 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeroGS: Hierarchical Guidance for Robust 3D Gaussian Splatting under Sparse Views
Mar 03, 20263D Gaussian Splatting (3DGS) has recently emerged as a promising approach in novel view synthesis, combining photorealistic rendering with real-time efficiency. However, its success heavily relies on dense camera coverage; under sparse-view conditions, insufficient supervision leads to irregular Gaussian distributions, characterized by globally sparse coverage, blurred background, and distorted high-frequency areas. To address this, we propose HeroGS, Hierarchical Guidance for Robust 3D Gaussian Splatting, a unified framework that establishes hierarchical guidance across the image, feature, and parameter levels. At the image level, sparse supervision is converted into pseudo-dense guidance, globally regularizing the Gaussian distributions and forming a consistent foundation for subsequent optimization. Building upon this, Feature-Adaptive Densification and Pruning (FADP) at the feature level leverages low-level features to refine high-frequency details and adaptively densifies Gaussians in background regions. The optimized distributions then support Co-Pruned Geometry Consistency (CPG) at parameter level, which guides geometric consistency through parameter freezing and co-pruning, effectively removing inconsistent splats. The hierarchical guidance strategy effectively constrains and optimizes the overall Gaussian distributions, thereby enhancing both structural fidelity and rendering quality. Extensive experiments demonstrate that HeroGS achieves high-fidelity reconstructions and consistently surpasses state-of-the-art baselines under sparse-view conditions.
Fuzzy Reasoning Chain (FRC): An Innovative Reasoning Framework from Fuzziness to Clarity
Sep 26, 2025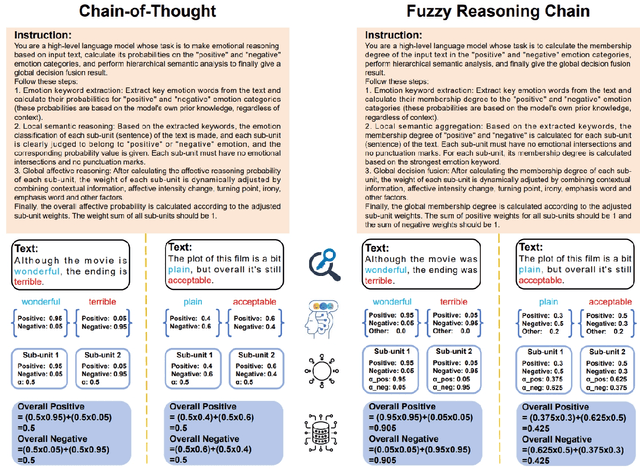
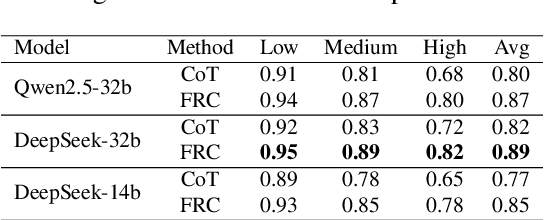
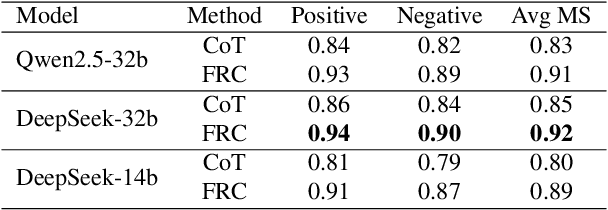
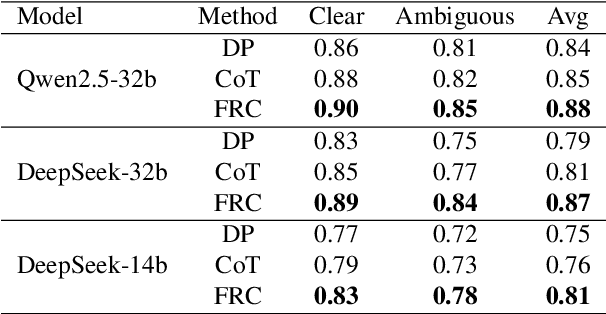
With the rapid advancement of large language models (LLMs), natural language processing (NLP) has achieved remarkable progress. Nonetheless, significant challenges remain in handling texts with ambiguity, polysemy, or uncertainty. We introduce the Fuzzy Reasoning Chain (FRC) framework, which integrates LLM semantic priors with continuous fuzzy membership degrees, creating an explicit interaction between probability-based reasoning and fuzzy membership reasoning. This transition allows ambiguous inputs to be gradually transformed into clear and interpretable decisions while capturing conflicting or uncertain signals that traditional probability-based methods cannot. We validate FRC on sentiment analysis tasks, where both theoretical analysis and empirical results show that it ensures stable reasoning and facilitates knowledge transfer across different model scales. These findings indicate that FRC provides a general mechanism for managing subtle and ambiguous expressions with improved interpretability and robustness.
