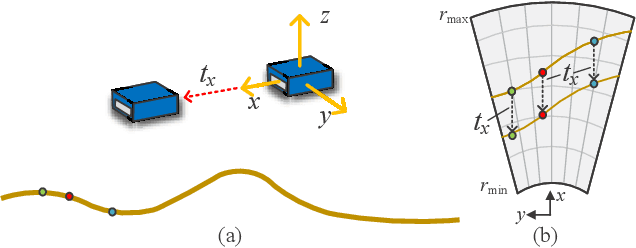
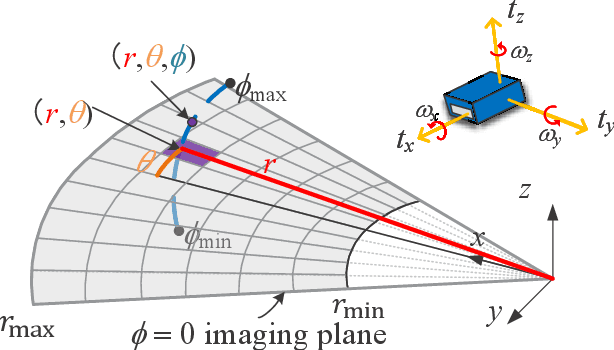
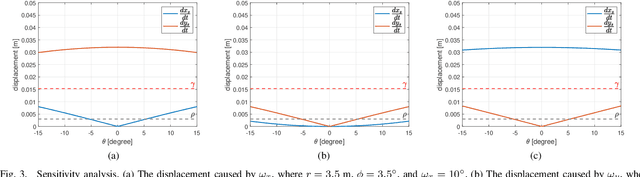
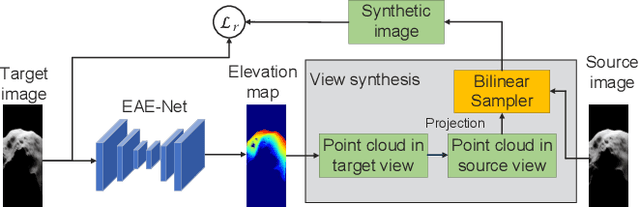
2D forward-looking sonar is a crucial sensor for underwater robotic perception. A well-known problem in this field is estimating missing information in the elevation direction during sonar imaging. There are demands to estimate 3D information per image for 3D mapping and robot navigation during fly-through missions. Recent learning-based methods have demonstrated their strengths, but there are still drawbacks. Supervised learning methods have achieved high-quality results but may require further efforts to acquire 3D ground-truth labels. The existing self-supervised method requires pretraining using synthetic images with 3D supervision. This study aims to realize stable self-supervised learning of elevation angle estimation without pretraining using synthetic images. Failures during self-supervised learning may be caused by motion degeneracy problems. We first analyze the motion field of 2D forward-looking sonar, which is related to the main supervision signal. We utilize a modern learning framework and prove that if the training dataset is built with effective motions, the network can be trained in a self-supervised manner without the knowledge of synthetic data. Both simulation and real experiments validate the proposed method.
