 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPAIR: Gaussian-Kernel-Based Ultrafast 3D Photoacoustic Iterative Reconstruction
Feb 03, 2026Although the iterative reconstruction (IR) algorithm can substantially correct reconstruction artifacts in photoacoustic (PA) computed tomography (PACT), it suffers from long reconstruction times, especially for large-scale three-dimensional (3D) imaging in which IR takes hundreds of seconds to hours. The computing burden severely limits the practical applicability of IR algorithms. In this work, we proposed an ultrafast IR method for 3D PACT, called Gaussian-kernel-based Ultrafast 3D Photoacoustic Iterative Reconstruction (GPAIR), which achieves orders-of-magnitude acceleration in computing. GPAIR transforms traditional spatial grids with continuous isotropic Gaussian kernels. By deriving analytical closed-form expression for pressure waves and implementing powerful GPU-accelerated differentiable Triton operators, GPAIR demonstrates extraordinary ultrafast sub-second reconstruction speed for 3D targets containing 8.4 million voxels in animal experiments. This revolutionary ultrafast image reconstruction enables near-real-time large-scale 3D PA reconstruction, significantly advancing 3D PACT toward clinical applications.
SlingBAG Pro: Accelerating point cloud-based iterative reconstruction for 3D photoacoustic imaging with arbitrary array geometries
Jan 06, 2026High-quality three-dimensional (3D) photoacoustic imaging (PAI) is gaining increasing attention in clinical applications. To address the challenges of limited space and high costs, irregular geometric transducer arrays that conform to specific imaging regions are promising for achieving high-quality 3D PAI with fewer transducers. However, traditional iterative reconstruction algorithms struggle with irregular array configurations, suffering from high computational complexity, substantial memory requirements, and lengthy reconstruction times. In this work, we introduce SlingBAG Pro, an advanced reconstruction algorithm based on the point cloud iteration concept of the Sliding ball adaptive growth (SlingBAG) method, while extending its compatibility to arbitrary array geometries. SlingBAG Pro maintains high reconstruction quality, reduces the number of required transducers, and employs a hierarchical optimization strategy that combines zero-gradient filtering with progressively increased temporal sampling rates during iteration. This strategy rapidly removes redundant spatial point clouds, accelerates convergence, and significantly shortens overall reconstruction time. Compared to the original SlingBAG algorithm, SlingBAG Pro achieves up to a 2.2-fold speed improvement in point cloud-based 3D PA reconstruction under irregular array geometries. The proposed method is validated through both simulation and in vivo mouse experiments, and the source code is publicly available at https://github.com/JaegerCQ/SlingBAG_Pro.
A Physics-informed Deep Operator for Real-Time Freeway Traffic State Estimation
Aug 11, 2025Traffic state estimation (TSE) falls methodologically into three categories: model-driven, data-driven, and model-data dual-driven. Model-driven TSE relies on macroscopic traffic flow models originated from hydrodynamics. Data-driven TSE leverages historical sensing data and employs statistical models or machine learning methods to infer traffic state. Model-data dual-driven traffic state estimation attempts to harness the strengths of both aspects to achieve more accurate TSE. From the perspective of mathematical operator theory, TSE can be viewed as a type of operator that maps available measurements of inerested traffic state into unmeasured traffic state variables in real time. For the first time this paper proposes to study real-time freeway TSE in the idea of physics-informed deep operator network (PI-DeepONet), which is an operator-oriented architecture embedding traffic flow models based on deep neural networks. The paper has developed an extended architecture from the original PI-DeepONet. The extended architecture is featured with: (1) the acceptance of 2-D data input so as to support CNN-based computations; (2) the introduction of a nonlinear expansion layer, an attention mechanism, and a MIMO mechanism; (3) dedicated neural network design for adaptive identification of traffic flow model parameters. A traffic state estimator built on the basis of this extended PI-DeepONet architecture was evaluated with respect to a short freeway stretch of NGSIM and a large-scale urban expressway in China, along with other four baseline TSE methods. The evaluation results demonstrated that this novel TSE method outperformed the baseline methods with high-precision estimation results of flow and mean speed.
