 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInEdit-Bench: Benchmarking Intermediate Logical Pathways for Intelligent Image Editing Models
Mar 04, 2026Multimodal generative models have made significant strides in image editing, demonstrating impressive performance on a variety of static tasks. However, their proficiency typically does not extend to complex scenarios requiring dynamic reasoning, leaving them ill-equipped to model the coherent, intermediate logical pathways that constitute a multi-step evolution from an initial state to a final one. This capacity is crucial for unlocking a deeper level of procedural and causal understanding in visual manipulation. To systematically measure this critical limitation, we introduce InEdit-Bench, the first evaluation benchmark dedicated to reasoning over intermediate pathways in image editing. InEdit-Bench comprises meticulously annotated test cases covering four fundamental task categories: state transition, dynamic process, temporal sequence, and scientific simulation. Additionally, to enable fine-grained evaluation, we propose a set of assessment criteria to evaluate the logical coherence and visual naturalness of the generated pathways, as well as the model's fidelity to specified path constraints. Our comprehensive evaluation of 14 representative image editing models on InEdit-Bench reveals significant and widespread shortcomings in this domain. By providing a standardized and challenging benchmark, we aim for InEdit-Bench to catalyze research and steer development towards more dynamic, reason-aware, and intelligent multimodal generative models.
HeroGS: Hierarchical Guidance for Robust 3D Gaussian Splatting under Sparse Views
Mar 03, 20263D Gaussian Splatting (3DGS) has recently emerged as a promising approach in novel view synthesis, combining photorealistic rendering with real-time efficiency. However, its success heavily relies on dense camera coverage; under sparse-view conditions, insufficient supervision leads to irregular Gaussian distributions, characterized by globally sparse coverage, blurred background, and distorted high-frequency areas. To address this, we propose HeroGS, Hierarchical Guidance for Robust 3D Gaussian Splatting, a unified framework that establishes hierarchical guidance across the image, feature, and parameter levels. At the image level, sparse supervision is converted into pseudo-dense guidance, globally regularizing the Gaussian distributions and forming a consistent foundation for subsequent optimization. Building upon this, Feature-Adaptive Densification and Pruning (FADP) at the feature level leverages low-level features to refine high-frequency details and adaptively densifies Gaussians in background regions. The optimized distributions then support Co-Pruned Geometry Consistency (CPG) at parameter level, which guides geometric consistency through parameter freezing and co-pruning, effectively removing inconsistent splats. The hierarchical guidance strategy effectively constrains and optimizes the overall Gaussian distributions, thereby enhancing both structural fidelity and rendering quality. Extensive experiments demonstrate that HeroGS achieves high-fidelity reconstructions and consistently surpasses state-of-the-art baselines under sparse-view conditions.
SAPNet++: Evolving Point-Prompted Instance Segmentation with Semantic and Spatial Awareness
Feb 25, 2026Single-point annotation is increasingly prominent in visual tasks for labeling cost reduction. However, it challenges tasks requiring high precision, such as the point-prompted instance segmentation (PPIS) task, which aims to estimate precise masks using single-point prompts to train a segmentation network. Due to the constraints of point annotations, granularity ambiguity and boundary uncertainty arise the difficulty distinguishing between different levels of detail (eg. whole object vs. parts) and the challenge of precisely delineating object boundaries. Previous works have usually inherited the paradigm of mask generation along with proposal selection to achieve PPIS. However, proposal selection relies solely on category information, failing to resolve the ambiguity of different granularity. Furthermore, mask generators offer only finite discrete solutions that often deviate from actual masks, particularly at boundaries. To address these issues, we propose the Semantic-Aware Point-Prompted Instance Segmentation Network (SAPNet). It integrates Point Distance Guidance and Box Mining Strategy to tackle group and local issues caused by the point's granularity ambiguity. Additionally, we incorporate completeness scores within proposals to add spatial granularity awareness, enhancing multiple instance learning (MIL) in proposal selection termed S-MIL. The Multi-level Affinity Refinement conveys pixel and semantic clues, narrowing boundary uncertainty during mask refinement. These modules culminate in SAPNet++, mitigating point prompt's granularity ambiguity and boundary uncertainty and significantly improving segmentation performance. Extensive experiments on four challenging datasets validate the effectiveness of our methods, highlighting the potential to advance PPIS.
