 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiff4D: Geometry-Aware Diffusion for 4D Head Avatar Reconstruction
Feb 27, 2026Reconstructing photorealistic and animatable 4D head avatars from a single portrait image remains a fundamental challenge in computer vision. While diffusion models have enabled remarkable progress in image and video generation for avatar reconstruction, existing methods primarily rely on 2D priors and struggle to achieve consistent 3D geometry. We propose a novel framework that leverages geometry-aware diffusion to learn strong geometry priors for high-fidelity head avatar reconstruction. Our approach jointly synthesizes portrait images and corresponding surface normals, while a pose-free expression encoder captures implicit expression representations. Both synthesized images and expression latents are incorporated into 3D Gaussian-based avatars, enabling photorealistic rendering with accurate geometry. Extensive experiments demonstrate that our method substantially outperforms state-of-the-art approaches in visual quality, expression fidelity, and cross-identity generalization, while supporting real-time rendering.
VTok: A Unified Video Tokenizer with Decoupled Spatial-Temporal Latents
Feb 04, 2026This work presents VTok, a unified video tokenization framework that can be used for both generation and understanding tasks. Unlike the leading vision-language systems that tokenize videos through a naive frame-sampling strategy, we propose to decouple the spatial and temporal representations of videos by retaining the spatial features of a single key frame while encoding each subsequent frame into a single residual token, achieving compact yet expressive video tokenization. Our experiments suggest that VTok effectively reduces the complexity of video representation from the product of frame count and per-frame token count to their sum, while the residual tokens sufficiently capture viewpoint and motion changes relative to the key frame. Extensive evaluations demonstrate the efficacy and efficiency of VTok: it achieves notably higher performance on a range of video understanding and text-to-video generation benchmarks compared with baselines using naive tokenization, all with shorter token sequences per video (e.g., 3.4% higher accuracy on our TV-Align benchmark and 1.9% higher VBench score). Remarkably, VTok produces more coherent motion and stronger guidance following in text-to-video generation, owing to its more consistent temporal encoding. We hope VTok can serve as a standardized video tokenization paradigm for future research in video understanding and generation.
FlexAvatar: Flexible Large Reconstruction Model for Animatable Gaussian Head Avatars with Detailed Deformation
Dec 19, 2025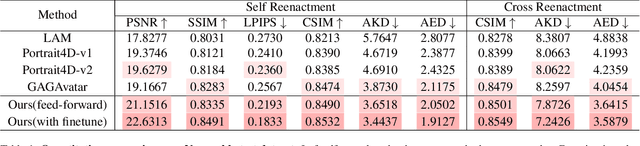
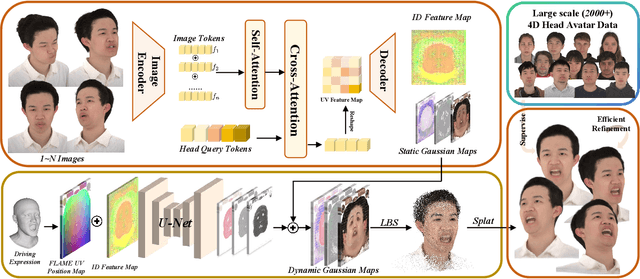
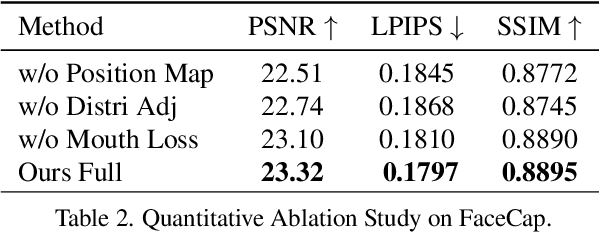

We present FlexAvatar, a flexible large reconstruction model for high-fidelity 3D head avatars with detailed dynamic deformation from single or sparse images, without requiring camera poses or expression labels. It leverages a transformer-based reconstruction model with structured head query tokens as canonical anchor to aggregate flexible input-number-agnostic, camera-pose-free and expression-free inputs into a robust canonical 3D representation. For detailed dynamic deformation, we introduce a lightweight UNet decoder conditioned on UV-space position maps, which can produce detailed expression-dependent deformations in real time. To better capture rare but critical expressions like wrinkles and bared teeth, we also adopt a data distribution adjustment strategy during training to balance the distribution of these expressions in the training set. Moreover, a lightweight 10-second refinement can further enhances identity-specific details in extreme identities without affecting deformation quality. Extensive experiments demonstrate that our FlexAvatar achieves superior 3D consistency, detailed dynamic realism compared with previous methods, providing a practical solution for animatable 3D avatar creation.
