 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Self-Evolving Agents via Parametric Memory
Jun 03, 2026Existing memory-augmented LLM agents store past experience exclusively in prompt space, as textual summaries or retrieved passages, while keeping model parameters frozen throughout a rollout. Such agents can \emph{look up} what they have seen but cannot \emph{learn from} it: their policy is unchanged by experience, and any information dropped from the context is permanently lost. We introduce \texttt{TMEM}, a self-evolving parametric memory framework in which the agent not only compresses history into explicit memory but also absorbs distilled supervision into fast LoRA weights $Δ_t$ via lightweight online updates, genuinely altering its future behavior within a single episode. We formalize this as an agentic decision process with fast-weight rollout dynamics: actions are sampled from $π_{θ_0+Δ_t}$, while extraction actions produce supervision that updates $Δ_t$ for subsequent decisions. This view makes the extraction policy directly optimizable by RL: training $θ_0$ improves not only task actions but also the quality of the data used for online LoRA adaptation. We further propose SVD-based initialization of the LoRA subspace to accelerate online convergence. Experiments on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench show that \texttt{TMEM} consistently outperforms summary-based and retrieval-based baselines across different model scales.
Fine-Tuned LLM as a Complementary Predictor Improving Ads System
May 27, 2026Recommendation systems power engagement and monetization across feeds, ads, and short-video platforms, but translating the latest advances in Large Language Models into Recommendation Systems (RecSys) gains remains rare, particularly in advertising and production-scale real-world industry setups. Prior real-world LLM successes typically fall into three buckets: (a) generative retrieval that directly predicts the next items for candidate generation, (b) late-stage re-ranking that uses LLMs, and (c) auxiliary signal enrichment with LLMs. We introduce a complementary paradigm for ads: a fine-tuned open-source LLM used not as a ranker, but as an ads-specific ancillary predictor, forecasting likely advertisers from user profiles and histories. This LLM-driven advertiser prediction augments conventional candidate generation and provides informative priors to downstream ranking. Developed in a large-scale production advertising system, our approach produces substantial offline improvements and measurable online business impact, demonstrating that LLM world knowledge and predictive capacity can be efficiently harnessed. Beyond validating LLMs for ads applications, our results show that targeted ancillary predictions can unlock end-to-end gains across both retrieval and late-stage ranking, offering a practical path to LLM-enhanced recommendation at scale.
Machine Learning-Assisted High-Dimensional Matrix Estimation
Mar 30, 2026Efficient estimation of high-dimensional matrices-including covariance and precision matrices-is a cornerstone of modern multivariate statistics. Most existing studies have focused primarily on the theoretical properties of the estimators (e.g., consistency and sparsity), while largely overlooking the computational challenges inherent in high-dimensional settings. Motivated by recent advances in learning-based optimization method-which integrate data-driven structures with classical optimization algorithms-we explore high-dimensional matrix estimation assisted by machine learning. Specifically, for the optimization problem of high-dimensional matrix estimation, we first present a solution procedure based on the Linearized Alternating Direction Method of Multipliers (LADMM). We then introduce learnable parameters and model the proximal operators in the iterative scheme with neural networks, thereby improving estimation accuracy and accelerating convergence. Theoretically, we first prove the convergence of LADMM, and then establish the convergence, convergence rate, and monotonicity of its reparameterized counterpart; importantly, we show that the reparameterized LADMM enjoys a faster convergence rate. Notably, the proposed reparameterization theory and methodology are applicable to the estimation of both high-dimensional covariance and precision matrices. We validate the effectiveness of our method by comparing it with several classical optimization algorithms across different structures and dimensions of high-dimensional matrices.
Adaptive Robust Estimator for Multi-Agent Reinforcement Learning
Mar 23, 2026Multi-agent collaboration has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models, yet it suffers from interaction-level ambiguity that blurs generation, critique, and revision, making credit assignment across agents difficult. Moreover, policy optimization in this setting is vulnerable to heavy-tailed and noisy rewards, which can bias advantage estimation and trigger unstable or even divergent training. To address both issues, we propose a robust multi-agent reinforcement learning framework for collaborative reasoning, consisting of two components: Dual-Agent Answer-Critique-Rewrite (DACR) and an Adaptive Robust Estimator (ARE). DACR decomposes reasoning into a structured three-stage pipeline: answer, critique, and rewrite, while enabling explicit attribution of each agent's marginal contribution to its partner's performance. ARE provides robust estimation of batch experience means during multi-agent policy optimization. Across mathematical reasoning and embodied intelligence benchmarks, even under noisy rewards, our method consistently outperforms the baseline in both homogeneous and heterogeneous settings. These results indicate stronger robustness to reward noise and more stable training dynamics, effectively preventing optimization failures caused by noisy reward signals.