* 18 pages
AD^2-Bench: A Hierarchical CoT Benchmark for MLLM in Autonomous Driving under Adverse Conditions
Jun 11, 2025



Chain-of-Thought (CoT) reasoning has emerged as a powerful approach to enhance the structured, multi-step decision-making capabilities of Multi-Modal Large Models (MLLMs), is particularly crucial for autonomous driving with adverse weather conditions and complex traffic environments. However, existing benchmarks have largely overlooked the need for rigorous evaluation of CoT processes in these specific and challenging scenarios. To address this critical gap, we introduce AD^2-Bench, the first Chain-of-Thought benchmark specifically designed for autonomous driving with adverse weather and complex scenes. AD^2-Bench is meticulously constructed to fulfill three key criteria: comprehensive data coverage across diverse adverse environments, fine-grained annotations that support multi-step reasoning, and a dedicated evaluation framework tailored for assessing CoT performance. The core contribution of AD^2-Bench is its extensive collection of over 5.4k high-quality, manually annotated CoT instances. Each intermediate reasoning step in these annotations is treated as an atomic unit with explicit ground truth, enabling unprecedented fine-grained analysis of MLLMs' inferential processes under text-level, point-level, and region-level visual prompts. Our comprehensive evaluation of state-of-the-art MLLMs on AD^2-Bench reveals accuracy below 60%, highlighting the benchmark's difficulty and the need to advance robust, interpretable end-to-end autonomous driving systems. AD^2-Bench thus provides a standardized evaluation platform, driving research forward by improving MLLMs' reasoning in autonomous driving, making it an invaluable resource.
Mixpert: Mitigating Multimodal Learning Conflicts with Efficient Mixture-of-Vision-Experts
May 30, 2025Multimodal large language models (MLLMs) require a nuanced interpretation of complex image information, typically leveraging a vision encoder to perceive various visual scenarios. However, relying solely on a single vision encoder to handle diverse task domains proves difficult and inevitably leads to conflicts. Recent work enhances data perception by directly integrating multiple domain-specific vision encoders, yet this structure adds complexity and limits the potential for joint optimization. In this paper, we introduce Mixpert, an efficient mixture-of-vision-experts architecture that inherits the joint learning advantages from a single vision encoder while being restructured into a multi-expert paradigm for task-specific fine-tuning across different visual tasks. Additionally, we design a dynamic routing mechanism that allocates input images to the most suitable visual expert. Mixpert effectively alleviates domain conflicts encountered by a single vision encoder in multi-task learning with minimal additional computational cost, making it more efficient than multiple encoders. Furthermore, Mixpert integrates seamlessly into any MLLM, with experimental results demonstrating substantial performance gains across various tasks.
P2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
GaGA: Towards Interactive Global Geolocation Assistant
Dec 12, 2024



Global geolocation, which seeks to predict the geographical location of images captured anywhere in the world, is one of the most challenging tasks in the field of computer vision. In this paper, we introduce an innovative interactive global geolocation assistant named GaGA, built upon the flourishing large vision-language models (LVLMs). GaGA uncovers geographical clues within images and combines them with the extensive world knowledge embedded in LVLMs to determine the geolocations while also providing justifications and explanations for the prediction results. We further designed a novel interactive geolocation method that surpasses traditional static inference approaches. It allows users to intervene, correct, or provide clues for the predictions, making the model more flexible and practical. The development of GaGA relies on the newly proposed Multi-modal Global Geolocation (MG-Geo) dataset, a comprehensive collection of 5 million high-quality image-text pairs. GaGA achieves state-of-the-art performance on the GWS15k dataset, improving accuracy by 4.57% at the country level and 2.92% at the city level, setting a new benchmark. These advancements represent a significant leap forward in developing highly accurate, interactive geolocation systems with global applicability.
ViMoE: An Empirical Study of Designing Vision Mixture-of-Experts
Oct 21, 2024



Mixture-of-Experts (MoE) models embody the divide-and-conquer concept and are a promising approach for increasing model capacity, demonstrating excellent scalability across multiple domains. In this paper, we integrate the MoE structure into the classic Vision Transformer (ViT), naming it ViMoE, and explore the potential of applying MoE to vision through a comprehensive study on image classification. However, we observe that the performance is sensitive to the configuration of MoE layers, making it challenging to obtain optimal results without careful design. The underlying cause is that inappropriate MoE layers lead to unreliable routing and hinder experts from effectively acquiring helpful knowledge. To address this, we introduce a shared expert to learn and capture common information, serving as an effective way to construct stable ViMoE. Furthermore, we demonstrate how to analyze expert routing behavior, revealing which MoE layers are capable of specializing in handling specific information and which are not. This provides guidance for retaining the critical layers while removing redundancies, thereby advancing ViMoE to be more efficient without sacrificing accuracy. We aspire for this work to offer new insights into the design of vision MoE models and provide valuable empirical guidance for future research.