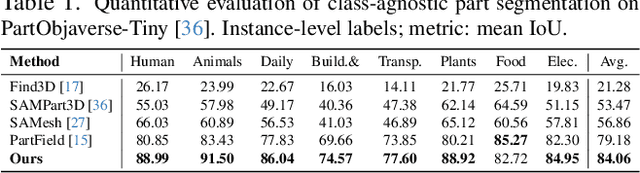
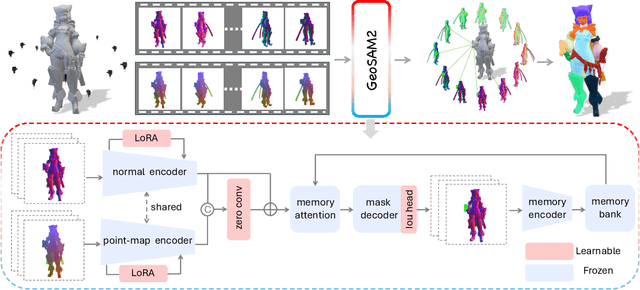
GeoSAM2: Unleashing the Power of SAM2 for 3D Part Segmentation
Aug 19, 2025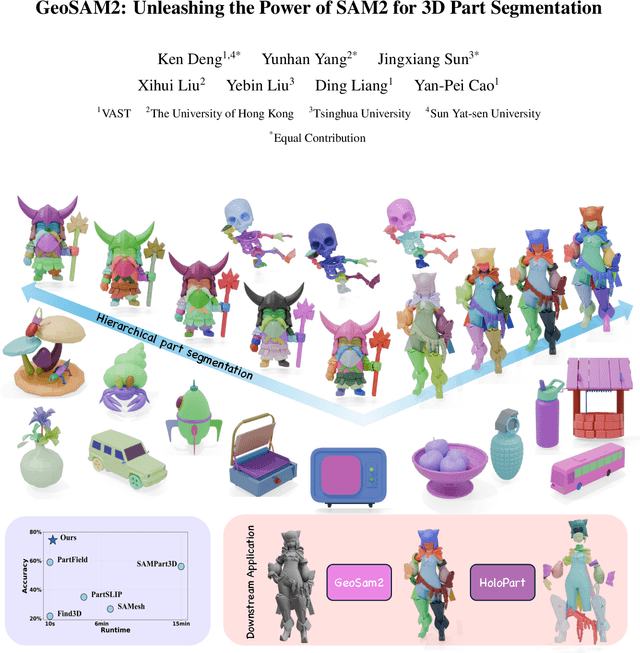

Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
SemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
Jun 11, 2025Holistic 3D scene understanding, which jointly models geometry, appearance, and semantics, is crucial for applications like augmented reality and robotic interaction. Existing feed-forward 3D scene understanding methods (e.g., LSM) are limited to extracting language-based semantics from scenes, failing to achieve holistic scene comprehension. Additionally, they suffer from low-quality geometry reconstruction and noisy artifacts. In contrast, per-scene optimization methods rely on dense input views, which reduces practicality and increases complexity during deployment. In this paper, we propose SemanticSplat, a feed-forward semantic-aware 3D reconstruction method, which unifies 3D Gaussians with latent semantic attributes for joint geometry-appearance-semantics modeling. To predict the semantic anisotropic Gaussians, SemanticSplat fuses diverse feature fields (e.g., LSeg, SAM) with a cost volume representation that stores cross-view feature similarities, enhancing coherent and accurate scene comprehension. Leveraging a two-stage distillation framework, SemanticSplat reconstructs a holistic multi-modal semantic feature field from sparse-view images. Experiments demonstrate the effectiveness of our method for 3D scene understanding tasks like promptable and open-vocabulary segmentation. Video results are available at https://semanticsplat.github.io.