2D Forward Looking Sonar Simulation with Ground Echo Modeling
Apr 17, 2023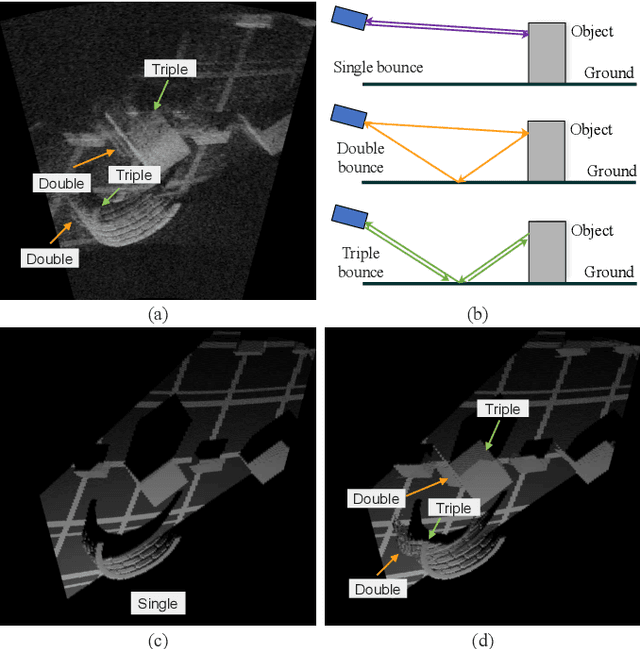

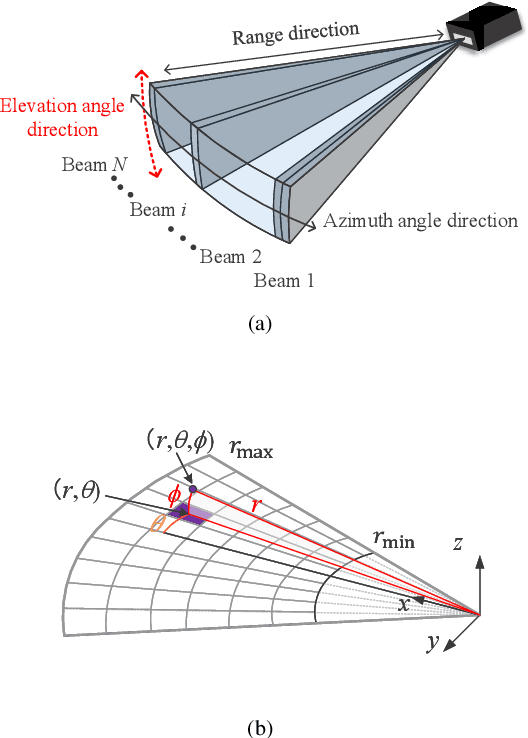
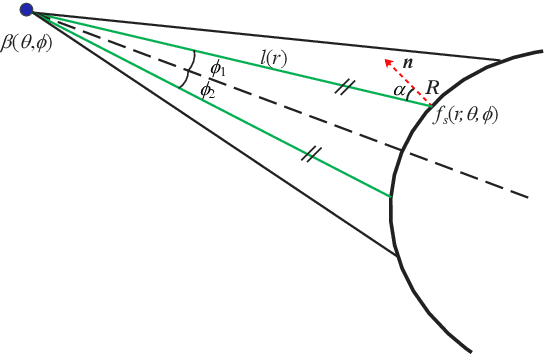
Imaging sonar produces clear images in underwater environments, independent of water turbidity and lighting conditions. The next generation 2D forward looking sonars are compact in size and able to generate high-resolution images which facilitate underwater robotics research. Considering the difficulties and expenses of implementing experiments in underwater environments, tremendous work has been focused on sonar image simulation. However, sonar artifacts like multi-path reflection were not sufficiently discussed, which cannot be ignored in water tank environments. In this paper, we focus on the influence of echoes from the flat ground. We propose a method to simulate the ground echo effect physically in acoustic images. We model the multi-bounce situations using the single-bounce framework for computation efficiency. We compare the real image captured in the water tank with the synthetic images to validate the proposed methods.
Learning Pseudo Front Depth for 2D Forward-Looking Sonar-based Multi-view Stereo
Jul 30, 2022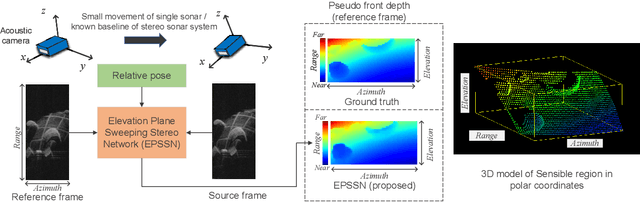
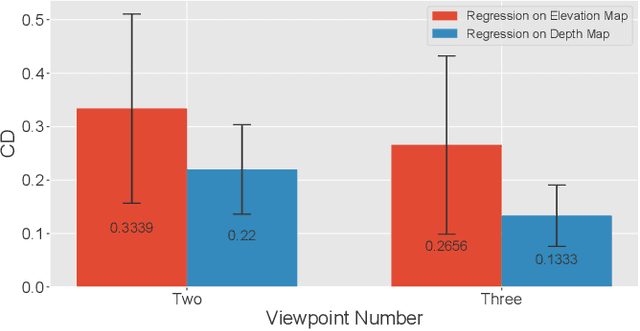
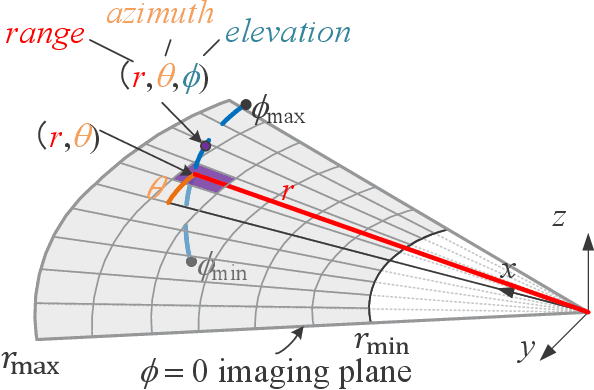
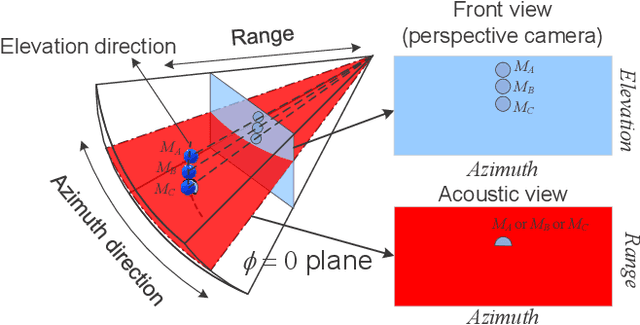
Retrieving the missing dimension information in acoustic images from 2D forward-looking sonar is a well-known problem in the field of underwater robotics. There are works attempting to retrieve 3D information from a single image which allows the robot to generate 3D maps with fly-through motion. However, owing to the unique image formulation principle, estimating 3D information from a single image faces severe ambiguity problems. Classical methods of multi-view stereo can avoid the ambiguity problems, but may require a large number of viewpoints to generate an accurate model. In this work, we propose a novel learning-based multi-view stereo method to estimate 3D information. To better utilize the information from multiple frames, an elevation plane sweeping method