 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualTalk: Dual-Speaker Interaction for 3D Talking Head Conversations
May 26, 2025In face-to-face conversations, individuals need to switch between speaking and listening roles seamlessly. Existing 3D talking head generation models focus solely on speaking or listening, neglecting the natural dynamics of interactive conversation, which leads to unnatural interactions and awkward transitions. To address this issue, we propose a new task -- multi-round dual-speaker interaction for 3D talking head generation -- which requires models to handle and generate both speaking and listening behaviors in continuous conversation. To solve this task, we introduce DualTalk, a novel unified framework that integrates the dynamic behaviors of speakers and listeners to simulate realistic and coherent dialogue interactions. This framework not only synthesizes lifelike talking heads when speaking but also generates continuous and vivid non-verbal feedback when listening, effectively capturing the interplay between the roles. We also create a new dataset featuring 50 hours of multi-round conversations with over 1,000 characters, where participants continuously switch between speaking and listening roles. Extensive experiments demonstrate that our method significantly enhances the naturalness and expressiveness of 3D talking heads in dual-speaker conversations. We recommend watching the supplementary video: https://ziqiaopeng.github.io/dualtalk.
Seeking Flat Minima over Diverse Surrogates for Improved Adversarial Transferability: A Theoretical Framework and Algorithmic Instantiation
Apr 23, 2025



The transfer-based black-box adversarial attack setting poses the challenge of crafting an adversarial example (AE) on known surrogate models that remain effective against unseen target models. Due to the practical importance of this task, numerous methods have been proposed to address this challenge. However, most previous methods are heuristically designed and intuitively justified, lacking a theoretical foundation. To bridge this gap, we derive a novel transferability bound that offers provable guarantees for adversarial transferability. Our theoretical analysis has the advantages of \textit{(i)} deepening our understanding of previous methods by building a general attack framework and \textit{(ii)} providing guidance for designing an effective attack algorithm. Our theoretical results demonstrate that optimizing AEs toward flat minima over the surrogate model set, while controlling the surrogate-target model shift measured by the adversarial model discrepancy, yields a comprehensive guarantee for AE transferability. The results further lead to a general transfer-based attack framework, within which we observe that previous methods consider only partial factors contributing to the transferability. Algorithmically, inspired by our theoretical results, we first elaborately construct the surrogate model set in which models exhibit diverse adversarial vulnerabilities with respect to AEs to narrow an instantiated adversarial model discrepancy. Then, a \textit{model-Diversity-compatible Reverse Adversarial Perturbation} (DRAP) is generated to effectively promote the flatness of AEs over diverse surrogate models to improve transferability. Extensive experiments on NIPS2017 and CIFAR-10 datasets against various target models demonstrate the effectiveness of our proposed attack.
3D Gaussian Head Avatars with Expressive Dynamic Appearances by Compact Tensorial Representations
Apr 21, 2025Recent studies have combined 3D Gaussian and 3D Morphable Models (3DMM) to construct high-quality 3D head avatars. In this line of research, existing methods either fail to capture the dynamic textures or incur significant overhead in terms of runtime speed or storage space. To this end, we propose a novel method that addresses all the aforementioned demands. In specific, we introduce an expressive and compact representation that encodes texture-related attributes of the 3D Gaussians in the tensorial format. We store appearance of neutral expression in static tri-planes, and represents dynamic texture details for different expressions using lightweight 1D feature lines, which are then decoded into opacity offset relative to the neutral face. We further propose adaptive truncated opacity penalty and class-balanced sampling to improve generalization across different expressions. Experiments show this design enables accurate face dynamic details capturing while maintains real-time rendering and significantly reduces storage costs, thus broadening the applicability to more scenarios.
