 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Image Technical Report
Dec 08, 2025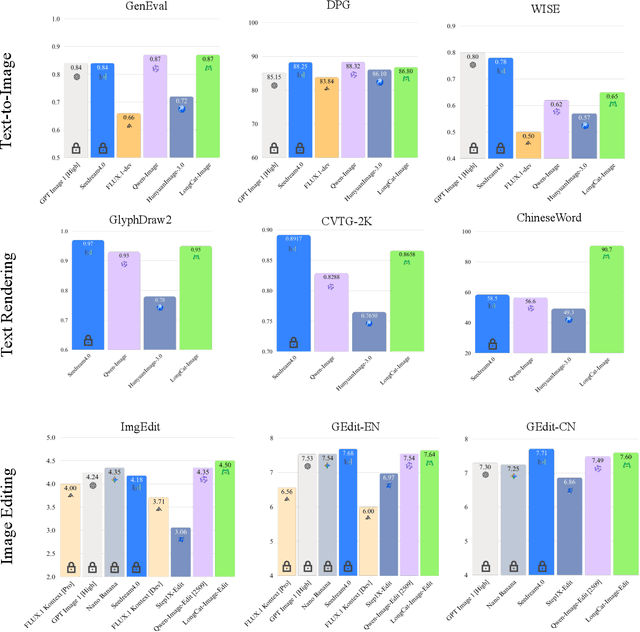
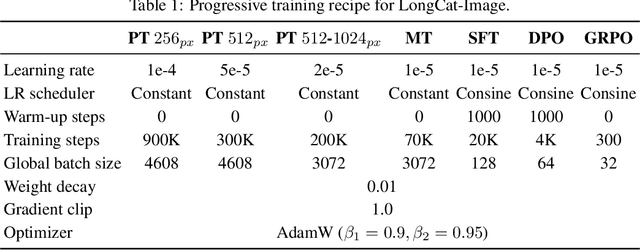

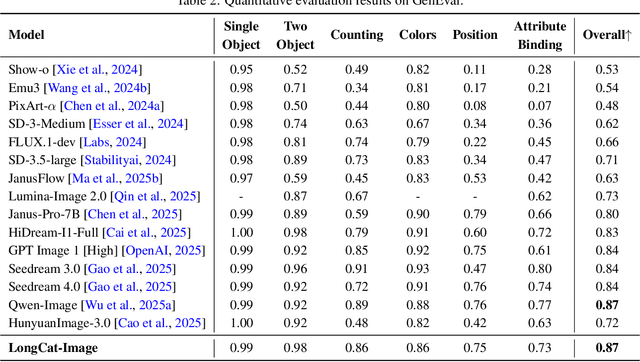
We introduce LongCat-Image, a pioneering open-source and bilingual (Chinese-English) foundation model for image generation, designed to address core challenges in multilingual text rendering, photorealism, deployment efficiency, and developer accessibility prevalent in current leading models. 1) We achieve this through rigorous data curation strategies across the pre-training, mid-training, and SFT stages, complemented by the coordinated use of curated reward models during the RL phase. This strategy establishes the model as a new state-of-the-art (SOTA), delivering superior text-rendering capabilities and remarkable photorealism, and significantly enhancing aesthetic quality. 2) Notably, it sets a new industry standard for Chinese character rendering. By supporting even complex and rare characters, it outperforms both major open-source and commercial solutions in coverage, while also achieving superior accuracy. 3) The model achieves remarkable efficiency through its compact design. With a core diffusion model of only 6B parameters, it is significantly smaller than the nearly 20B or larger Mixture-of-Experts (MoE) architectures common in the field. This ensures minimal VRAM usage and rapid inference, significantly reducing deployment costs. Beyond generation, LongCat-Image also excels in image editing, achieving SOTA results on standard benchmarks with superior editing consistency compared to other open-source works. 4) To fully empower the community, we have established the most comprehensive open-source ecosystem to date. We are releasing not only multiple model versions for text-to-image and image editing, including checkpoints after mid-training and post-training stages, but also the entire toolchain of training procedure. We believe that the openness of LongCat-Image will provide robust support for developers and researchers, pushing the frontiers of visual content creation.
Kangaroo: A Powerful Video-Language Model Supporting Long-context Video Input
Aug 28, 2024