is proposed to generate the depth-azimuth-elevation cost volume. The volume after regularization can be considered as a probabilistic volumetric representation of the target. Instead of performing regression on the elevation angles, we use pseudo front depth from the cost volume to represent the 3D information which can avoid the 2D-3D problem in acoustic imaging. High-accuracy results can be generated with only two or three images. Synthetic datasets were generated to simulate various underwater targets. We also built the first real dataset with accurate ground truth in a large scale water tank. Experimental results demonstrate the superiority of our method, compared to other state-of-the-art methods.
Efficient Video Deblurring Guided by Motion Magnitude
Jul 27, 2022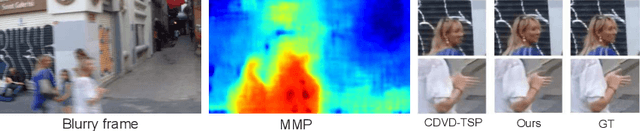


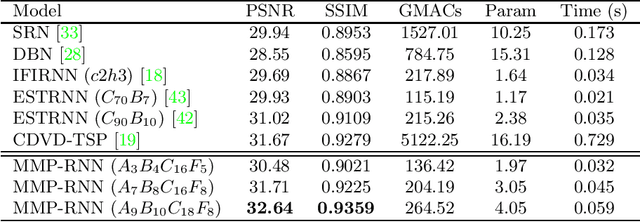
Video deblurring is a highly under-constrained problem due to the spatially and temporally varying blur. An intuitive approach for video deblurring includes two steps: a) detecting the blurry region in the current frame; b) utilizing the information from clear regions in adjacent frames for current frame deblurring. To realize this process, our idea is to detect the pixel-wise blur level of each frame and combine it with video deblurring. To this end, we propose a novel framework that utilizes the motion magnitude prior (MMP) as guidance for efficient deep video deblurring. Specifically, as the pixel movement along its trajectory during the exposure time is positively correlated to the level of motion blur, we first use the average magnitude of optical flow from the high-frequency sharp frames to generate the synthetic blurry frames and their corresponding pixel-wise motion magnitude maps. We then build a dataset including the blurry frame and MMP pairs. The MMP is then learned by a compact CNN by regression. The MMP consists of both spatial and temporal blur level information, which can be further integrated into an efficient recurrent neural network (RNN) for video deblurring. We conduct intensive experiments to validate the effectiveness of the proposed methods on the public datasets.
