 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContract-Coding: Towards Repo-Level Generation via Structured Symbolic Paradigm
Apr 10, 2026The shift toward intent-driven software engineering (often termed "Vibe Coding") exposes a critical Context-Fidelity Trade-off: vague user intents overwhelm linear reasoning chains, leading to architectural collapse in complex repo-level generation. We propose Contract-Coding, a structured symbolic paradigm that bridges unstructured intent and executable code via Autonomous Symbolic Grounding. By projecting ambiguous intents into a formal Language Contract, our framework serves as a Single Source of Truth (SSOT) that enforces topological independence, effectively isolating inter-module implementation details, decreasing topological execution depth and unlocking Architectural Parallelism. Empirically, while state-of-the-art agents suffer from different hallucinations on the Greenfield-5 benchmark, Contract-Coding achieves 47\% functional success while maintaining near-perfect structural integrity. Our work marks a critical step towards repository-scale autonomous engineering: transitioning from strict "specification-following" to robust, intent-driven architecture synthesis. Our code is available at https://github.com/imliinyi/Contract-Coding.
Mixture-of-Depths Attention
Mar 16, 2026Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
Overview of the CXR-LT 2026 Challenge: Multi-Center Long-Tailed and Zero Shot Chest X-ray Classification
Feb 25, 2026Chest X-ray (CXR) interpretation is hindered by the long-tailed distribution of pathologies and the open-world nature of clinical environments. Existing benchmarks often rely on closed-set classes from single institutions, failing to capture the prevalence of rare diseases or the appearance of novel findings. To address this, we present the CXR-LT 2026 challenge. This third iteration of the benchmark introduces a multi-center dataset comprising over 145,000 images from PadChest and NIH Chest X-ray datasets. The challenge defines two core tasks: (1) Robust Multi-Label Classification on 30 known classes and (2) Open-World Generalization to 6 unseen (out-of-distribution) rare disease classes. We report the results of the top-performing teams, evaluating them via mean Average Precision (mAP), AUROC, and F1-score. The winning solutions achieved an mAP of 0.5854 on Task 1 and 0.4315 on Task 2, demonstrating that large-scale vision-language pre-training significantly mitigates the performance drop typically associated with zero-shot diagnosis.
ARGOS: Automated Functional Safety Requirement Synthesis for Embodied AI via Attribute-Guided Combinatorial Reasoning
Jan 30, 2026Ensuring functional safety is essential for the deployment of Embodied AI in complex open-world environments. However, traditional Hazard Analysis and Risk Assessment (HARA) methods struggle to scale in this domain. While HARA relies on enumerating risks for finite and pre-defined function lists, Embodied AI operates on open-ended natural language instructions, creating a challenge of combinatorial interaction risks. Whereas Large Language Models (LLMs) have emerged as a promising solution to this scalability challenge, they often lack physical grounding, yielding semantically superficial and incoherent hazard descriptions. To overcome these limitations, we propose a new framework ARGOS (AttRibute-Guided cOmbinatorial reaSoning), which bridges the gap between open-ended user instructions and concrete physical attributes. By dynamically decomposing entities from instructions into these fine-grained properties, ARGOS grounds LLM reasoning in causal risk factors to generate physically plausible hazard scenarios. It then instantiates abstract safety standards, such as ISO 13482, into context-specific Functional Safety Requirements (FSRs) by integrating these scenarios with robot capabilities. Extensive experiments validate that ARGOS produces high-quality FSRs and outperforms baselines in identifying long-tail risks. Overall, this work paves the way for systematic and grounded functional safety requirement generation, a critical step toward the safe industrial deployment of Embodied AI.
Masked Face Recognition under Different Backbones
Jan 23, 2026Erratum to the paper (Zhang et al., 2025): corrections to Table IV and the data in Page 3, Section A. In the post-pandemic era, a high proportion of civil aviation passengers wear masks during security checks, posing significant challenges to traditional face recognition models. The backbone network serves as the core component of face recognition models. In standard tests, r100 series models excelled (98%+ accuracy at 0.01% FAR in face comparison, high top1/top5 in search). r50 ranked second, r34_mask_v1 lagged. In masked tests, r100_mask_v2 led (90.07% accuracy), r50_mask_v3 performed best among r50 but trailed r100. Vit-Small/Tiny showed strong masked performance with gains in effectiveness. Through extensive comparative experiments, this paper conducts a comprehensive evaluation of several core backbone networks, aiming to reveal the impacts of different models on face recognition with and without masks, and provide specific deployment recommendations.
