 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeroGS: Hierarchical Guidance for Robust 3D Gaussian Splatting under Sparse Views
Mar 03, 20263D Gaussian Splatting (3DGS) has recently emerged as a promising approach in novel view synthesis, combining photorealistic rendering with real-time efficiency. However, its success heavily relies on dense camera coverage; under sparse-view conditions, insufficient supervision leads to irregular Gaussian distributions, characterized by globally sparse coverage, blurred background, and distorted high-frequency areas. To address this, we propose HeroGS, Hierarchical Guidance for Robust 3D Gaussian Splatting, a unified framework that establishes hierarchical guidance across the image, feature, and parameter levels. At the image level, sparse supervision is converted into pseudo-dense guidance, globally regularizing the Gaussian distributions and forming a consistent foundation for subsequent optimization. Building upon this, Feature-Adaptive Densification and Pruning (FADP) at the feature level leverages low-level features to refine high-frequency details and adaptively densifies Gaussians in background regions. The optimized distributions then support Co-Pruned Geometry Consistency (CPG) at parameter level, which guides geometric consistency through parameter freezing and co-pruning, effectively removing inconsistent splats. The hierarchical guidance strategy effectively constrains and optimizes the overall Gaussian distributions, thereby enhancing both structural fidelity and rendering quality. Extensive experiments demonstrate that HeroGS achieves high-fidelity reconstructions and consistently surpasses state-of-the-art baselines under sparse-view conditions.
SAPNet++: Evolving Point-Prompted Instance Segmentation with Semantic and Spatial Awareness
Feb 25, 2026Single-point annotation is increasingly prominent in visual tasks for labeling cost reduction. However, it challenges tasks requiring high precision, such as the point-prompted instance segmentation (PPIS) task, which aims to estimate precise masks using single-point prompts to train a segmentation network. Due to the constraints of point annotations, granularity ambiguity and boundary uncertainty arise the difficulty distinguishing between different levels of detail (eg. whole object vs. parts) and the challenge of precisely delineating object boundaries. Previous works have usually inherited the paradigm of mask generation along with proposal selection to achieve PPIS. However, proposal selection relies solely on category information, failing to resolve the ambiguity of different granularity. Furthermore, mask generators offer only finite discrete solutions that often deviate from actual masks, particularly at boundaries. To address these issues, we propose the Semantic-Aware Point-Prompted Instance Segmentation Network (SAPNet). It integrates Point Distance Guidance and Box Mining Strategy to tackle group and local issues caused by the point's granularity ambiguity. Additionally, we incorporate completeness scores within proposals to add spatial granularity awareness, enhancing multiple instance learning (MIL) in proposal selection termed S-MIL. The Multi-level Affinity Refinement conveys pixel and semantic clues, narrowing boundary uncertainty during mask refinement. These modules culminate in SAPNet++, mitigating point prompt's granularity ambiguity and boundary uncertainty and significantly improving segmentation performance. Extensive experiments on four challenging datasets validate the effectiveness of our methods, highlighting the potential to advance PPIS.
* 18 pages
Balancing Understanding and Generation in Discrete Diffusion Models
Feb 01, 2026In discrete generative modeling, two dominant paradigms demonstrate divergent capabilities: Masked Diffusion Language Models (MDLM) excel at semantic understanding and zero-shot generalization, whereas Uniform-noise Diffusion Language Models (UDLM) achieve strong few-step generation quality, yet neither attains balanced performance across both dimensions. To address this, we propose XDLM, which bridges the two paradigms via a stationary noise kernel. XDLM offers two key contributions: (1) it provides a principled theoretical unification of MDLM and UDLM, recovering each paradigm as a special case; and (2) an alleviated memory bottleneck enabled by an algebraic simplification of the posterior probabilities. Experiments demonstrate that XDLM advances the Pareto frontier between understanding capability and generation quality. Quantitatively, XDLM surpasses UDLM by 5.4 points on zero-shot text benchmarks and outperforms MDLM in few-step image generation (FID 54.1 vs. 80.8). When scaled to tune an 8B-parameter large language model, XDLM achieves 15.0 MBPP in just 32 steps, effectively doubling the baseline performance. Finally, analysis of training dynamics reveals XDLM's superior potential for long-term scaling. Code is available at https://github.com/MzeroMiko/XDLM
Persistent Backdoor Attacks under Continual Fine-Tuning of LLMs
Dec 12, 2025Backdoor attacks embed malicious behaviors into Large Language Models (LLMs), enabling adversaries to trigger harmful outputs or bypass safety controls. However, the persistence of the implanted backdoors under user-driven post-deployment continual fine-tuning has been rarely examined. Most prior works evaluate the effectiveness and generalization of implanted backdoors only at releasing and empirical evidence shows that naively injected backdoor persistence degrades after updates. In this work, we study whether and how implanted backdoors persist through a multi-stage post-deployment fine-tuning. We propose P-Trojan, a trigger-based attack algorithm that explicitly optimizes for backdoor persistence across repeated updates. By aligning poisoned gradients with those of clean tasks on token embeddings, the implanted backdoor mapping is less likely to be suppressed or forgotten during subsequent updates. Theoretical analysis shows the feasibility of such persistent backdoor attacks after continual fine-tuning. And experiments conducted on the Qwen2.5 and LLaMA3 families of LLMs, as well as diverse task sequences, demonstrate that P-Trojan achieves over 99% persistence while preserving clean-task accuracy. Our findings highlight the need for persistence-aware evaluation and stronger defenses in realistic model adaptation pipelines.