Generalized Hand-Object Pose Estimation with Occlusion Awareness
Mar 19, 2026Generalized 3D hand-object pose estimation from a single RGB image remains challenging due to the large variations in object appearances and interaction patterns, especially under heavy occlusion. We propose GenHOI, a framework for generalized hand-object pose estimation with occlusion awareness. GenHOI integrates hierarchical semantic knowledge with hand priors to enhance model generalization under challenging occlusion conditions. Specifically, we introduce a hierarchical semantic prompt that encodes object states, hand configurations, and interaction patterns via textual descriptions. This enables the model to learn abstract high-level representations of hand-object interactions for generalization to unseen objects and novel interactions while compensating for missing or ambiguous visual cues. To enable robust occlusion reasoning, we adopt a multi-modal masked modeling strategy over RGB images, predicted point clouds, and textual descriptions. Moreover, we leverage hand priors as stable spatial references to extract implicit interaction constraints. This allows reliable pose inference even under significant variations in object shapes and interaction patterns. Extensive experiments on the challenging DexYCB and HO3Dv2 benchmarks demonstrate that our method achieves state-of-the-art performance in hand-object pose estimation.
STEM Faculty Perspectives on Generative AI in Higher Education
Mar 04, 2026Generative artificial intelligence (GenAI) tools are increasingly present in higher education, yet their adoption has been largely student-driven, requiring instructors to respond to technologies already embedded in classroom practices. While some faculty have embraced GenAI for pedagogical purposes such as content generation, assessment support, and curriculum design, others approach these tools with caution, citing concerns about student learning, assessment validity, and academic integrity. Understanding faculty perspectives is therefore essential for informing effective pedagogical strategies and institutional policies. In this paper, we present findings from a focus group study with 29 STEM faculty members at a large public university in the United States. We examine how faculty integrate GenAI into their courses, the benefits and challenges they perceive for student learning, and the institutional support they identify as necessary for effective and responsible adoption. Our findings highlight key patterns in how STEM faculty engage with GenAI, reflecting both active adoption and cautious use. Faculty described a range of pedagogical applications alongside concerns about student learning, assessment, and academic integrity. Overall, the results suggest that effective integration of GenAI in higher education requires rethinking assessment, pedagogy, and institutional governance in addition to technical adoption.
Global-Local Dual Perception for MLLMs in High-Resolution Text-Rich Image Translation
Feb 25, 2026Text Image Machine Translation (TIMT) aims to translate text embedded in images in the source-language into target-language, requiring synergistic integration of visual perception and linguistic understanding. Existing TIMT methods, whether cascaded pipelines or end-to-end multimodal large language models (MLLMs),struggle with high-resolution text-rich images due to cluttered layouts, diverse fonts, and non-textual distractions, resulting in text omission, semantic drift, and contextual inconsistency. To address these challenges, we propose GLoTran, a global-local dual visual perception framework for MLLM-based TIMT. GLoTran integrates a low-resolution global image with multi-scale region-level text image slices under an instruction-guided alignment strategy, conditioning MLLMs to maintain scene-level contextual consistency while faithfully capturing fine-grained textual details. Moreover, to realize this dual-perception paradigm, we construct GLoD, a large-scale text-rich TIMT dataset comprising 510K high-resolution global-local image-text pairs covering diverse real-world scenarios. Extensive experiments demonstrate that GLoTran substantially improves translation completeness and accuracy over state-of-the-art MLLMs, offering a new paradigm for fine-grained TIMT under high-resolution and text-rich conditions.
