 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Space? Vision-Language Models Struggle with Relative Camera Pose Estimation
Jan 29, 2026Vision-Language Models (VLMs) perform well in 2D perception and semantic reasoning compared to their limited understanding of 3D spatial structure. We investigate this gap using relative camera pose estimation (RCPE), a fundamental vision task that requires inferring relative camera translation and rotation from a pair of images. We introduce VRRPI-Bench, a benchmark derived from unlabeled egocentric videos with verbalized annotations of relative camera motion, reflecting realistic scenarios with simultaneous translation and rotation around a shared object. We further propose VRRPI-Diag, a diagnostic benchmark that isolates individual motion degrees of freedom. Despite the simplicity of RCPE, most VLMs fail to generalize beyond shallow 2D heuristics, particularly for depth changes and roll transformations along the optical axis. Even state-of-the-art models such as GPT-5 ($0.64$) fall short of classic geometric baselines ($0.97$) and human performance ($0.92$). Moreover, VLMs exhibit difficulty in multi-image reasoning, with inconsistent performance (best $59.7\%$) when integrating spatial cues across frames. Our findings reveal limitations in grounding VLMs in 3D and multi-view spatial reasoning.
ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
Jan 26, 2026Large language model (LLM)-based agents are increasingly deployed in e-commerce shopping. To perform thorough, user-tailored product searches, agents should interpret personal preferences, engage in multi-turn dialogues, and ultimately retrieve and discriminate among highly similar products. However, existing research has yet to provide a unified simulation environment that consistently captures all of these aspects, and always focuses solely on evaluation benchmarks without training support. In this paper, we introduce ShopSimulator, a large-scale and challenging Chinese shopping environment. Leveraging ShopSimulator, we evaluate LLMs across diverse scenarios, finding that even the best-performing models achieve less than 40% full-success rate. Error analysis reveals that agents