AvatarArtist: Open-Domain 4D Avatarization
Mar 26, 2025This work focuses on open-domain 4D avatarization, with the purpose of creating a 4D avatar from a portrait image in an arbitrary style. We select parametric triplanes as the intermediate 4D representation and propose a practical training paradigm that takes advantage of both generative adversarial networks (GANs) and diffusion models. Our design stems from the observation that 4D GANs excel at bridging images and triplanes without supervision yet usually face challenges in handling diverse data distributions. A robust 2D diffusion prior emerges as the solution, assisting the GAN in transferring its expertise across various domains. The synergy between these experts permits the construction of a multi-domain image-triplane dataset, which drives the development of a general 4D avatar creator. Extensive experiments suggest that our model, AvatarArtist, is capable of producing high-quality 4D avatars with strong robustness to various source image domains. The code, the data, and the models will be made publicly available to facilitate future studies.
Bridging 3D Gaussian and Mesh for Freeview Video Rendering
Mar 18, 2024This is only a preview version of GauMesh. Recently, primitive-based rendering has been proven to achieve convincing results in solving the problem of modeling and rendering the 3D dynamic scene from 2D images. Despite this, in the context of novel view synthesis, each type of primitive has its inherent defects in terms of representation ability. It is difficult to exploit the mesh to depict the fuzzy geometry. Meanwhile, the point-based splatting (e.g. the 3D Gaussian Splatting) method usually produces artifacts or blurry pixels in the area with smooth geometry and sharp textures. As a result, it is difficult, even not impossible, to represent the complex and dynamic scene with a single type of primitive. To this end, we propose a novel approach, GauMesh, to bridge the 3D Gaussian and Mesh for modeling and rendering the dynamic scenes. Given a sequence of tracked mesh as initialization, our goal is to simultaneously optimize the mesh geometry, color texture, opacity maps, a set of 3D Gaussians, and the deformation field. At a specific time, we perform $\alpha$-blending on the RGB and opacity values based on the merged and re-ordered z-buffers from mesh and 3D Gaussian rasterizations. This produces the final rendering, which is supervised by the ground-truth image. Experiments demonstrate that our approach adapts the appropriate type of primitives to represent the different parts of the dynamic scene and outperforms all the baseline methods in both quantitative and qualitative comparisons without losing render speed.
VectorTalker: SVG Talking Face Generation with Progressive Vectorisation
Dec 18, 2023High-fidelity and efficient audio-driven talking head generation has been a key research topic in computer graphics and computer vision. In this work, we study vector image based audio-driven talking head generation. Compared with directly animating the raster image that most widely used in existing works, vector image enjoys its excellent scalability being used for many applications. There are two main challenges for vector image based talking head generation: the high-quality vector image reconstruction w.r.t. the source portrait image and the vivid animation w.r.t. the audio signal. To address these, we propose a novel scalable vector graphic reconstruction and animation method, dubbed VectorTalker. Specifically, for the highfidelity reconstruction, VectorTalker hierarchically reconstructs the vector image in a coarse-to-fine manner. For the vivid audio-driven facial animation, we propose to use facial landmarks as intermediate motion representation and propose an efficient landmark-driven vector image deformation module. Our approach can handle various styles of portrait images within a unified framework, including Japanese manga, cartoon, and photorealistic images. We conduct extensive quantitative and qualitative evaluations and the experimental results demonstrate the superiority of VectorTalker in both vector graphic reconstruction and audio-driven animation.