Large Language Model for OWL Proofs
Jan 18, 2026The ability of Large Language Models (LLMs) to perform reasoning tasks such as deduction has been widely investigated in recent years. Yet, their capacity to generate proofs-faithful, human-readable explanations of why conclusions follow-remains largely under explored. In this work, we study proof generation in the context of OWL ontologies, which are widely adopted for representing and reasoning over complex knowledge, by developing an automated dataset construction and evaluation framework. Our evaluation encompassing three sequential tasks for complete proving: Extraction, Simplification, and Explanation, as well as an additional task of assessing Logic Completeness of the premise. Through extensive experiments on widely used reasoning LLMs, we achieve important findings including: (1) Some models achieve overall strong results but remain limited on complex cases; (2) Logical complexity, rather than representation format (formal logic language versus natural language), is the dominant factor shaping LLM performance; and (3) Noise and incompleteness in input data substantially diminish LLMs' performance. Together, these results underscore both the promise of LLMs for explanation with rigorous logics and the gap of supporting resilient reasoning under complex or imperfect conditions. Code and data are available at https://github.com/HuiYang1997/LLMOwlR.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025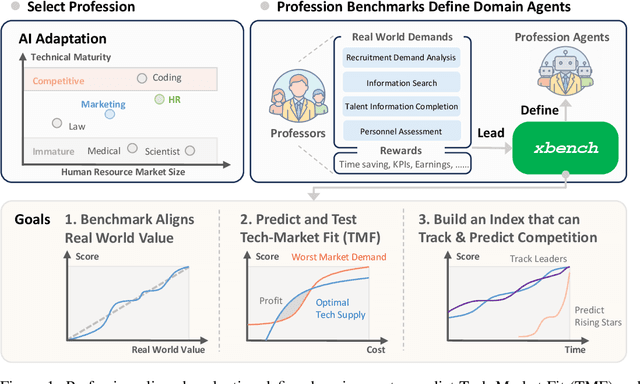

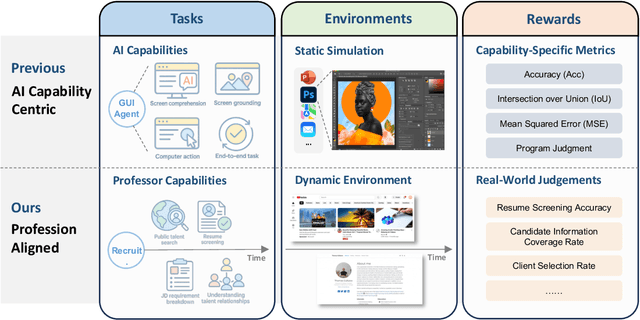
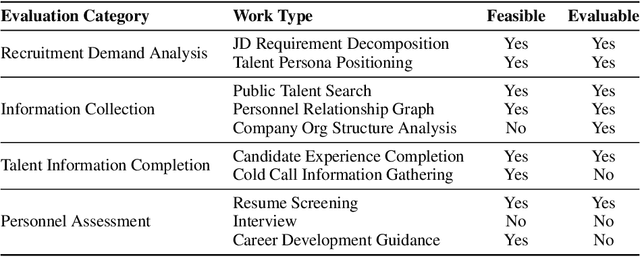
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
Occlusion-Aware 3D Hand-Object Pose Estimation with Masked AutoEncoders
Jun 12, 2025Hand-object pose estimation from monocular RGB images remains a significant challenge mainly due to the severe occlusions inherent in hand-object interactions. Existing methods do not sufficiently explore global structural perception and reasoning, which limits their effectiveness in handling occluded hand-object interactions. To address this challenge, we propose an occlusion-aware hand-object pose estimation method based on masked autoencoders, termed as HOMAE. Specifically, we propose a target-focused masking strategy that imposes structured occlusion on regions of hand-object interaction, encouraging the model to learn context-aware features and reason about the occluded structures. We further integrate multi-scale features extracted from the decoder to predict a signed distance field (SDF), capturing both global context and fine-grained geometry. To enhance geometric perception, we combine the implicit SDF with an explicit point cloud derived from the SDF, leveraging the complementary strengths of both representations. This fusion enables more robust handling of occluded regions by combining the global context from the SDF with the precise local geometry provided by the point cloud. Extensive experiments on challenging DexYCB and HO3Dv2 benchmarks demonstrate that HOMAE achieves state-of-the-art performance in hand-object pose estimation. We will release our code and model.