X-Omni: Reinforcement Learning Makes Discrete Autoregressive Image Generative Models Great Again
Jul 29, 2025Numerous efforts have been made to extend the ``next token prediction'' paradigm to visual contents, aiming to create a unified approach for both image generation and understanding. Nevertheless, attempts to generate images through autoregressive modeling with discrete tokens have been plagued by issues such as low visual fidelity, distorted outputs, and failure to adhere to complex instructions when rendering intricate details. These shortcomings are likely attributed to cumulative errors during autoregressive inference or information loss incurred during the discretization process. Probably due to this challenge, recent research has increasingly shifted toward jointly training image generation with diffusion objectives and language generation with autoregressive objectives, moving away from unified modeling approaches. In this work, we demonstrate that reinforcement learning can effectively mitigate artifacts and largely enhance the generation quality of a discrete autoregressive modeling method, thereby enabling seamless integration of image and language generation. Our framework comprises a semantic image tokenizer, a unified autoregressive model for both language and images, and an offline diffusion decoder for image generation, termed X-Omni. X-Omni achieves state-of-the-art performance in image generation tasks using a 7B language model, producing images with high aesthetic quality while exhibiting strong capabilities in following instructions and rendering long texts.
Video-R1: Reinforcing Video Reasoning in MLLMs
Mar 27, 2025



Inspired by DeepSeek-R1's success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for eliciting video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-COT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 35.8% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All codes, models, data are released.
Network-wide Freeway Traffic Estimation Using Sparse Sensor Data: A Dirichlet Graph Auto-Encoder Approach
Mar 20, 2025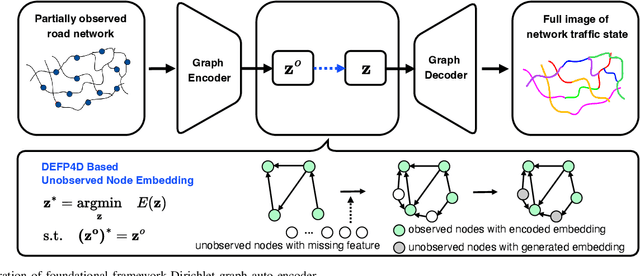
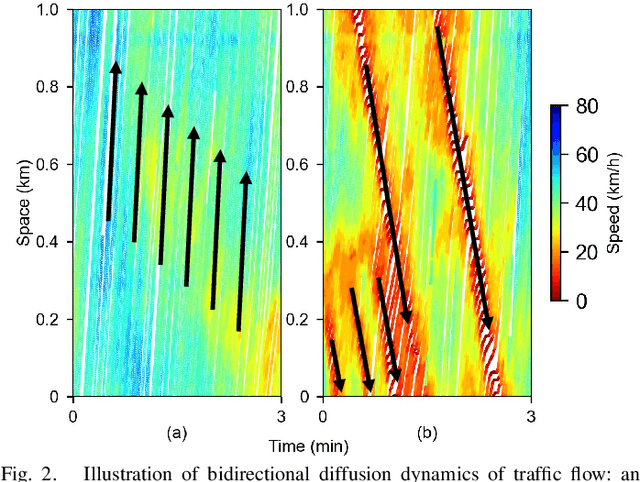
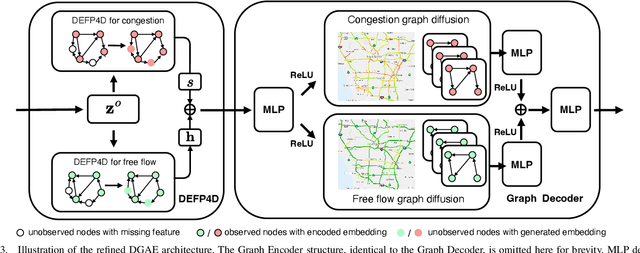
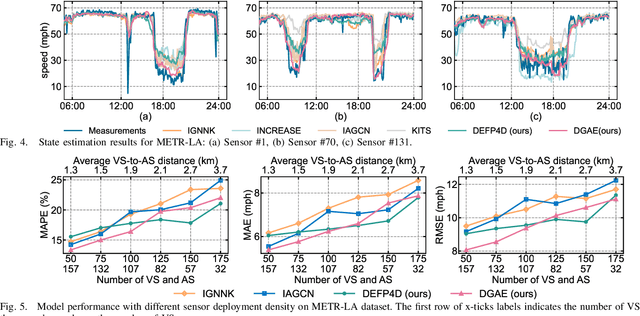
Network-wide Traffic State Estimation (TSE), which aims to infer a complete image of network traffic states with sparsely deployed sensors, plays a vital role in intelligent transportation systems. With the development of data-driven methods, traffic dynamics modeling has advanced significantly. However, TSE poses fundamental challenges for data-driven approaches, since historical patterns cannot be learned locally at sensor-free segments. Although inductive graph learning shows promise in estimating states at locations without sensor, existing methods typically handle unobserved locations by filling them with zeros, introducing bias to the sensitive graph message propagation. The recently proposed Dirichlet Energy-based Feature Propagation (DEFP) method achieves State-Of-The-Art (SOTA) performance in unobserved node classification by eliminating the need for zero-filling. However, applying it to TSE faces three key challenges: inability to handle directed traffic networks, strong assumptions in traffic spatial correlation modeling, and overlooks distinct propagation rules of different patterns (e.g., congestion and free flow). We propose DGAE, a novel inductive graph representation model that addresses these challenges through theoretically derived DEFP for Directed graph (DEFP4D), enhanced spatial representation learning via DEFP4D-guided latent space encoding, and physics-guided propagation mechanisms that separately handles congested and free-flow patterns. Experiments on three traffic datasets demonstrate that DGAE outperforms existing SOTA methods and exhibits strong cross-city transferability. Furthermore, DEFP4D can serve as a standalone lightweight solution, showing superior performance under extremely sparse sensor conditions.