Rapid advancements have been made in extending Large Language Models (LLMs) to Large Multi-modal Models (LMMs). However, extending input modality of LLMs to video data remains a challenging endeavor, especially for long videos. Due to insufficient access to large-scale high-quality video data and the excessive compression of visual features, current methods exhibit limitations in effectively processing long videos. In this paper, we introduce Kangaroo, a powerful Video LMM aimed at addressing these challenges. Confronted with issue of inadequate training data, we develop a data curation system to build a large-scale dataset with high-quality annotations for vision-language pre-training and instruction tuning. In addition, we design a curriculum training pipeline with gradually increasing resolution and number of input frames to accommodate long videos. Evaluation results demonstrate that, with 8B parameters, Kangaroo achieves state-of-the-art performance across a variety of video understanding benchmarks while exhibiting competitive results on others. Particularly, on benchmarks specialized for long videos, Kangaroo excels some larger models with over 10B parameters and proprietary models.
Deep Learning in Breast Cancer Imaging: A Decade of Progress and Future Directions
Apr 27, 2023



Breast cancer has reached the highest incidence rate worldwide among all malignancies since 2020. Breast imaging plays a significant role in early diagnosis and intervention to improve the outcome of breast cancer patients. In the past decade, deep learning has shown remarkable progress in breast cancer imaging analysis, holding great promise in interpreting the rich information and complex context of breast imaging modalities. Considering the rapid improvement in the deep learning technology and the increasing severity of breast cancer, it is critical to summarize past progress and identify future challenges to be addressed. In this paper, we provide an extensive survey of deep learning-based breast cancer imaging research, covering studies on mammogram, ultrasound, magnetic resonance imaging, and digital pathology images over the past decade. The major deep learning methods, publicly available datasets, and applications on imaging-based screening, diagnosis, treatment response prediction, and prognosis are described in detail. Drawn from the findings of this survey, we present a comprehensive discussion of the challenges and potential avenues for future research in deep learning-based breast cancer imaging.
Scene Matters: Model-based Deep Video Compression
Mar 08, 2023Video compression has always been a popular research area, where many traditional and deep video compression methods have been proposed. These methods typically rely on signal prediction theory to enhance compression performance by designing high efficient intra and inter prediction strategies and compressing video frames one by one. In this paper, we propose a novel model-based video compression (MVC) framework that regards scenes as the fundamental units for video sequences. Our proposed MVC directly models the intensity variation of the entire video sequence in one scene, seeking non-redundant representations instead of reducing redundancy through spatio-temporal predictions. To achieve this, we employ implicit neural representation (INR) as our basic modeling architecture. To improve the efficiency of video modeling, we first propose context-related spatial positional embedding (CRSPE) and frequency domain supervision (FDS) in spatial context enhancement. For temporal correlation capturing, we design the scene flow constrain mechanism (SFCM) and temporal contrastive loss (TCL). Extensive experimental results demonstrate that our method achieves up to a 20\% bitrate reduction compared to the latest video coding standard H.266 and is more efficient in decoding than existing video coding strategies.
SC-Transformer++: Structured Context Transformer for Generic Event Boundary Detection
Jun 25, 2022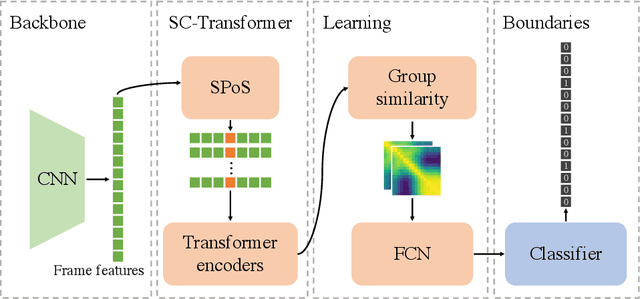
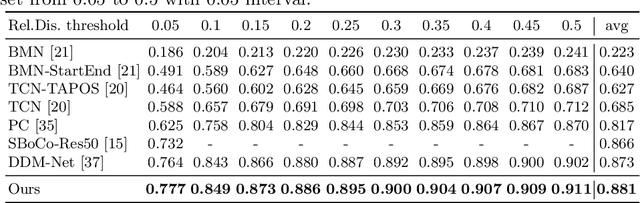
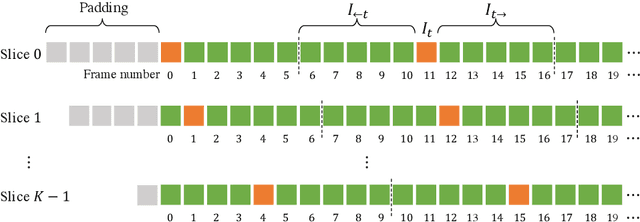
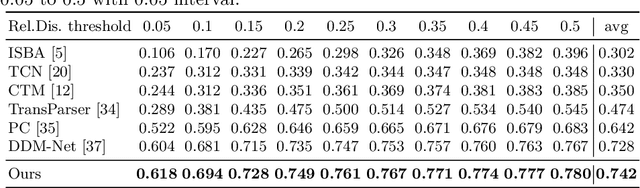
This report presents the algorithm used in the submission of Generic Event Boundary Detection (GEBD) Challenge at CVPR 2022. In this work, we improve the existing Structured Context Transformer (SC-Transformer) method for GEBD. Specifically, a transformer decoder module is added after transformer encoders to extract high quality frame features. The final classification is performed jointly on the results of the original binary classifier and a newly introduced multi-class classifier branch. To enrich motion information, optical flow is introduced as a new modality. Finally, model ensemble is used to further boost performance. The proposed method achieves 86.49% F1 score on Kinetics-GEBD test set. which improves 2.86% F1 score compared to the previous SOTA method.
Exploring ensembles and uncertainty minimization in denoising networks
Jan 24, 2021