CPR++: Object Localization via Single Coarse Point Supervision
Jan 30, 2024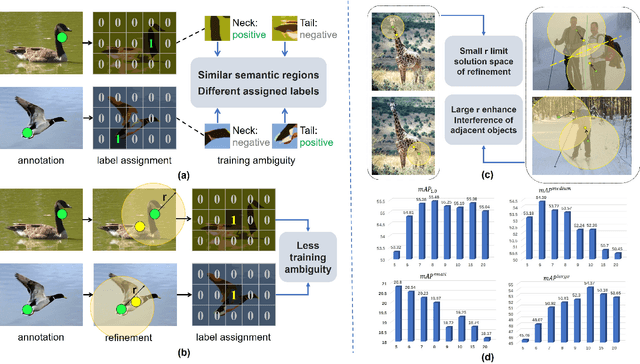
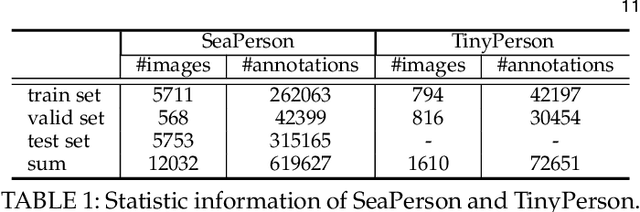

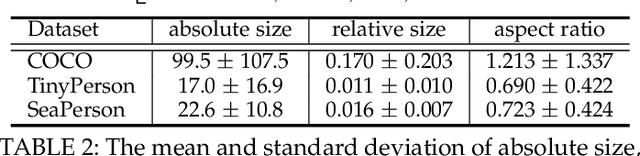
Point-based object localization (POL), which pursues high-performance object sensing under low-cost data annotation, has attracted increased attention. However, the point annotation mode inevitably introduces semantic variance due to the inconsistency of annotated points. Existing POL heavily rely on strict annotation rules, which are difficult to define and apply, to handle the problem. In this study, we propose coarse point refinement (CPR), which to our best knowledge is the first attempt to alleviate semantic variance from an algorithmic perspective. CPR reduces the semantic variance by selecting a semantic centre point in a neighbourhood region to replace the initial annotated point. Furthermore, We design a sampling region estimation module to dynamically compute a sampling region for each object and use a cascaded structure to achieve end-to-end optimization. We further integrate a variance regularization into the structure to concentrate the predicted scores, yielding CPR++. We observe that CPR++ can obtain scale information and further reduce the semantic variance in a global region, thus guaranteeing high-performance object localization. Extensive experiments on four challenging datasets validate the effectiveness of both CPR and CPR++. We hope our work can inspire more research on designing algorithms rather than annotation rules to address the semantic variance problem in POL. The dataset and code will be public at github.com/ucas-vg/PointTinyBenchmark.
P2Seg: Pointly-supervised Segmentation via Mutual Distillation
Jan 18, 2024Point-level Supervised Instance Segmentation (PSIS) aims to enhance the applicability and scalability of instance segmentation by utilizing low-cost yet instance-informative annotations. Existing PSIS methods usually rely on positional information to distinguish objects, but predicting precise boundaries remains challenging due to the lack of contour annotations. Nevertheless, weakly supervised semantic segmentation methods are proficient in utilizing intra-class feature consistency to capture the boundary contours of the same semantic regions. In this paper, we design a Mutual Distillation Module (MDM) to leverage the complementary strengths of both instance position and semantic information and achieve accurate instance-level object perception. The MDM consists of Semantic to Instance (S2I) and Instance to Semantic (I2S). S2I is guided by the precise boundaries of semantic regions to learn the association between annotated points and instance contours. I2S leverages discriminative relationships between instances to facilitate the differentiation of various objects within the semantic map. Extensive experiments substantiate the efficacy of MDM in fostering the synergy between instance and semantic information, consequently improving the quality of instance-level object representations. Our method achieves 55.7 mAP$_{50}$ and 17.6 mAP on the PASCAL VOC and MS COCO datasets, significantly outperforming recent PSIS methods and several box-supervised instance segmentation competitors.