VER-Bench: Evaluating MLLMs on Reasoning with Fine-Grained Visual Evidence
Aug 06, 2025With the rapid development of MLLMs, evaluating their visual capabilities has become increasingly crucial. Current benchmarks primarily fall into two main types: basic perception benchmarks, which focus on local details but lack deep reasoning (e.g., "what is in the image?"), and mainstream reasoning benchmarks, which concentrate on prominent image elements but may fail to assess subtle clues requiring intricate analysis. However, profound visual understanding and complex reasoning depend more on interpreting subtle, inconspicuous local details than on perceiving salient, macro-level objects. These details, though occupying minimal image area, often contain richer, more critical information for robust analysis. To bridge this gap, we introduce the VER-Bench, a novel framework to evaluate MLLMs' ability to: 1) identify fine-grained visual clues, often occupying on average just 0.25% of the image area; 2) integrate these clues with world knowledge for complex reasoning. Comprising 374 carefully designed questions across Geospatial, Temporal, Situational, Intent, System State, and Symbolic reasoning, each question in VER-Bench is accompanied by structured evidence: visual clues and question-related reasoning derived from them. VER-Bench reveals current models' limitations in extracting subtle visual evidence and constructing evidence-based arguments, highlighting the need to enhance models's capabilities in fine-grained visual evidence extraction, integration, and reasoning for genuine visual understanding and human-like analysis. Dataset and additional materials are available https://github.com/verbta/ACMMM-25-Materials.
CAGS: Open-Vocabulary 3D Scene Understanding with Context-Aware Gaussian Splatting
Apr 16, 2025Open-vocabulary 3D scene understanding is crucial for applications requiring natural language-driven spatial interpretation, such as robotics and augmented reality. While 3D Gaussian Splatting (3DGS) offers a powerful representation for scene reconstruction, integrating it with open-vocabulary frameworks reveals a key challenge: cross-view granularity inconsistency. This issue, stemming from 2D segmentation methods like SAM, results in inconsistent object segmentations across views (e.g., a "coffee set" segmented as a single entity in one view but as "cup + coffee + spoon" in another). Existing 3DGS-based methods often rely on isolated per-Gaussian feature learning, neglecting the spatial context needed for cohesive object reasoning, leading to fragmented representations. We propose Context-Aware Gaussian Splatting (CAGS), a novel framework that addresses this challenge by incorporating spatial context into 3DGS. CAGS constructs local graphs to propagate contextual features across Gaussians, reducing noise from inconsistent granularity, employs mask-centric contrastive learning to smooth SAM-derived features across views, and leverages a precomputation strategy to reduce computational cost by precomputing neighborhood relationships, enabling efficient training in large-scale scenes. By integrating spatial context, CAGS significantly improves 3D instance segmentation and reduces fragmentation errors on datasets like LERF-OVS and ScanNet, enabling robust language-guided 3D scene understanding.