struggle with deep search and product selection in long trajectories, fail to balance the use of personalization cues, and to effectively engage with users. Further training exploration provides practical guidance for overcoming these weaknesses, with the combination of supervised fine-tuning (SFT) and reinforcement learning (RL) yielding significant performance improvements. Code and data will be released at https://github.com/ShopAgent-Team/ShopSimulator.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
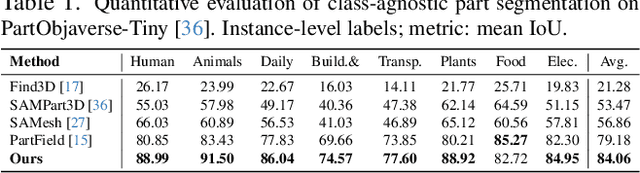
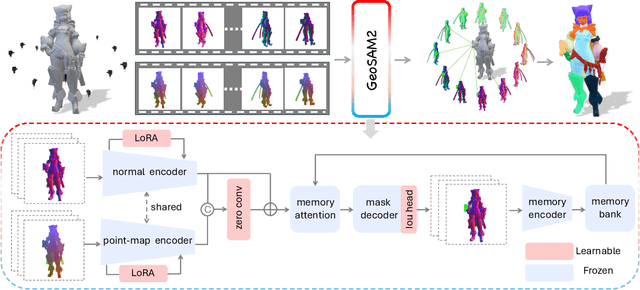
GeoSAM2: Unleashing the Power of SAM2 for 3D Part Segmentation
Aug 19, 2025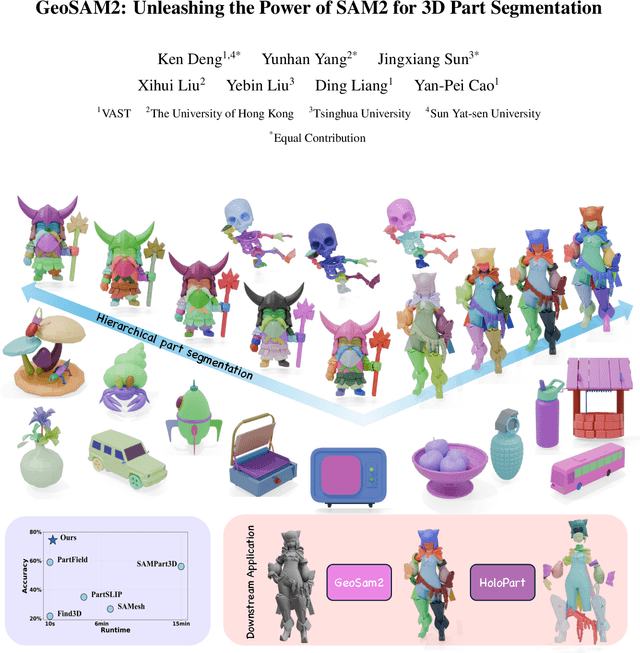

Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models
Feb 23, 2025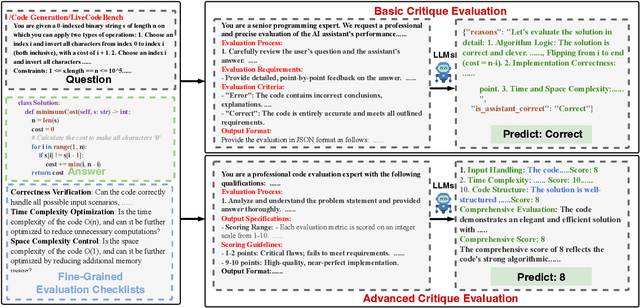
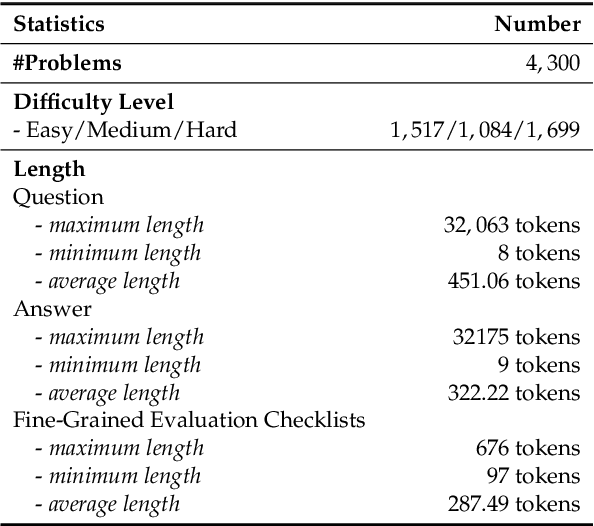

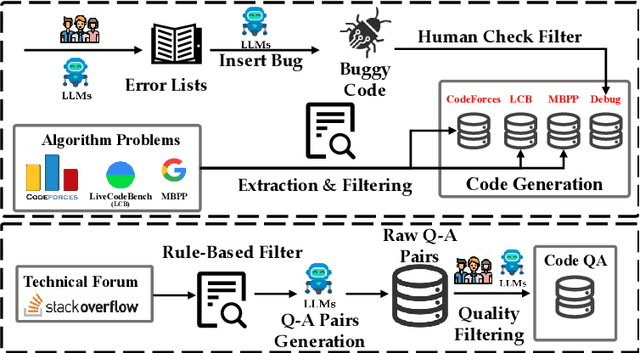
The critique capacity of Large Language Models (LLMs) is essential for reasoning abilities, which can provide necessary suggestions (e.g., detailed analysis and constructive feedback). Therefore, how to evaluate the critique capacity of LLMs has drawn great attention and several critique benchmarks have been proposed. However, existing critique benchmarks usually have the following limitations: (1). Focusing on diverse reasoning tasks in general domains and insufficient evaluation on code tasks (e.g., only covering code generation task), where the difficulty of queries is relatively easy (e.g., the code queries of CriticBench are from Humaneval and MBPP). (2). Lacking comprehensive evaluation from different dimensions. To address these limitations, we introduce a holistic code critique benchmark for LLMs called CodeCriticBench. Specifically, our CodeCriticBench includes two mainstream code tasks (i.e., code generation and code QA) with different difficulties. Besides, the evaluation protocols include basic critique evaluation and advanced critique evaluation for different characteristics, where fine-grained evaluation checklists are well-designed for advanced settings. Finally, we conduct extensive experimental results of existing LLMs, which show the effectiveness of CodeCriticBench.
