 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Dimension Dependence for Bandit Convex Optimization with Gradient Variations
Feb 04, 2026Gradient-variation online learning has drawn increasing attention due to its deep connections to game theory, optimization, etc. It has been studied extensively in the full-information setting, but is underexplored with bandit feedback. In this work, we focus on gradient variation in Bandit Convex Optimization (BCO) with two-point feedback. By proposing a refined analysis on the non-consecutive gradient variation, a fundamental quantity in gradient variation with bandits, we improve the dimension dependence for both convex and strongly convex functions compared with the best known results (Chiang et al., 2013). Our improved analysis for the non-consecutive gradient variation also implies other favorable problem-dependent guarantees, such as gradient-variance and small-loss regrets. Beyond the two-point setup, we demonstrate the versatility of our technique by achieving the first gradient-variation bound for one-point bandit linear optimization over hyper-rectangular domains. Finally, we validate the effectiveness of our results in more challenging tasks such as dynamic/universal regret minimization and bandit games, establishing the first gradient-variation dynamic and universal regret bounds for two-point BCO and fast convergence rates in bandit games.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
A New Paradigm for Trusted Respiratory Monitoring Via Consumer Electronics-grade Radar Signals
Jan 22, 2026Respiratory monitoring is an extremely important task in modern medical services. Due to its significant advantages, e.g., non-contact, radar-based respiratory monitoring has attracted widespread attention from both academia and industry. Unfortunately, though it can achieve high monitoring accuracy, consumer electronics-grade radar data inevitably contains User-sensitive Identity Information (USI), which may be maliciously used and further lead to privacy leakage. To track these challenges, by variational mode decomposition (VMD) and adversarial loss-based encryption, we propose a novel Trusted Respiratory Monitoring paradigm, Tru-RM, to perform automated respiratory monitoring through radio signals while effectively anonymizing USI. The key enablers of Tru-RM are Attribute Feature Decoupling (AFD), Flexible Perturbation Encryptor (FPE), and robust Perturbation Tolerable Network (PTN) used for attribute decomposition, identity encryption, and perturbed respiratory monitoring, respectively. Specifically, AFD is designed to decompose the raw radar signals into the universal respiratory component, the personal difference component, and other unrelated components. Then, by using large noise to drown out the other unrelated components, and the phase noise algorithm with a learning intensity parameter to eliminate USI in the personal difference component, FPE is designed to achieve complete user identity information encryption without affecting respiratory features. Finally, by designing the transferred generalized domain-independent network, PTN is employed to accurately detect respiration when waveforms change significantly. Extensive experiments based on various detection distances, respiratory patterns, and durations demonstrate the superior performance of Tru-RM on strong anonymity of USI, and high detection accuracy of perturbed respiratory waveforms.
Breaking Coordinate Overfitting: Geometry-Aware WiFi Sensing for Cross-Layout 3D Pose Estimation
Jan 18, 2026WiFi-based 3D human pose estimation offers a low-cost and privacy-preserving alternative to vision-based systems for smart interaction. However, existing approaches rely on visual 3D poses as supervision and directly regress CSI to a camera-based coordinate system. We find that this practice leads to coordinate overfitting: models memorize deployment-specific WiFi transceiver layouts rather than only learning activity-relevant representations, resulting in severe generalization failures. To address this challenge, we present PerceptAlign, the first geometry-conditioned framework for WiFi-based cross-layout pose estimation. PerceptAlign introduces a lightweight coordinate unification procedure that aligns WiFi and vision measurements in a shared 3D space using only two checkerboards and a few photos. Within this unified space, it encodes calibrated transceiver positions into high-dimensional embeddings and fuses them with CSI features, making the model explicitly aware of device geometry as a conditional variable. This design forces the network to disentangle human motion from deployment layouts, enabling robust and, for the first time, layout-invariant WiFi pose estimation. To support systematic evaluation, we construct the largest cross-domain 3D WiFi pose estimation dataset to date, comprising 21 subjects, 5 scenes, 18 actions, and 7 device layouts. Experiments show that PerceptAlign reduces in-domain error by 12.3% and cross-domain error by more than 60% compared to state-of-the-art baselines. These results establish geometry-conditioned learning as a viable path toward scalable and practical WiFi sensing.