GaGA: Towards Interactive Global Geolocation Assistant
Dec 12, 2024



Global geolocation, which seeks to predict the geographical location of images captured anywhere in the world, is one of the most challenging tasks in the field of computer vision. In this paper, we introduce an innovative interactive global geolocation assistant named GaGA, built upon the flourishing large vision-language models (LVLMs). GaGA uncovers geographical clues within images and combines them with the extensive world knowledge embedded in LVLMs to determine the geolocations while also providing justifications and explanations for the prediction results. We further designed a novel interactive geolocation method that surpasses traditional static inference approaches. It allows users to intervene, correct, or provide clues for the predictions, making the model more flexible and practical. The development of GaGA relies on the newly proposed Multi-modal Global Geolocation (MG-Geo) dataset, a comprehensive collection of 5 million high-quality image-text pairs. GaGA achieves state-of-the-art performance on the GWS15k dataset, improving accuracy by 4.57% at the country level and 2.92% at the city level, setting a new benchmark. These advancements represent a significant leap forward in developing highly accurate, interactive geolocation systems with global applicability.
ViMoE: An Empirical Study of Designing Vision Mixture-of-Experts
Oct 21, 2024



Mixture-of-Experts (MoE) models embody the divide-and-conquer concept and are a promising approach for increasing model capacity, demonstrating excellent scalability across multiple domains. In this paper, we integrate the MoE structure into the classic Vision Transformer (ViT), naming it ViMoE, and explore the potential of applying MoE to vision through a comprehensive study on image classification. However, we observe that the performance is sensitive to the configuration of MoE layers, making it challenging to obtain optimal results without careful design. The underlying cause is that inappropriate MoE layers lead to unreliable routing and hinder experts from effectively acquiring helpful knowledge. To address this, we introduce a shared expert to learn and capture common information, serving as an effective way to construct stable ViMoE. Furthermore, we demonstrate how to analyze expert routing behavior, revealing which MoE layers are capable of specializing in handling specific information and which are not. This provides guidance for retaining the critical layers while removing redundancies, thereby advancing ViMoE to be more efficient without sacrificing accuracy. We aspire for this work to offer new insights into the design of vision MoE models and provide valuable empirical guidance for future research.
Modeling, Design, and Verification of An Active Transmissive RIS
Oct 16, 2024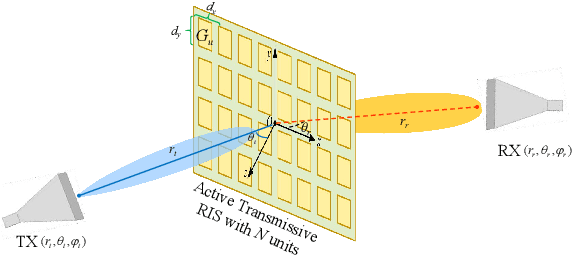
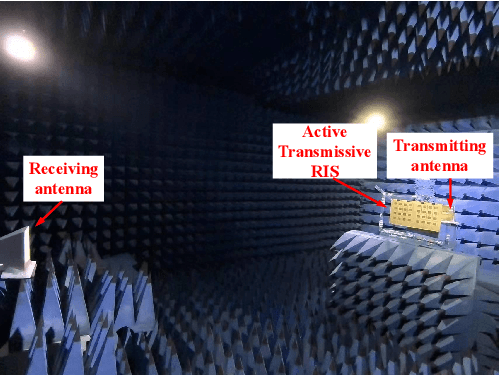
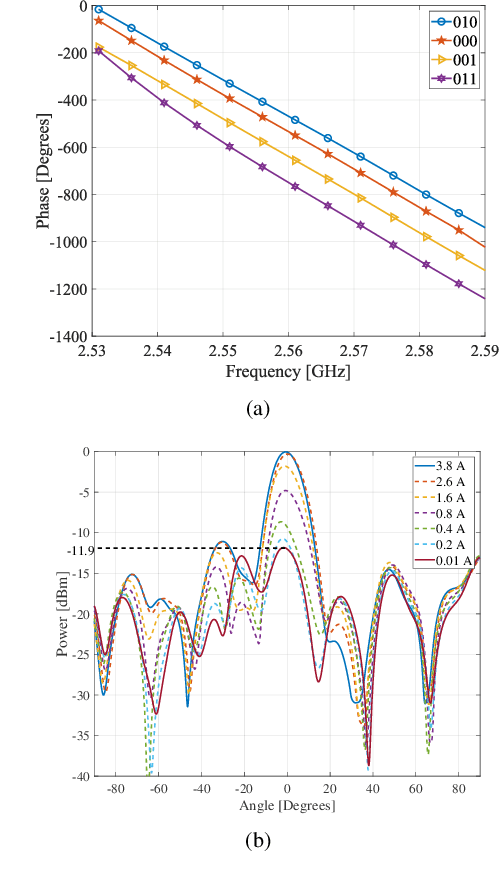
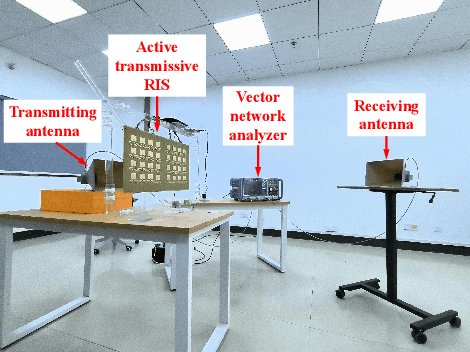