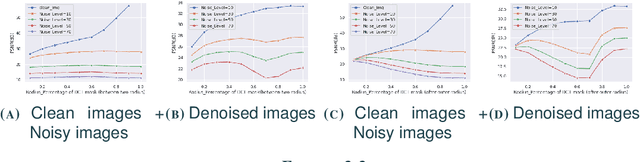

The development of neural networks has greatly improved the performance in various computer vision tasks. In the filed of image denoising, convolutional neural network based methods such as DnCNN break through the limits of classical methods, achieving better quantitative results. However, the epistemic uncertainty existing in neural networks limits further improvements in their performance over denoising tasks. Therefore, we develop and study different solutions to minimize uncertainty and further improve the removal of noise. From the perspective of ensemble learning, we implement manipulations to noisy images from the point of view of spatial and frequency domains and then denoise them using pre-trained denoising networks. We propose a fusion model consisting of two attention modules, which focus on assigning the proper weights to pixels and channels. The experimental results show that our model achieves better performance on top of the baseline of regular pre-trained denoising networks.
Deep Gaussian Denoiser Epistemic Uncertainty and Decoupled Dual-Attention Fusion
Jan 22, 2021

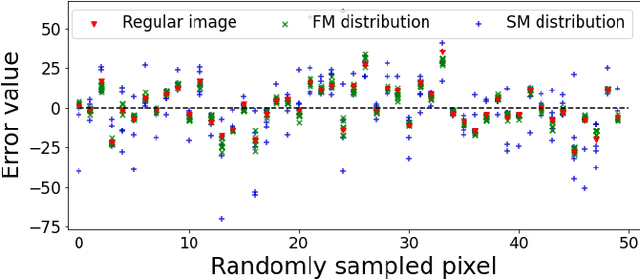

Following the performance breakthrough of denoising networks, improvements have come chiefly through novel architecture designs and increased depth. While novel denoising networks were designed for real images coming from different distributions, or for specific applications, comparatively small improvement was achieved on Gaussian denoising. The denoising solutions suffer from epistemic uncertainty that can limit further advancements. This uncertainty is traditionally mitigated through different ensemble approaches. However, such ensembles are prohibitively costly with deep networks, which are already large in size. Our work focuses on pushing the performance limits of state-of-the-art methods on Gaussian denoising. We propose a model-agnostic approach for reducing epistemic uncertainty while using only a single pretrained network. We achieve this by tapping into the epistemic uncertainty through augmented and frequency-manipulated images to obtain denoised images with varying error. We propose an ensemble method with two decoupled attention paths, over the pixel domain and over that of our different manipulations, to learn the final fusion. Our results significantly improve over the state-of-the-art baselines and across varying noise levels.