 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging 3D Gaussian and Mesh for Freeview Video Rendering
Mar 18, 2024This is only a preview version of GauMesh. Recently, primitive-based rendering has been proven to achieve convincing results in solving the problem of modeling and rendering the 3D dynamic scene from 2D images. Despite this, in the context of novel view synthesis, each type of primitive has its inherent defects in terms of representation ability. It is difficult to exploit the mesh to depict the fuzzy geometry. Meanwhile, the point-based splatting (e.g. the 3D Gaussian Splatting) method usually produces artifacts or blurry pixels in the area with smooth geometry and sharp textures. As a result, it is difficult, even not impossible, to represent the complex and dynamic scene with a single type of primitive. To this end, we propose a novel approach, GauMesh, to bridge the 3D Gaussian and Mesh for modeling and rendering the dynamic scenes. Given a sequence of tracked mesh as initialization, our goal is to simultaneously optimize the mesh geometry, color texture, opacity maps, a set of 3D Gaussians, and the deformation field. At a specific time, we perform $\alpha$-blending on the RGB and opacity values based on the merged and re-ordered z-buffers from mesh and 3D Gaussian rasterizations. This produces the final rendering, which is supervised by the ground-truth image. Experiments demonstrate that our approach adapts the appropriate type of primitives to represent the different parts of the dynamic scene and outperforms all the baseline methods in both quantitative and qualitative comparisons without losing render speed.
Neural Surface Reconstruction of Dynamic Scenes with Monocular RGB-D Camera
Jun 30, 2022
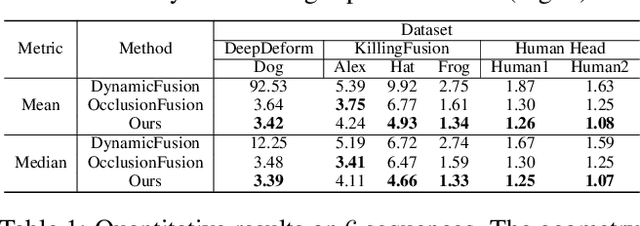
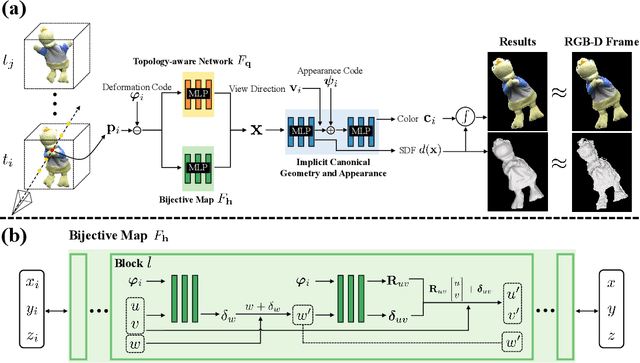

We propose Neural-DynamicReconstruction (NDR), a template-free method to recover high-fidelity geometry and motions of a dynamic scene from a monocular RGB-D camera. In NDR, we adopt the neural implicit function for surface representation and rendering such that the captured color and depth can be fully utilized to jointly optimize the surface and deformations. To represent and constrain the non-rigid deformations, we propose a novel neural invertible deforming network such that the cycle consistency between arbitrary two frames is automatically satisfied. Considering that the surface topology of dynamic scene might change over time, we employ a topology-aware strategy to construct the topology-variant correspondence for the fused frames. NDR also further refines the camera poses in a global optimization manner. Experiments on public datasets and our collected dataset demonstrate that NDR outperforms existing monocular dynamic reconstruction methods.