P2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
Adaptive Keyframe Sampling for Long Video Understanding
Feb 28, 2025



Multimodal large language models (MLLMs) have enabled open-world visual understanding by injecting visual input as extra tokens into large language models (LLMs) as contexts. However, when the visual input changes from a single image to a long video, the above paradigm encounters difficulty because the vast amount of video tokens has significantly exceeded the maximal capacity of MLLMs. Therefore, existing video-based MLLMs are mostly established upon sampling a small portion of tokens from input data, which can cause key information to be lost and thus produce incorrect answers. This paper presents a simple yet effective algorithm named Adaptive Keyframe Sampling (AKS). It inserts a plug-and-play module known as keyframe selection, which aims to maximize the useful information with a fixed number of video tokens. We formulate keyframe selection as an optimization involving (1) the relevance between the keyframes and the prompt, and (2) the coverage of the keyframes over the video, and present an adaptive algorithm to approximate the best solution. Experiments on two long video understanding benchmarks validate that Adaptive Keyframe Sampling improves video QA accuracy (beyond strong baselines) upon selecting informative keyframes. Our study reveals the importance of information pre-filtering in video-based MLLMs. Code is available at https://github.com/ncTimTang/AKS.
DeProPose: Deficiency-Proof 3D Human Pose Estimation via Adaptive Multi-View Fusion
Feb 23, 2025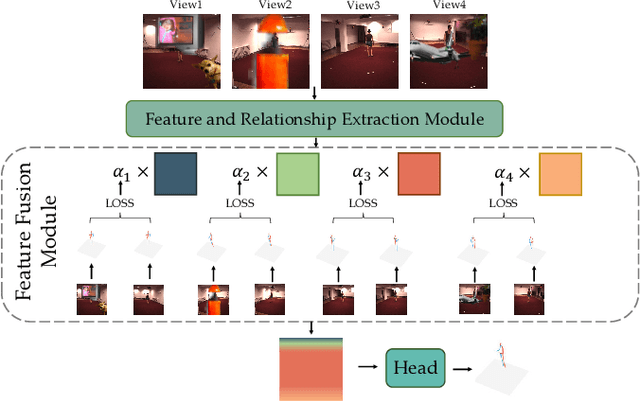
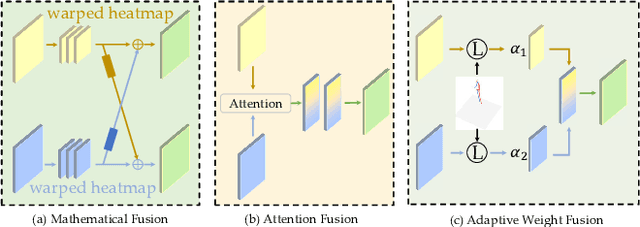
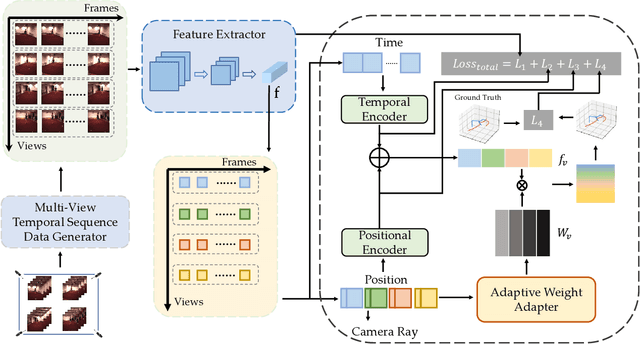
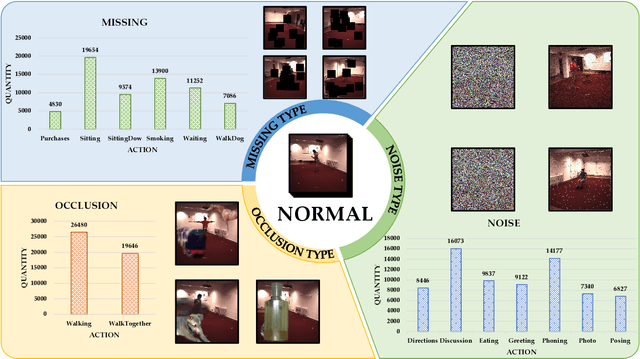
3D human pose estimation has wide applications in fields such as intelligent surveillance, motion capture, and virtual reality. However, in real-world scenarios, issues such as occlusion, noise interference, and missing viewpoints can severely affect pose estimation. To address these challenges, we introduce the task of Deficiency-Aware 3D Pose Estimation. Traditional 3D pose estimation methods often rely on multi-stage networks and modular combinations, which can lead to cumulative errors and increased training complexity, making them unable to effectively address deficiency-aware estimation. To this end, we propose DeProPose, a flexible method that simplifies the network architecture to reduce training complexity and avoid information loss in multi-stage designs. Additionally, the model innovatively introduces a multi-view feature fusion mechanism based on relative projection error, which effectively utilizes information from multiple viewpoints and dynamically assigns weights, enabling efficient integration and enhanced robustness to overcome deficiency-aware 3D Pose Estimation challenges. Furthermore, to thoroughly evaluate this end-to-end multi-view 3D human pose estimation model and to advance research on occlusion-related challenges, we have developed a novel 3D human pose estimation dataset, termed the Deficiency-Aware 3D Pose Estimation (DA-3DPE) dataset. This dataset encompasses a wide range of deficiency scenarios, including noise interference, missing viewpoints, and occlusion challenges. Compared to state-of-the-art methods, DeProPose not only excels in addressing the deficiency-aware problem but also shows improvement in conventional scenarios, providing a powerful and user-friendly solution for 3D human pose estimation. The source code will be available at https://github.com/WUJINHUAN/DeProPose.
EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning
Feb 18, 2025
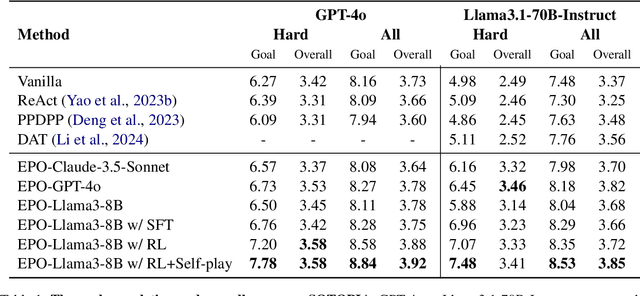
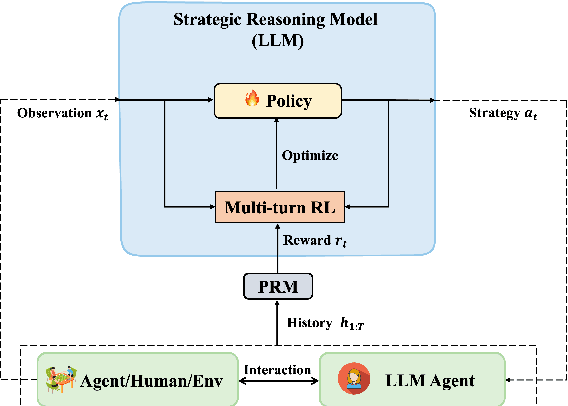
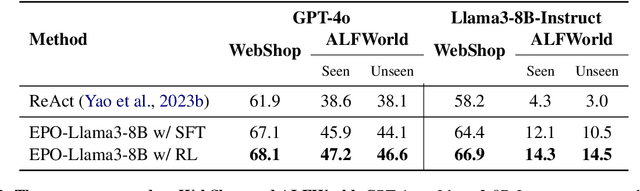
Large Language Models (LLMs) have shown impressive reasoning capabilities in well-defined problems with clear solutions, such as mathematics and coding. However, they still struggle with complex real-world scenarios like business negotiations, which require strategic reasoning-an ability to navigate dynamic environments and align long-term goals amidst uncertainty. Existing methods for strategic reasoning face challenges in adaptability, scalability, and transferring strategies to new contexts. To address these issues, we propose explicit policy optimization (EPO) for strategic reasoning, featuring an LLM that provides strategies in open-ended action space and can be plugged into arbitrary LLM agents to motivate goal-directed behavior. To improve adaptability and policy transferability, we train the strategic reasoning model via multi-turn reinforcement learning (RL) using process rewards and iterative self-play, without supervised fine-tuning (SFT) as a preliminary step. Experiments across social and physical domains demonstrate EPO's ability of long-term goal alignment through enhanced strategic reasoning, achieving state-of-the-art performance on social dialogue and web navigation tasks. Our findings reveal various collaborative reasoning mechanisms emergent in EPO and its effectiveness in generating novel strategies, underscoring its potential for strategic reasoning in real-world applications.