RSNA Large Language Model Benchmark Dataset for Chest Radiographs of Cardiothoracic Disease: Radiologist Evaluation and Validation Enhanced by AI Labels (REVEAL-CXR)
Jan 21, 2026Multimodal large language models have demonstrated comparable performance to that of radiology trainees on multiple-choice board-style exams. However, to develop clinically useful multimodal LLM tools, high-quality benchmarks curated by domain experts are essential. To curate released and holdout datasets of 100 chest radiographic studies each and propose an artificial intelligence (AI)-assisted expert labeling procedure to allow radiologists to label studies more efficiently. A total of 13,735 deidentified chest radiographs and their corresponding reports from the MIDRC were used. GPT-4o extracted abnormal findings from the reports, which were then mapped to 12 benchmark labels with a locally hosted LLM (Phi-4-Reasoning). From these studies, 1,000 were sampled on the basis of the AI-suggested benchmark labels for expert review; the sampling algorithm ensured that the selected studies were clinically relevant and captured a range of difficulty levels. Seventeen chest radiologists participated, and they marked "Agree all", "Agree mostly" or "Disagree" to indicate their assessment of the correctness of the LLM suggested labels. Each chest radiograph was evaluated by three experts. Of these, at least two radiologists selected "Agree All" for 381 radiographs. From this set, 200 were selected, prioritizing those with less common or multiple finding labels, and divided into 100 released radiographs and 100 reserved as the holdout dataset. The holdout dataset is used exclusively by RSNA to independently evaluate different models. A benchmark of 200 chest radiographic studies with 12 benchmark labels was created and made publicly available https://imaging.rsna.org, with each chest radiograph verified by three radiologists. In addition, an AI-assisted labeling procedure was developed to help radiologists label at scale, minimize unnecessary omissions, and support a semicollaborative environment.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
A Disease-Aware Dual-Stage Framework for Chest X-ray Report Generation
Nov 15, 2025Radiology report generation from chest X-rays is an important task in artificial intelligence with the potential to greatly reduce radiologists' workload and shorten patient wait times. Despite recent advances, existing approaches often lack sufficient disease-awareness in visual representations and adequate vision-language alignment to meet the specialized requirements of medical image analysis. As a result, these models usually overlook critical pathological features on chest X-rays and struggle to generate clinically accurate reports. To address these limitations, we propose a novel dual-stage disease-aware framework for chest X-ray report generation. In Stage~1, our model learns Disease-Aware Semantic Tokens (DASTs) corresponding to specific pathology categories through cross-attention mechanisms and multi-label classification, while simultaneously aligning vision and language representations via contrastive learning. In Stage~2, we introduce a Disease-Visual Attention Fusion (DVAF) module to integrate disease-aware representations with visual features, along with a Dual-Modal Similarity Retrieval (DMSR) mechanism that combines visual and disease-specific similarities to retrieve relevant exemplars, providing contextual guidance during report generation. Extensive experiments on benchmark datasets (i.e., CheXpert Plus, IU X-ray, and MIMIC-CXR) demonstrate that our disease-aware framework achieves state-of-the-art performance in chest X-ray report generation, with significant improvements in clinical accuracy and linguistic quality.
Visual Spatial Tuning
Nov 07, 2025Capturing spatial relationships from visual inputs is a cornerstone of human-like general intelligence. Several previous studies have tried to enhance the spatial awareness of Vision-Language Models (VLMs) by adding extra expert encoders, which brings extra overhead and usually harms general capabilities. To enhance the spatial ability in general architectures, we introduce Visual Spatial Tuning (VST), a comprehensive framework to cultivate VLMs with human-like visuospatial abilities, from spatial perception to reasoning. We first attempt to enhance spatial perception in VLMs by constructing a large-scale dataset termed VST-P, which comprises 4.1 million samples spanning 19 skills across single views, multiple images, and videos. Then, we present VST-R, a curated dataset with 135K samples that instruct models to reason in space. In particular, we adopt a progressive training pipeline: supervised fine-tuning to build foundational spatial knowledge, followed by reinforcement learning to further improve spatial reasoning abilities. Without the side-effect to general capabilities, the proposed VST consistently achieves state-of-the-art results on several spatial benchmarks, including $34.8\%$ on MMSI-Bench and $61.2\%$ on VSIBench. It turns out that the Vision-Language-Action models can be significantly enhanced with the proposed spatial tuning paradigm, paving the way for more physically grounded AI.