Act As You Wish: Fine-Grained Control of Motion Diffusion Model with Hierarchical Semantic Graphs
Nov 02, 2023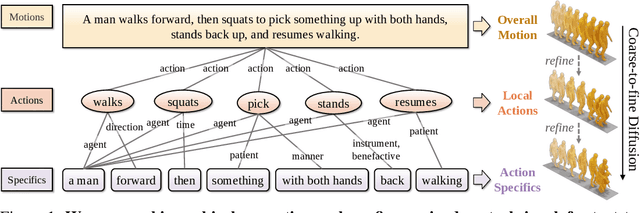

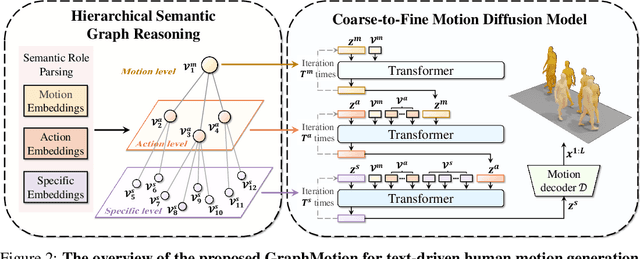
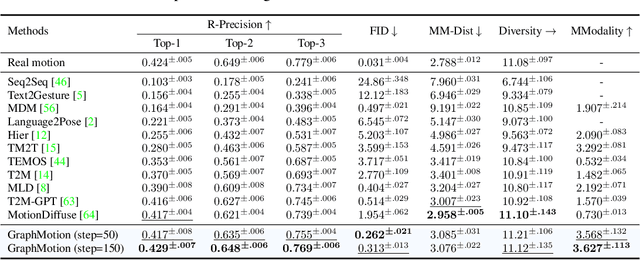
Most text-driven human motion generation methods employ sequential modeling approaches, e.g., transformer, to extract sentence-level text representations automatically and implicitly for human motion synthesis. However, these compact text representations may overemphasize the action names at the expense of other important properties and lack fine-grained details to guide the synthesis of subtly distinct motion. In this paper, we propose hierarchical semantic graphs for fine-grained control over motion generation. Specifically, we disentangle motion descriptions into hierarchical semantic graphs including three levels of motions, actions, and specifics. Such global-to-local structures facilitate a comprehensive understanding of motion description and fine-grained control of motion generation. Correspondingly, to leverage the coarse-to-fine topology of hierarchical semantic graphs, we decompose the text-to-motion diffusion process into three semantic levels, which correspond to capturing the overall motion, local actions, and action specifics. Extensive experiments on two benchmark human motion datasets, including HumanML3D and KIT, with superior performances, justify the efficacy of our method. More encouragingly, by modifying the edge weights of hierarchical semantic graphs, our method can continuously refine the generated motion, which may have a far-reaching impact on the community. Code and pre-training weights are available at https://github.com/jpthu17/GraphMotion.
ToonTalker: Cross-Domain Face Reenactment
Aug 24, 2023We target cross-domain face reenactment in this paper, i.e., driving a cartoon image with the video of a real person and vice versa. Recently, many works have focused on one-shot talking face generation to drive a portrait with a real video, i.e., within-domain reenactment. Straightforwardly applying those methods to cross-domain animation will cause inaccurate expression transfer, blur effects, and even apparent artifacts due to the domain shift between cartoon and real faces. Only a few works attempt to settle cross-domain face reenactment. The most related work AnimeCeleb requires constructing a dataset with pose vector and cartoon image pairs by animating 3D characters, which makes it inapplicable anymore if no paired data is available. In this paper, we propose a novel method for cross-domain reenactment without paired data. Specifically, we propose a transformer-based framework to align the motions from different domains into a common latent space where motion transfer is conducted via latent code addition. Two domain-specific motion encoders and two learnable motion base memories are used to capture domain properties. A source query transformer and a driving one are exploited to project domain-specific motion to the canonical space. The edited motion is projected back to the domain of the source with a transformer. Moreover, since no paired data is provided, we propose a novel cross-domain training scheme using data from two domains with the designed analogy constraint. Besides, we contribute a cartoon dataset in Disney style. Extensive evaluations demonstrate the superiority of our method over competing methods.