Parametric Gaussian Human Model: Generalizable Prior for Efficient and Realistic Human Avatar Modeling
Jun 07, 2025Photorealistic and animatable human avatars are a key enabler for virtual/augmented reality, telepresence, and digital entertainment. While recent advances in 3D Gaussian Splatting (3DGS) have greatly improved rendering quality and efficiency, existing methods still face fundamental challenges, including time-consuming per-subject optimization and poor generalization under sparse monocular inputs. In this work, we present the Parametric Gaussian Human Model (PGHM), a generalizable and efficient framework that integrates human priors into 3DGS for fast and high-fidelity avatar reconstruction from monocular videos. PGHM introduces two core components: (1) a UV-aligned latent identity map that compactly encodes subject-specific geometry and appearance into a learnable feature tensor; and (2) a disentangled Multi-Head U-Net that predicts Gaussian attributes by decomposing static, pose-dependent, and view-dependent components via conditioned decoders. This design enables robust rendering quality under challenging poses and viewpoints, while allowing efficient subject adaptation without requiring multi-view capture or long optimization time. Experiments show that PGHM is significantly more efficient than optimization-from-scratch methods, requiring only approximately 20 minutes per subject to produce avatars with comparable visual quality, thereby demonstrating its practical applicability for real-world monocular avatar creation.
DetailGen3D: Generative 3D Geometry Enhancement via Data-Dependent Flow
Nov 25, 2024Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
DreamCraft3D++: Efficient Hierarchical 3D Generation with Multi-Plane Reconstruction Model
Oct 16, 2024
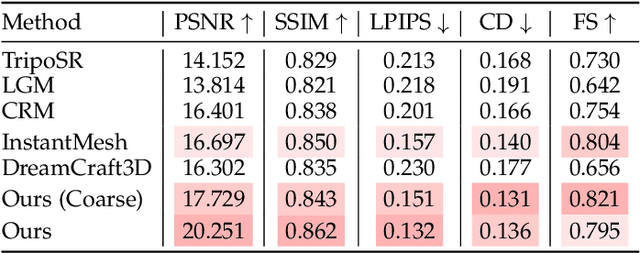


We introduce DreamCraft3D++, an extension of DreamCraft3D that enables efficient high-quality generation of complex 3D assets. DreamCraft3D++ inherits the multi-stage generation process of DreamCraft3D, but replaces the time-consuming geometry sculpting optimization with a feed-forward multi-plane based reconstruction model, speeding up the process by 1000x. For texture refinement, we propose a training-free IP-Adapter module that is conditioned on the enhanced multi-view images to enhance texture and geometry consistency, providing a 4x faster alternative to DreamCraft3D's DreamBooth fine-tuning. Experiments on diverse datasets demonstrate DreamCraft3D++'s ability to generate creative 3D assets with intricate geometry and realistic 360{\deg} textures, outperforming state-of-the-art image-to-3D methods in quality and speed. The full implementation will be open-sourced to enable new possibilities in 3D content creation.
Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer
May 27, 2024
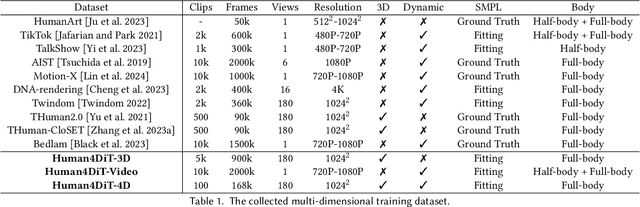
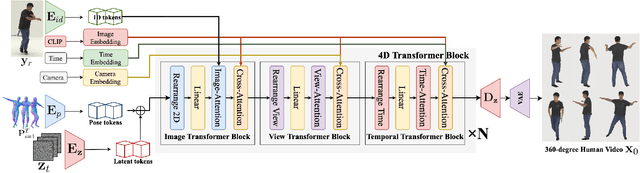
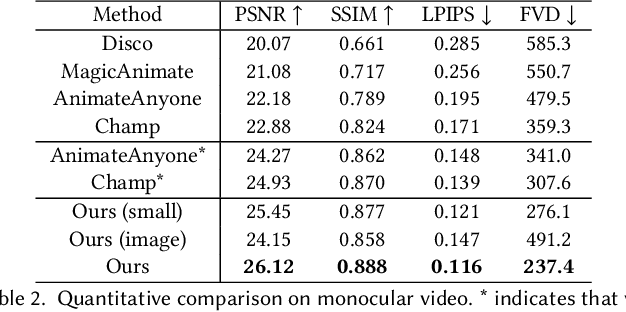
We present a novel approach for generating high-quality, spatio-temporally coherent human videos from a single image under arbitrary viewpoints. Our framework combines the strengths of U-Nets for accurate condition injection and diffusion transformers for capturing global correlations across viewpoints and time. The core is a cascaded 4D transformer architecture that factorizes attention across views, time, and spatial dimensions, enabling efficient modeling of the 4D space. Precise conditioning is achieved by injecting human identity, camera parameters, and temporal signals into the respective transformers. To train this model, we curate a multi-dimensional dataset spanning images, videos, multi-view data and 3D/4D scans, along with a multi-dimensional training strategy. Our approach overcomes the limitations of previous methods based on GAN or UNet-based diffusion models, which struggle with complex motions and viewpoint changes. Through extensive experiments, we demonstrate our method's ability to synthesize realistic, coherent and free-view human videos, paving the way for advanced multimedia applications in areas such as virtual reality and animation. Our project website is https://human4dit.github.io.
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Mar 11, 2024
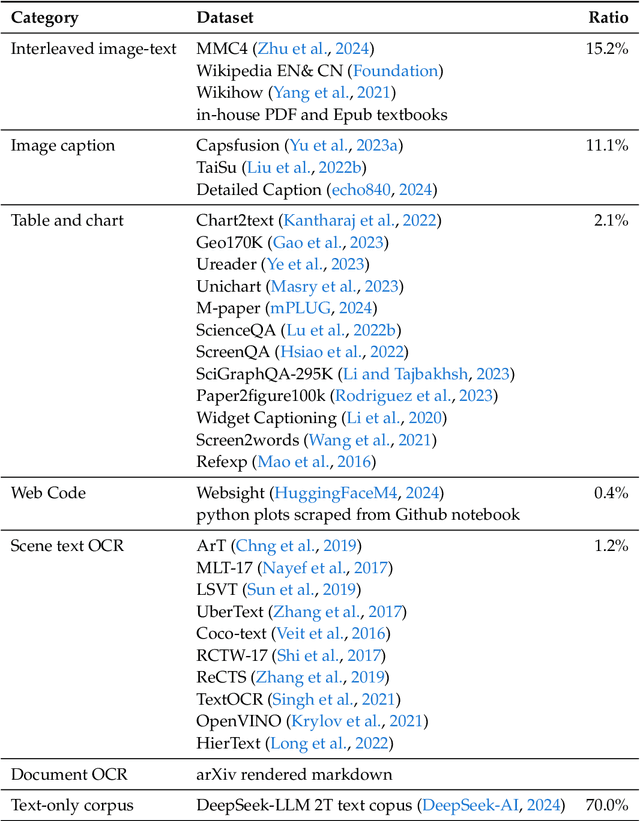
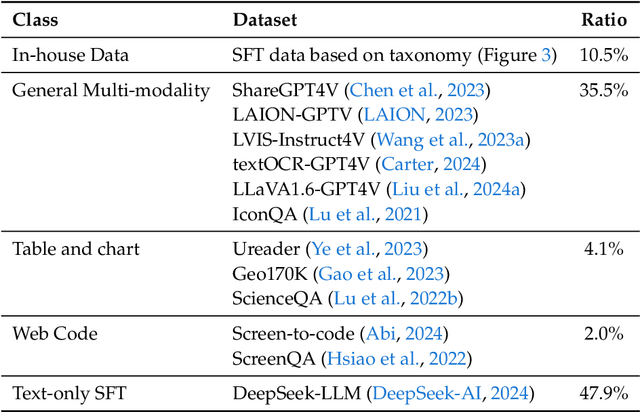
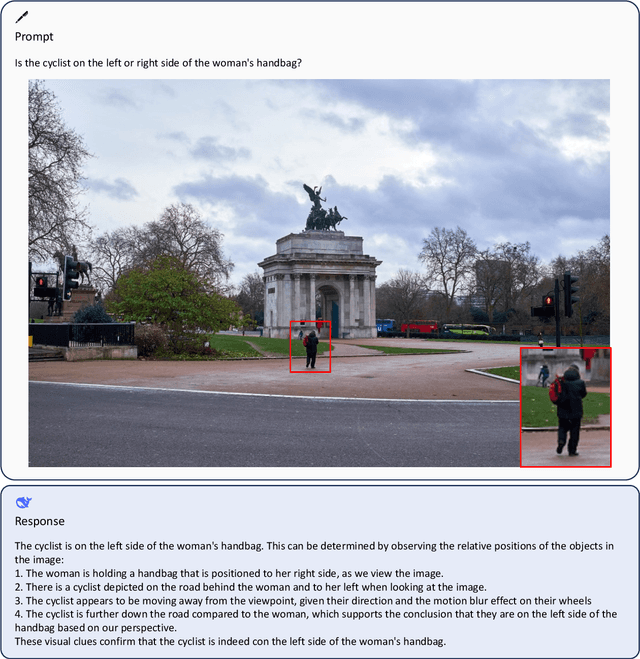