d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation
Jan 12, 2026Diffusion large language models (dLLMs) offer capabilities beyond those of autoregressive (AR) LLMs, such as parallel decoding and random-order generation. However, realizing these benefits in practice is non-trivial, as dLLMs inherently face an accuracy-parallelism trade-off. Despite increasing interest, existing methods typically focus on only one-side of the coin, targeting either efficiency or performance. To address this limitation, we propose d3LLM (Pseudo-Distilled Diffusion Large Language Model), striking a balance between accuracy and parallelism: (i) during training, we introduce pseudo-trajectory distillation to teach the model which tokens can be decoded confidently at early steps, thereby improving parallelism; (ii) during inference, we employ entropy-based multi-block decoding with a KV-cache refresh mechanism to achieve high parallelism while maintaining accuracy. To better evaluate dLLMs, we also introduce AUP (Accuracy Under Parallelism), a new metric that jointly measures accuracy and parallelism. Experiments demonstrate that our d3LLM achieves up to 10$\times$ speedup over vanilla LLaDA/Dream and 5$\times$ speedup over AR models without much accuracy drop. Our code is available at https://github.com/hao-ai-lab/d3LLM.
A Simple, Optimal and Efficient Algorithm for Online Exp-Concave Optimization
Dec 29, 2025Online eXp-concave Optimization (OXO) is a fundamental problem in online learning. The standard algorithm, Online Newton Step (ONS), balances statistical optimality and computational practicality, guaranteeing an optimal regret of $O(d \log T)$, where $d$ is the dimension and $T$ is the time horizon. ONS faces a computational bottleneck due to the Mahalanobis projections at each round. This step costs $Ω(d^ω)$ arithmetic operations for bounded domains, even for the unit ball, where $ω\in (2,3]$ is the matrix-multiplication exponent. As a result, the total runtime can reach $\tilde{O}(d^ωT)$, particularly when iterates frequently oscillate near the domain boundary. For Stochastic eXp-concave Optimization (SXO), computational cost is also a challenge. Deploying ONS with online-to-batch conversion for SXO requires $T = \tilde{O}(d/ε)$ rounds to achieve an excess risk of $ε$, and thereby necessitates an $\tilde{O}(d^{ω+1}/ε)$ runtime. A COLT'13 open problem posed by Koren [2013] asks for an SXO algorithm with runtime less than $\tilde{O}(d^{ω+1}/ε)$. This paper proposes a simple variant of ONS, LightONS, which reduces the total runtime to $O(d^2 T + d^ω\sqrt{T \log T})$ while preserving the optimal $O(d \log T)$ regret. LightONS implies an SXO method with runtime $\tilde{O}(d^3/ε)$, thereby answering the open problem. Importantly, LightONS preserves the elegant structure of ONS by leveraging domain-conversion techniques from parameter-free online learning to introduce a hysteresis mechanism that delays expensive Mahalanobis projections until necessary. This design enables LightONS to serve as an efficient plug-in replacement of ONS in broader scenarios, even beyond regret minimization, including gradient-norm adaptive regret, parametric stochastic bandits, and memory-efficient online learning.
Optimistic Online-to-Batch Conversions for Accelerated Convergence and Universality
Nov 10, 2025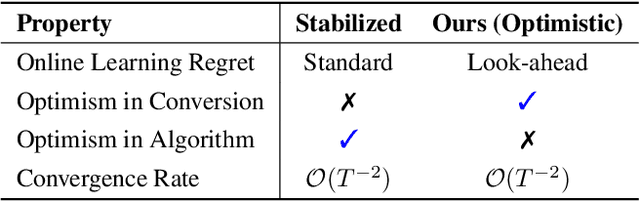
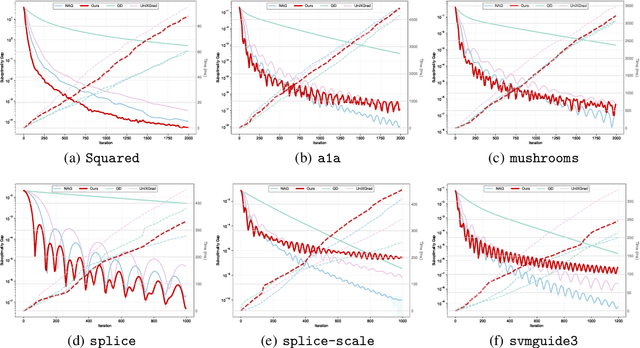
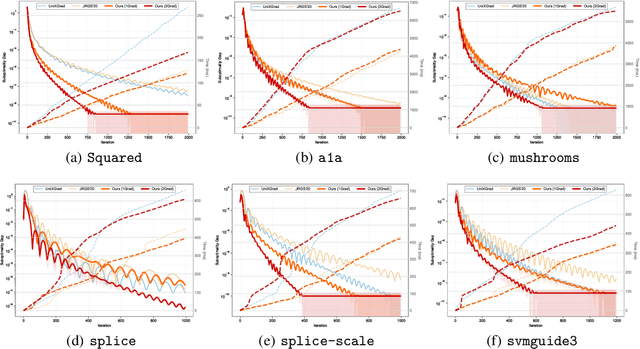
In this work, we study offline convex optimization with smooth objectives, where the classical Nesterov's Accelerated Gradient (NAG) method achieves the optimal accelerated convergence. Extensive research has aimed to understand NAG from various perspectives, and a recent line of work approaches this from the viewpoint of online learning and online-to-batch conversion, emphasizing the role of optimistic online algorithms for acceleration. In this work, we contribute to this perspective by proposing novel optimistic online-to-batch conversions that incorporate optimism theoretically into the analysis, thereby significantly simplifying the online algorithm design while preserving the optimal convergence rates. Specifically, we