MoGERNN: An Inductive Traffic Predictor for Unobserved Locations in Dynamic Sensing Networks
Jan 21, 2025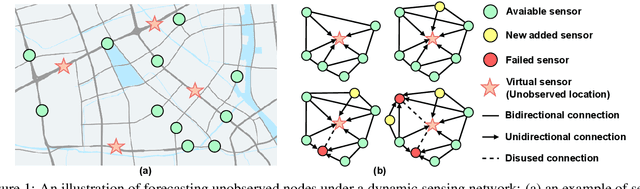

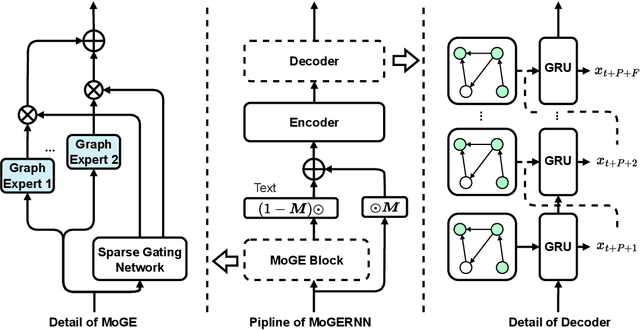
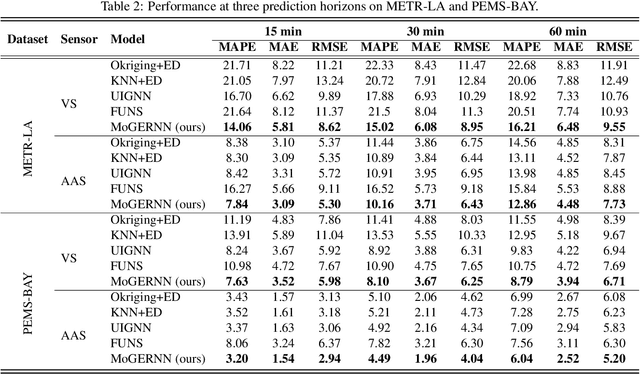
Given a partially observed road network, how can we predict the traffic state of unobserved locations? While deep learning approaches show exceptional performance in traffic prediction, most assume sensors at all locations of interest, which is impractical due to financial constraints. Furthermore, these methods typically require costly retraining when sensor configurations change. We propose MoGERNN, an inductive spatio-temporal graph representation model, to address these challenges. Inspired by the Mixture of Experts approach in Large Language Models, we introduce a Mixture of Graph Expert (MoGE) block to model complex spatial dependencies through multiple graph message aggregators and a sparse gating network. This block estimates initial states for unobserved locations, which are then processed by a GRU-based Encoder-Decoder that integrates a graph message aggregator to capture spatio-temporal dependencies and predict future states. Experiments on two real-world datasets show MoGERNN consistently outperforms baseline methods for both observed and unobserved locations. MoGERNN can accurately predict congestion evolution even in areas without sensors, offering valuable information for traffic management. Moreover, MoGERNN is adaptable to dynamic sensing networks, maintaining competitive performance even compared to its retrained counterpart. Tests with different numbers of available sensors confirm its consistent superiority, and ablation studies validate the effectiveness of its key modules.