ExecRepoBench: Multi-level Executable Code Completion Evaluation
Dec 16, 2024



Code completion has become an essential tool for daily software development. Existing evaluation benchmarks often employ static methods that do not fully capture the dynamic nature of real-world coding environments and face significant challenges, including limited context length, reliance on superficial evaluation metrics, and potential overfitting to training datasets. In this work, we introduce a novel framework for enhancing code completion in software development through the creation of a repository-level benchmark ExecRepoBench and the instruction corpora Repo-Instruct, aim at improving the functionality of open-source large language models (LLMs) in real-world coding scenarios that involve complex interdependencies across multiple files. ExecRepoBench includes 1.2K samples from active Python repositories. Plus, we present a multi-level grammar-based completion methodology conditioned on the abstract syntax tree to mask code fragments at various logical units (e.g. statements, expressions, and functions). Then, we fine-tune the open-source LLM with 7B parameters on Repo-Instruct to produce a strong code completion baseline model Qwen2.5-Coder-Instruct-C based on the open-source model. Qwen2.5-Coder-Instruct-C is rigorously evaluated against existing benchmarks, including MultiPL-E and ExecRepoBench, which consistently outperforms prior baselines across all programming languages. The deployment of \ourmethod{} can be used as a high-performance, local service for programming development\footnote{\url{https://execrepobench.github.io/}}.
DetailGen3D: Generative 3D Geometry Enhancement via Data-Dependent Flow
Nov 25, 2024Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
M2rc-Eval: Massively Multilingual Repository-level Code Completion Evaluation
Oct 28, 2024



Repository-level code completion has drawn great attention in software engineering, and several benchmark datasets have been introduced. However, existing repository-level code completion benchmarks usually focus on a limited number of languages (<5), which cannot evaluate the general code intelligence abilities across different languages for existing code Large Language Models (LLMs). Besides, the existing benchmarks usually report overall average scores of different languages, where the fine-grained abilities in different completion scenarios are ignored. Therefore, to facilitate the research of code LLMs in multilingual scenarios, we propose a massively multilingual repository-level code completion benchmark covering 18 programming