demonstrate the effectiveness of our conversions through the following results: (i) when combined with simple online gradient descent, our optimistic conversion achieves the optimal accelerated convergence; (ii) our conversion also applies to strongly convex objectives, and by leveraging both optimistic online-to-batch conversion and optimistic online algorithms, we achieve the optimal accelerated convergence rate for strongly convex and smooth objectives, for the first time through the lens of online-to-batch conversion; (iii) our optimistic conversion can achieve universality to smoothness -- applicable to both smooth and non-smooth objectives without requiring knowledge of the smoothness coefficient -- and remains efficient as non-universal methods by using only one gradient query in each iteration. Finally, we highlight the effectiveness of our optimistic online-to-batch conversions by a precise correspondence with NAG.
TCIP: Threshold-Controlled Iterative Pyramid Network for Deformable Medical Image Registration
Oct 09, 2025Although pyramid networks have demonstrated superior performance in deformable medical image registration, their decoder architectures are inherently prone to propagating and accumulating anatomical structure misalignments. Moreover, most existing models do not adaptively determine the number of iterations for optimization under varying deformation requirements across images, resulting in either premature termination or excessive iterations that degrades registration accuracy. To effectively mitigate the accumulation of anatomical misalignments, we propose the Feature-Enhanced Residual Module (FERM) as the core component of each decoding layer in the pyramid network. FERM comprises three sequential blocks that extract anatomical semantic features, learn to suppress irrelevant features, and estimate the final deformation field, respectively. To adaptively determine the number of iterations for varying images, we propose the dual-stage Threshold-Controlled Iterative (TCI) strategy. In the first stage, TCI assesses registration stability and with asserted stability, it continues with the second stage to evaluate convergence. We coin the model that integrates FERM and TCI as Threshold-Controlled Iterative Pyramid (TCIP). Extensive experiments on three public brain MRI datasets and one abdomen CT dataset demonstrate that TCIP outperforms the state-of-the-art (SOTA) registration networks in terms of accuracy, while maintaining comparable inference speed and a compact model parameter size. Finally, we assess the generalizability of FERM and TCI by integrating them with existing registration networks and further conduct ablation studies to validate the effectiveness of these two proposed methods.
Parameter-free Algorithms for the Stochastically Extended Adversarial Model
Oct 06, 2025

We develop the first parameter-free algorithms for the Stochastically Extended Adversarial (SEA) model, a framework that bridges adversarial and stochastic online convex optimization. Existing approaches for the SEA model require prior knowledge of problem-specific parameters, such as the diameter of the domain $D$ and the Lipschitz constant of the loss functions $G$, which limits their practical applicability. Addressing this, we develop parameter-free methods by leveraging the Optimistic Online Newton Step (OONS) algorithm to eliminate the need for these parameters. We first establish a comparator-adaptive algorithm for the scenario with unknown domain diameter but known Lipschitz constant, achieving an expected regret bound of $\tilde{O}\big(\|u\|_2^2 + \|u\|_2(\sqrt{\sigma^2_{1:T}} + \sqrt{\Sigma^2_{1:T}})\big)$, where $u$ is the comparator vector and $\sigma^2_{1:T}$ and $\Sigma^2_{1:T}$ represent the cumulative stochastic variance and cumulative adversarial variation, respectively. We then extend this to the more general setting where both $D$ and $G$ are unknown, attaining the comparator- and Lipschitz-adaptive algorithm. Notably, the regret bound exhibits the same dependence on $\sigma^2_{1:T}$ and $\Sigma^2_{1:T}$, demonstrating the efficacy of our proposed methods even when both parameters are unknown in the SEA model.