Reconfigurable Intelligent Surface (RIS) is a promising technology that may effectively improve the quality of signals in wireless communications. In practice, however, the ``double fading'' effect undermines the application of RIS and constitutes a significant challenge to its commercialization. To address this problem, we present a novel 2-bit programmable amplifying transmissive RIS with a power amplification function to enhance the transmission of electromagnetic signals. The transmissive function is achieved through a pair of radiation patches located on the upper and lower surfaces, respectively, while a microstrip line connects two patches. A power amplifier, SP4T switch, and directional coupler provide signal amplification and a 2-bit phase shift. To characterize the signal enhancement of active transmissive RIS, we propose a dual radar cross section (RCS)-based path loss model to predict the power of the received signal for active transmissive RIS-aided wireless communication systems. Simulation and experimental results verify the reliability of the RIS design, and the proposed path loss model is validated by measurements. Compared with the traditional passive RIS, the signal power gain in this design achieves 11.9 dB.
Revisit Event Generation Model: Self-Supervised Learning of Event-to-Video Reconstruction with Implicit Neural Representations
Jul 26, 2024



Reconstructing intensity frames from event data while maintaining high temporal resolution and dynamic range is crucial for bridging the gap between event-based and frame-based computer vision. Previous approaches have depended on supervised learning on synthetic data, which lacks interpretability and risk over-fitting to the setting of the event simulator. Recently, self-supervised learning (SSL) based methods, which primarily utilize per-frame optical flow to estimate intensity via photometric constancy, has been actively investigated. However, they are vulnerable to errors in the case of inaccurate optical flow. This paper proposes a novel SSL event-to-video reconstruction approach, dubbed EvINR, which eliminates the need for labeled data or optical flow estimation. Our core idea is to reconstruct intensity frames by directly addressing the event generation model, essentially a partial differential equation (PDE) that describes how events are generated based on the time-varying brightness signals. Specifically, we utilize an implicit neural representation (INR), which takes in spatiotemporal coordinate $(x, y, t)$ and predicts intensity values, to represent the solution of the event generation equation. The INR, parameterized as a fully-connected Multi-layer Perceptron (MLP), can be optimized with its temporal derivatives supervised by events. To make EvINR feasible for online requisites, we propose several acceleration techniques that substantially expedite the training process. Comprehensive experiments demonstrate that our EvINR surpasses previous SSL methods by 38% w.r.t. Mean Squared Error (MSE) and is comparable or superior to SoTA supervised methods. Project page: https://vlislab22.github.io/EvINR/.