languages (called M2RC-EVAL), and two types of fine-grained annotations (i.e., bucket-level and semantic-level) on different completion scenarios are provided, where we obtain these annotations based on the parsed abstract syntax tree. Moreover, we also curate a massively multilingual instruction corpora M2RC- INSTRUCT dataset to improve the repository-level code completion abilities of existing code LLMs. Comprehensive experimental results demonstrate the effectiveness of our M2RC-EVAL and M2RC-INSTRUCT.
MTU-Bench: A Multi-granularity Tool-Use Benchmark for Large Language Models
Oct 15, 2024
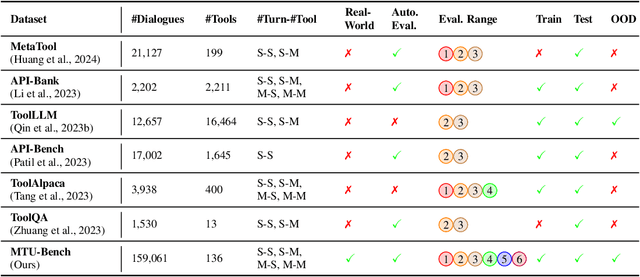
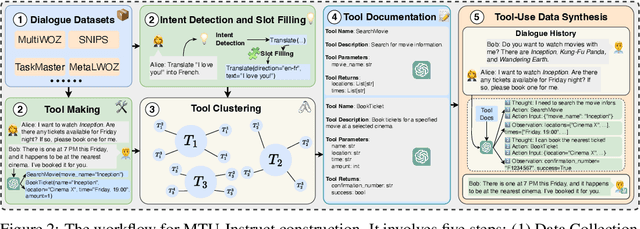
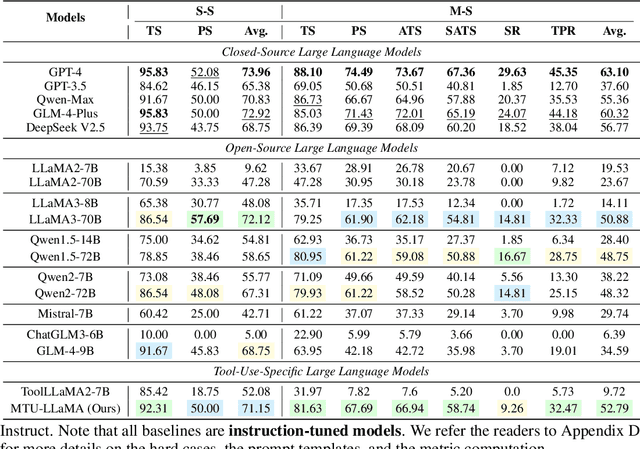
Large Language Models (LLMs) have displayed massive improvements in reasoning and decision-making skills and can hold natural conversations with users. Recently, many tool-use benchmark datasets have been proposed. However, existing datasets have the following limitations: (1). Insufficient evaluation scenarios (e.g., only cover limited tool-use scenes). (2). Extensive evaluation costs (e.g., GPT API costs). To address these limitations, in this work, we propose a multi-granularity tool-use benchmark for large language models called MTU-Bench. For the "multi-granularity" property, our MTU-Bench covers five tool usage scenes (i.e., single-turn and single-tool, single-turn and multiple-tool, multiple-turn and single-tool, multiple-turn and multiple-tool, and out-of-distribution tasks). Besides, all evaluation metrics of our MTU-Bench are based on the prediction results and the ground truth without using any GPT or human evaluation metrics. Moreover, our MTU-Bench is collected by transforming existing high-quality datasets to simulate real-world tool usage scenarios, and we also propose an instruction dataset called MTU-Instruct data to enhance the tool-use abilities of existing LLMs. Comprehensive experimental results demonstrate the effectiveness of our MTU-Bench. Code and data will be released at https: //github.com/MTU-Bench-Team/MTU-Bench.git.
DDK: Distilling Domain Knowledge for Efficient Large Language Models
Jul 23, 2024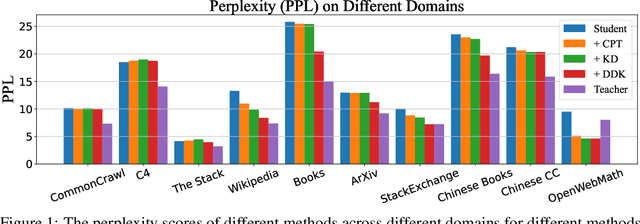
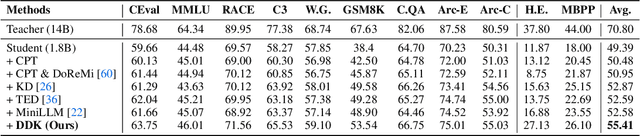
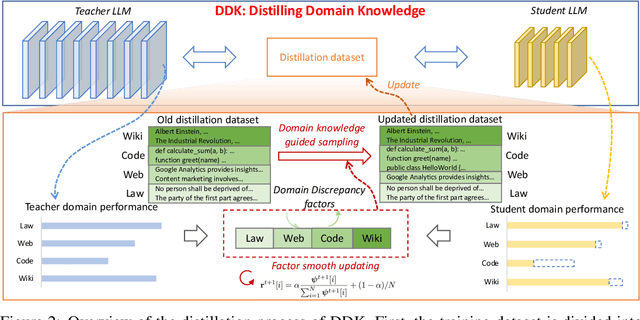
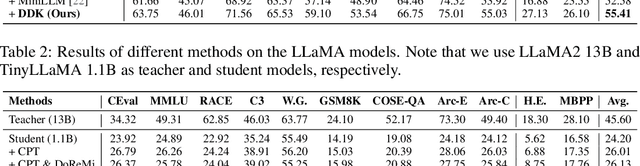
Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets, or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM. However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance. In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective. Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.