Zero-Shot Artifact2Artifact: Self-incentive artifact removal for photoacoustic imaging without any data
Dec 19, 2024



Photoacoustic imaging (PAI) uniquely combines optical contrast with the penetration depth of ultrasound, making it critical for clinical applications. However, the quality of 3D PAI is often degraded due to reconstruction artifacts caused by the sparse and angle-limited configuration of detector arrays. Existing iterative or deep learning-based methods are either time-consuming or require large training datasets, significantly limiting their practical application. Here, we propose Zero-Shot Artifact2Artifact (ZS-A2A), a zero-shot self-supervised artifact removal method based on a super-lightweight network, which leverages the fact that reconstruction artifacts are sensitive to irregularities caused by data loss. By introducing random perturbations to the acquired PA data, it spontaneously generates subset data, which in turn stimulates the network to learn the artifact patterns in the reconstruction results, thus enabling zero-shot artifact removal. This approach requires neither training data nor prior knowledge of the artifacts, and is capable of artifact removal for 3D PAI. For maximum amplitude projection (MAP) images or slice images in 3D PAI acquired with arbitrarily sparse or angle-limited detector arrays, ZS-A2A employs a self-incentive strategy to complete artifact removal and improves the Contrast-to-Noise Ratio (CNR). We validated ZS-A2A in both simulation study and $ in\ vivo $ animal experiments. Results demonstrate that ZS-A2A achieves state-of-the-art (SOTA) performance compared to existing zero-shot methods, and for the $ in\ vivo $ rat liver, ZS-A2A improves CNR from 17.48 to 43.46 in just 8 seconds. The project for ZS-A2A will be available in the following GitHub repository: https://github.com/JaegerCQ/ZS-A2A.
4D SlingBAG: spatial-temporal coupled Gaussian ball for large-scale dynamic 3D photoacoustic iterative reconstruction
Dec 05, 2024Large-scale dynamic three-dimensional (3D) photoacoustic imaging (PAI) is significantly important in clinical applications. In practical implementations, large-scale 3D real-time PAI systems typically utilize sparse two-dimensional (2D) sensor arrays with certain angular deficiencies, necessitating advanced iterative reconstruction (IR) algorithms to achieve quantitative PAI and reduce reconstruction artifacts. However, for existing IR algorithms, multi-frame 3D reconstruction leads to extremely high memory consumption and prolonged computation time, with limited consideration of the spatial-temporal continuity between data frames. Here, we propose a novel method, named the 4D sliding Gaussian ball adaptive growth (4D SlingBAG) algorithm, based on the current point cloud-based IR algorithm sliding Gaussian ball adaptive growth (SlingBAG), which has minimal memory consumption among IR methods. Our 4D SlingBAG method applies spatial-temporal coupled deformation functions to each Gaussian sphere in point cloud, thus explicitly learning the deformations features of the dynamic 3D PA scene. This allows for the efficient representation of various physiological processes (such as pulsation) or external pressures (e.g., blood perfusion experiments) contributing to changes in vessel morphology and blood flow during dynamic 3D PAI, enabling highly efficient IR for dynamic 3D PAI. Simulation experiments demonstrate that 4D SlingBAG achieves high-quality dynamic 3D PA reconstruction. Compared to performing reconstructions by using SlingBAG algorithm individually for each frame, our method significantly reduces computational time and keeps a extremely low memory consumption. The project for 4D SlingBAG can be found in the following GitHub repository: \href{https://github.com/JaegerCQ/4D-SlingBAG}{https://github.com/JaegerCQ/4D-SlingBAG}.
AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
Dec 03, 2024



Recently, multimodal large language models (MLLMs), such as GPT-4o, Gemini 1.5 Pro, and Reka Core, have expanded their capabilities to include vision and audio modalities. While these models demonstrate impressive performance across a wide range of audio-visual applications, our proposed DeafTest reveals that MLLMs often struggle with simple tasks humans find trivial: 1) determining which of two sounds is louder, and 2) determining which of two sounds has a higher pitch. Motivated by these observations, we introduce AV-Odyssey Bench, a comprehensive audio-visual benchmark designed to assess whether those MLLMs can truly understand the audio-visual information. This benchmark encompasses 4,555 carefully crafted problems, each incorporating text, visual, and audio components. To successfully infer answers, models must effectively leverage clues from both visual and audio inputs. To ensure precise and objective evaluation of MLLM responses, we have structured the questions as multiple-choice, eliminating the need for human evaluation or LLM-assisted assessment. We benchmark a series of closed-source and open-source models and summarize the observations. By revealing the limitations of current models, we aim to provide useful insight for future dataset collection and model development.