PyGS: Large-scale Scene Representation with Pyramidal 3D Gaussian Splatting
May 29, 2024Neural Radiance Fields (NeRFs) have demonstrated remarkable proficiency in synthesizing photorealistic images of large-scale scenes. However, they are often plagued by a loss of fine details and long rendering durations. 3D Gaussian Splatting has recently been introduced as a potent alternative, achieving both high-fidelity visual results and accelerated rendering performance. Nonetheless, scaling 3D Gaussian Splatting is fraught with challenges. Specifically, large-scale scenes grapples with the integration of objects across multiple scales and disparate viewpoints, which often leads to compromised efficacy as the Gaussians need to balance between detail levels. Furthermore, the generation of initialization points via COLMAP from large-scale dataset is both computationally demanding and prone to incomplete reconstructions. To address these challenges, we present Pyramidal 3D Gaussian Splatting (PyGS) with NeRF Initialization. Our approach represent the scene with a hierarchical assembly of Gaussians arranged in a pyramidal fashion. The top level of the pyramid is composed of a few large Gaussians, while each subsequent layer accommodates a denser collection of smaller Gaussians. We effectively initialize these pyramidal Gaussians through sampling a rapidly trained grid-based NeRF at various frequencies. We group these pyramidal Gaussians into clusters and use a compact weighting network to dynamically determine the influence of each pyramid level of each cluster considering camera viewpoint during rendering. Our method achieves a significant performance leap across multiple large-scale datasets and attains a rendering time that is over 400 times faster than current state-of-the-art approaches.
HR-INR: Continuous Space-Time Video Super-Resolution via Event Camera
May 22, 2024



Continuous space-time video super-resolution (C-STVSR) aims to simultaneously enhance video resolution and frame rate at an arbitrary scale. Recently, implicit neural representation (INR) has been applied to video restoration, representing videos as implicit fields that can be decoded at an arbitrary scale. However, the highly ill-posed nature of C-STVSR limits the effectiveness of current INR-based methods: they assume linear motion between frames and use interpolation or feature warping to generate features at arbitrary spatiotemporal positions with two consecutive frames. This restrains C-STVSR from capturing rapid and nonlinear motion and long-term dependencies (involving more than two frames) in complex dynamic scenes. In this paper, we propose a novel C-STVSR framework, called HR-INR, which captures both holistic dependencies and regional motions based on INR. It is assisted by an event camera, a novel sensor renowned for its high temporal resolution and low latency. To fully utilize the rich temporal information from events, we design a feature extraction consisting of (1) a regional event feature extractor - taking events as inputs via the proposed event temporal pyramid representation to capture the regional nonlinear motion and (2) a holistic event-frame feature extractor for long-term dependence and continuity motion. We then propose a novel INR-based decoder with spatiotemporal embeddings to capture long-term dependencies with a larger temporal perception field. We validate the effectiveness and generalization of our method on four datasets (both simulated and real data), showing the superiority of our method.
Co-Occ: Coupling Explicit Feature Fusion with Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction
Apr 09, 20243D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction. The project page is available at https://rorisis.github.io/Co-Occ_project-page/.
P2Seg: Pointly-supervised Segmentation via Mutual Distillation
Jan 18, 2024Point-level Supervised Instance Segmentation (PSIS) aims to enhance the applicability and scalability of instance segmentation by utilizing low-cost yet instance-informative annotations. Existing PSIS methods usually rely on positional information to distinguish objects, but predicting precise boundaries remains challenging due to the lack of contour annotations. Nevertheless, weakly supervised semantic segmentation methods are proficient in utilizing intra-class feature consistency to capture the boundary contours of the same semantic regions. In this paper, we design a Mutual Distillation Module (MDM) to leverage the complementary strengths of both instance position and semantic information and achieve accurate instance-level object perception. The MDM consists of Semantic to Instance (S2I) and Instance to Semantic (I2S). S2I is guided by the precise boundaries of semantic regions to learn the association between annotated points and instance contours. I2S leverages discriminative relationships between instances to facilitate the differentiation of various objects within the semantic map. Extensive experiments substantiate the efficacy of MDM in fostering the synergy between instance and semantic information, consequently improving the quality of instance-level object representations. Our method achieves 55.7 mAP$_{50}$ and 17.6 mAP on the PASCAL VOC and MS COCO datasets, significantly outperforming recent PSIS methods and several box-supervised instance segmentation competitors.