UrbanFeel: A Comprehensive Benchmark for Temporal and Perceptual Understanding of City Scenes through Human Perspective
Sep 26, 2025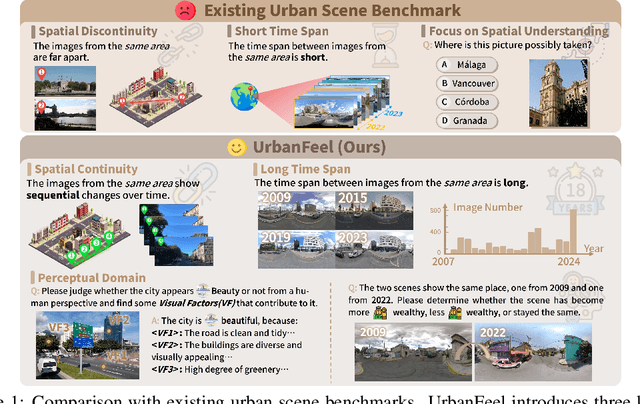
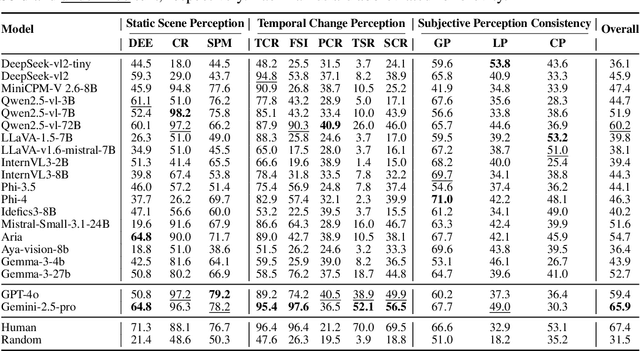

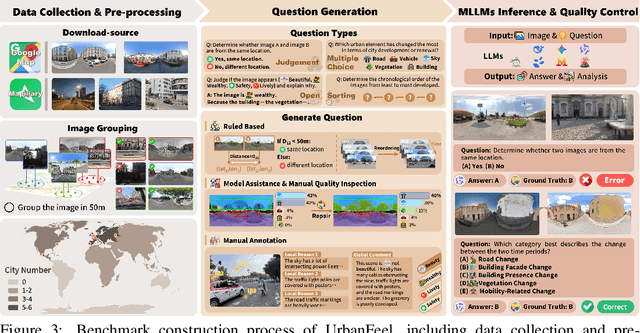
Urban development impacts over half of the global population, making human-centered understanding of its structural and perceptual changes essential for sustainable development. While Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various domains, existing benchmarks that explore their performance in urban environments remain limited, lacking systematic exploration of temporal evolution and subjective perception of urban environment that aligns with human perception. To address these limitations, we propose UrbanFeel, a comprehensive benchmark designed to evaluate the performance of MLLMs in urban development understanding and subjective environmental perception. UrbanFeel comprises 14.3K carefully constructed visual questions spanning three cognitively progressive dimensions: Static Scene Perception, Temporal Change Understanding, and Subjective Environmental Perception. We collect multi-temporal single-view and panoramic street-view images from 11 representative cities worldwide, and generate high-quality question-answer pairs through a hybrid pipeline of spatial clustering, rule-based generation, model-assisted prompting, and manual annotation. Through extensive evaluation of 20 state-of-the-art MLLMs, we observe that Gemini-2.5 Pro achieves the best overall performance, with its accuracy approaching human expert levels and narrowing the average gap to just 1.5\%. Most models perform well on tasks grounded in scene understanding. In particular, some models even surpass human annotators in pixel-level change detection. However, performance drops notably in tasks requiring temporal reasoning over urban development. Additionally, in the subjective perception dimension, several models reach human-level or even higher consistency in evaluating dimension such as beautiful and safety.