Boosting Backdoor Attack with A Learnable Poisoning Sample Selection Strategy
Jul 14, 2023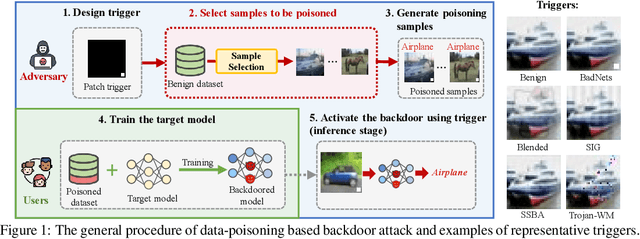
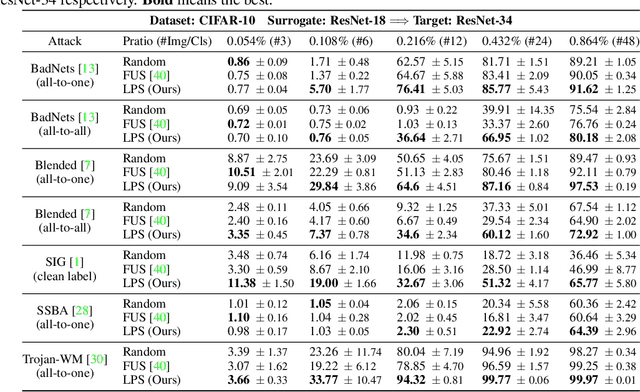
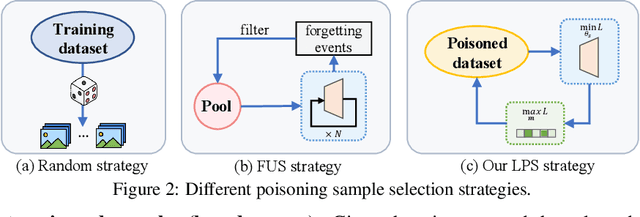
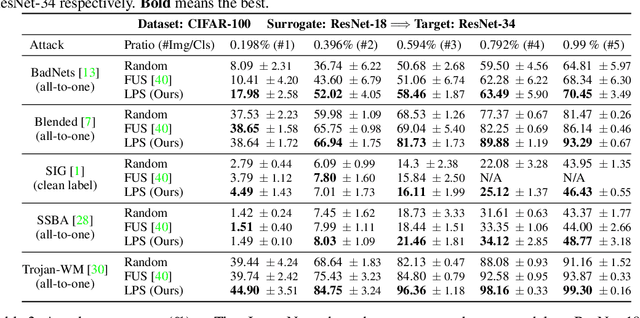
Data-poisoning based backdoor attacks aim to insert backdoor into models by manipulating training datasets without controlling the training process of the target model. Existing attack methods mainly focus on designing triggers or fusion strategies between triggers and benign samples. However, they often randomly select samples to be poisoned, disregarding the varying importance of each poisoning sample in terms of backdoor injection. A recent selection strategy filters a fixed-size poisoning sample pool by recording forgetting events, but it fails to consider the remaining samples outside the pool from a global perspective. Moreover, computing forgetting events requires significant additional computing resources. Therefore, how to efficiently and effectively select poisoning samples from the entire dataset is an urgent problem in backdoor attacks.To address it, firstly, we introduce a poisoning mask into the regular backdoor training loss. We suppose that a backdoored model training with hard poisoning samples has a more backdoor effect on easy ones, which can be implemented by hindering the normal training process (\ie, maximizing loss \wrt mask). To further integrate it with normal training process, we then propose a learnable poisoning sample selection strategy to learn the mask together with the model parameters through a min-max optimization.Specifically, the outer loop aims to achieve the backdoor attack goal by minimizing the loss based on the selected samples, while the inner loop selects hard poisoning samples that impede this goal by maximizing the loss. After several rounds of adversarial training, we finally select effective poisoning samples with high contribution. Extensive experiments on benchmark datasets demonstrate the effectiveness and efficiency of our approach in boosting backdoor attack performance.
NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Jul 07, 20233D facial avatar reconstruction has been a significant research topic in computer graphics and computer vision, where photo-realistic rendering and flexible controls over poses and expressions are necessary for many related applications. Recently, its performance has been greatly improved with the development of neural radiance fields (NeRF). However, most existing NeRF-based facial avatars focus on subject-specific reconstruction and reenactment, requiring multi-shot images containing different views of the specific subject for training, and the learned model cannot generalize to new identities, limiting its further applications. In this work, we propose a one-shot 3D facial avatar reconstruction framework that only requires a single source image to reconstruct a high-fidelity 3D facial avatar. For the challenges of lacking generalization ability and missing multi-view information, we leverage the generative prior of 3D GAN and develop an efficient encoder-decoder network to reconstruct the canonical neural volume of the source image, and further propose a compensation network to complement facial details. To enable fine-grained control over facial dynamics, we propose a deformation field to warp the canonical volume into driven expressions. Through extensive experimental comparisons, we achieve superior synthesis results compared to several state-of-the-art methods.