We present DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. Our approach is structured around three key dimensions: We strive to ensure our data is diverse, scalable, and extensively covers real-world scenarios including web screenshots, PDFs, OCR, charts, and knowledge-based content, aiming for a comprehensive representation of practical contexts. Further, we create a use case taxonomy from real user scenarios and construct an instruction tuning dataset accordingly. The fine-tuning with this dataset substantially improves the model's user experience in practical applications. Considering efficiency and the demands of most real-world scenarios, DeepSeek-VL incorporates a hybrid vision encoder that efficiently processes high-resolution images (1024 x 1024), while maintaining a relatively low computational overhead. This design choice ensures the model's ability to capture critical semantic and detailed information across various visual tasks. We posit that a proficient Vision-Language Model should, foremost, possess strong language abilities. To ensure the preservation of LLM capabilities during pretraining, we investigate an effective VL pretraining strategy by integrating LLM training from the beginning and carefully managing the competitive dynamics observed between vision and language modalities. The DeepSeek-VL family (both 1.3B and 7B models) showcases superior user experiences as a vision-language chatbot in real-world applications, achieving state-of-the-art or competitive performance across a wide range of visual-language benchmarks at the same model size while maintaining robust performance on language-centric benchmarks. We have made both 1.3B and 7B models publicly accessible to foster innovations based on this foundation model.