 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
GaGA: Towards Interactive Global Geolocation Assistant
Dec 12, 2024Global geolocation, which seeks to predict the geographical location of images captured anywhere in the world, is one of the most challenging tasks in the field of computer vision. In this paper, we introduce an innovative interactive global geolocation assistant named GaGA, built upon the flourishing large vision-language models (LVLMs). GaGA uncovers geographical clues within images and combines them with the extensive world knowledge embedded in LVLMs to determine the geolocations while also providing justifications and explanations for the prediction results. We further designed a novel interactive geolocation method that surpasses traditional static inference approaches. It allows users to intervene, correct, or provide clues for the predictions, making the model more flexible and practical. The development of GaGA relies on the newly proposed Multi-modal Global Geolocation (MG-Geo) dataset, a comprehensive collection of 5 million high-quality image-text pairs. GaGA achieves state-of-the-art performance on the GWS15k dataset, improving accuracy by 4.57% at the country level and 2.92% at the city level, setting a new benchmark. These advancements represent a significant leap forward in developing highly accurate, interactive geolocation systems with global applicability.
ClickTrack: Towards Real-time Interactive Single Object Tracking
Nov 24, 2024



Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
Click; Single Object Tracking; Video Object Segmentation; Real-time Interaction
Nov 20, 2024Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
CPR++: Object Localization via Single Coarse Point Supervision
Jan 30, 2024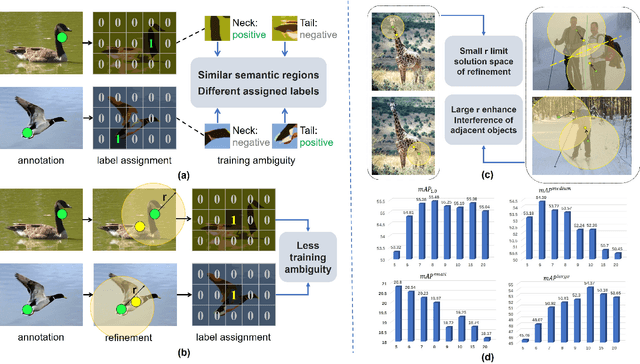
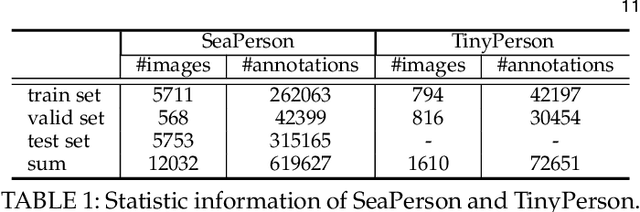

Point-based object localization (POL), which pursues high-performance object sensing under low-cost data annotation, has attracted increased attention. However, the point annotation mode inevitably introduces semantic variance due to the inconsistency of annotated points. Existing POL heavily rely on strict annotation rules, which are difficult to define and apply, to handle the problem. In this study, we propose coarse point refinement (CPR), which to our best knowledge is the first attempt to alleviate semantic variance from an algorithmic perspective. CPR reduces the semantic variance by selecting a semantic centre point in a neighbourhood region to replace the initial annotated point. Furthermore, We design a sampling region estimation module to dynamically compute a sampling region for each object and use a cascaded structure to achieve end-to-end optimization. We further integrate a variance regularization into the structure to concentrate the predicted scores, yielding CPR++. We observe that CPR++ can obtain scale information and further reduce the semantic variance in a global region, thus guaranteeing high-performance object localization. Extensive experiments on four challenging datasets validate the effectiveness of both CPR and CPR++. We hope our work can inspire more research on designing algorithms rather than annotation rules to address the semantic variance problem in POL. The dataset and code will be public at github.com/ucas-vg/PointTinyBenchmark.
Boosting Segment Anything Model Towards Open-Vocabulary Learning
Dec 06, 2023

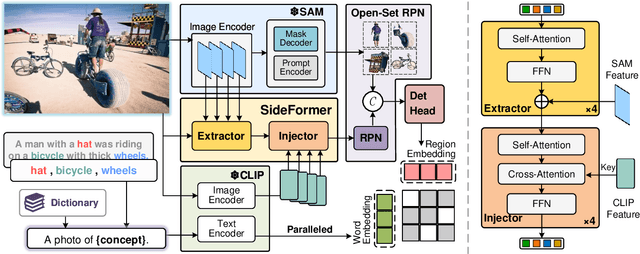

The recent Segment Anything Model (SAM) has emerged as a new paradigmatic vision foundation model, showcasing potent zero-shot generalization and flexible prompting. Despite SAM finding applications and adaptations in various domains, its primary limitation lies in the inability to grasp object semantics. In this paper, we present Sambor to seamlessly integrate SAM with the open-vocabulary object detector in an end-to-end framework. While retaining all the remarkable capabilities inherent to SAM, we enhance it with the capacity to detect arbitrary objects based on human inputs like category names or reference expressions. To accomplish this, we introduce a novel SideFormer module that extracts SAM features to facilitate zero-shot object localization and inject comprehensive semantic information for open-vocabulary recognition. In addition, we devise an open-set region proposal network (Open-set RPN), enabling the detector to acquire the open-set proposals generated by SAM. Sambor demonstrates superior zero-shot performance across benchmarks, including COCO and LVIS, proving highly competitive against previous SoTA methods. We aspire for this work to serve as a meaningful endeavor in endowing SAM to recognize diverse object categories and advancing open-vocabulary learning with the support of vision foundation models.
Anti-UAV: A Large Multi-Modal Benchmark for UAV Tracking
Feb 08, 2021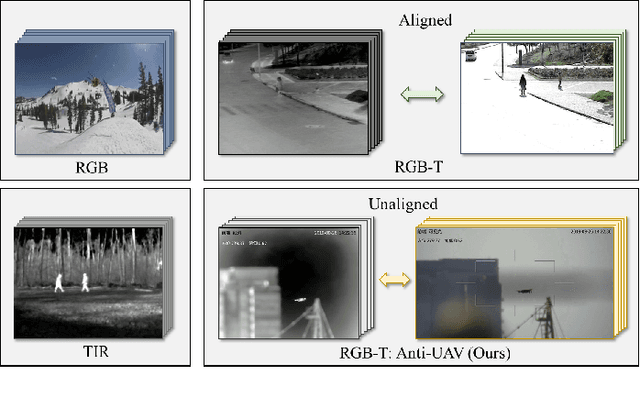


Unmanned Aerial Vehicle (UAV) offers lots of applications in both commerce and recreation. With this, monitoring the operation status of UAVs is crucially important. In this work, we consider the task of tracking UAVs, providing rich information such as location and trajectory. To facilitate research on this topic, we propose a dataset, Anti-UAV, with more than 300 video pairs containing over 580k manually annotated bounding boxes. The releasing of such a large-scale dataset could be a useful initial step in research of tracking UAVs. Furthermore, the advancement of addressing research challenges in Anti-UAV can help the design of anti-UAV systems, leading to better surveillance of UAVs. Besides, a novel approach named dual-flow semantic consistency (DFSC) is proposed for UAV tracking. Modulated by the semantic flow across video sequences, the tracker learns more robust class-level semantic information and obtains more discriminative instance-level features. Experimental results demonstrate that Anti-UAV is very challenging, and the proposed method can effectively improve the tracker's performance. The Anti-UAV benchmark and the code of the proposed approach will be publicly available at https://github.com/ucas-vg/Anti-UAV.