Simultaneous Location of Rail Vehicles and Mapping of Environment with Multiple LiDARs
Dec 25, 2021

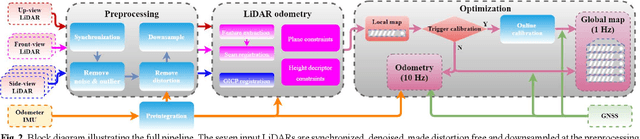
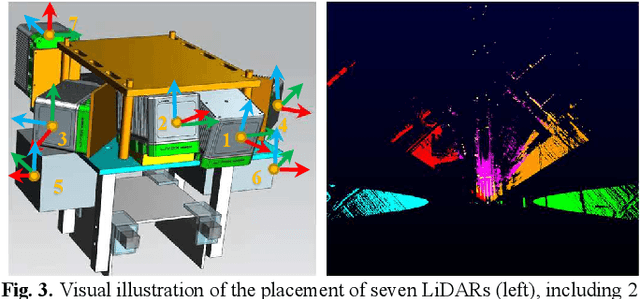
Precise and real-time rail vehicle localization as well as railway environment monitoring is crucial for railroad safety. In this letter, we propose a multi-LiDAR based simultaneous localization and mapping (SLAM) system for railway applications. Our approach starts with measurements preprocessing to denoise and synchronize multiple LiDAR inputs. Different frame-to-frame registration methods are used according to the LiDAR placement. In addition, we leverage the plane constraints from extracted rail tracks to improve the system accuracy. The local map is further aligned with global map utilizing absolute position measurements. Considering the unavoidable metal abrasion and screw loosening, online extrinsic refinement is awakened for long-during operation. The proposed method is extensively verified on datasets gathered over 3000 km. The results demonstrate that the proposed system achieves accurate and robust localization together with effective mapping for large-scale environments. Our system has already been applied to a freight traffic railroad for monitoring tasks.
Rail Vehicle Localization and Mapping with LiDAR-Vision-Inertial-GNSS Fusion
Dec 16, 2021
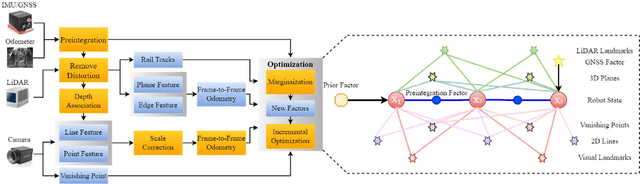
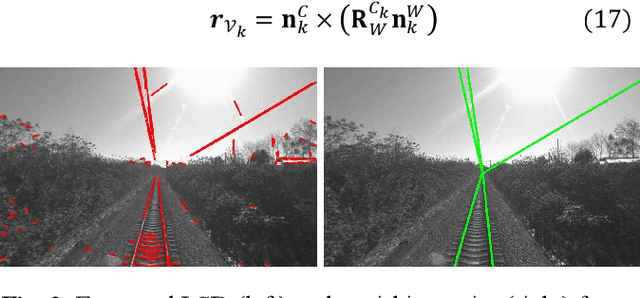

In this paper, we present a global navigation satellite system (GNSS) aided LiDAR-visual-inertial scheme, RailLoMer-V, for accurate and robust rail vehicle localization and mapping. RailLoMer-V is formulated atop a factor graph and consists of two subsystems: an odometer assisted LiDAR-inertial system (OLIS) and an odometer integrated Visual-inertial system (OVIS). Both the subsystem exploits the typical geometry structure on the railroads. The plane constraints from extracted rail tracks are used to complement the rotation and vertical errors in OLIS. Besides, the line features and vanishing points are leveraged to constrain rotation drifts in OVIS. The proposed framework is extensively evaluated on datasets over 800 km, gathered for more than a year on both general-speed and high-speed railways, day and night. Taking advantage of the tightly-coupled integration of all measurements from individual sensors, our framework is accurate to long-during tasks and robust enough to grievously degenerated scenarios (railway tunnels). In addition, the real-time performance can be achieved with an onboard computer.