Neural Points: Point Cloud Representation with Neural Fields
Dec 13, 2021
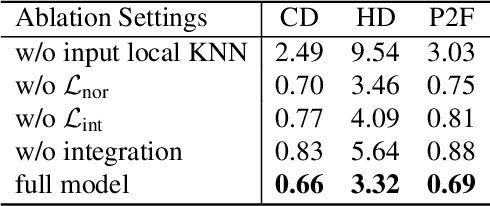
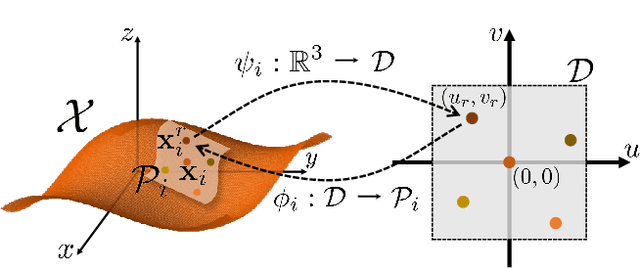
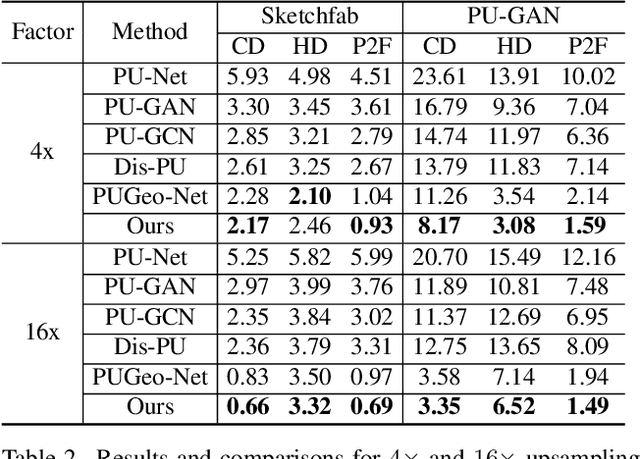
In this paper, we propose \emph{Neural Points}, a novel point cloud representation. Unlike traditional point cloud representation where each point only represents a position or a local plane in the 3D space, each point in Neural Points represents a local continuous geometric shape via neural fields. Therefore, Neural Points can express much more complex details and thus have a stronger representation ability. Neural Points is trained with high-resolution surface containing rich geometric details, such that the trained model has enough expression ability for various shapes. Specifically, we extract deep local features on the points and construct neural fields through the local isomorphism between the 2D parametric domain and the 3D local patch. In the final, local neural fields are integrated together to form the global surface. Experimental results show that Neural Points has powerful representation ability and demonstrate excellent robustness and generalization ability. With Neural Points, we can resample point cloud with arbitrary resolutions, and it outperforms state-of-the-art point cloud upsampling methods by a large margin.
Recurrent Multi-view Alignment Network for Unsupervised Surface Registration
Nov 24, 2020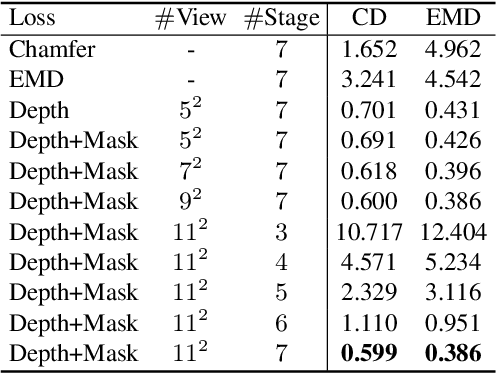


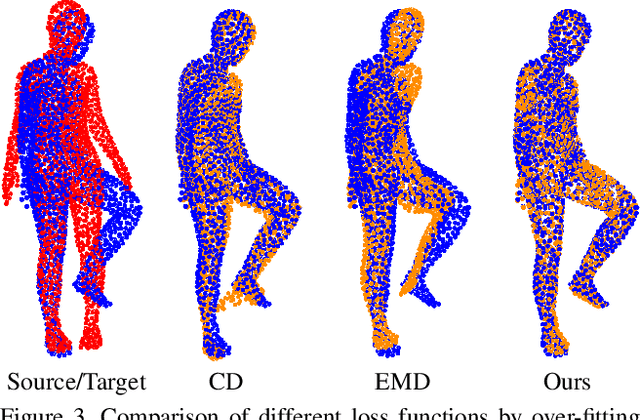
Learning non-rigid registration in an end-to-end manner is challenging due to the inherent high degrees of freedom and the lack of labeled training data. In this paper, we resolve these two challenges simultaneously. First, we propose to represent the non-rigid transformation with a point-wise combination of several rigid transformations. This representation not only makes the solution space well-constrained but also enables our method to be solved iteratively with a recurrent framework, which greatly reduces the difficulty of learning. Second, we introduce a differentiable loss function that measures the 3D shape similarity on the projected multi-view 2D depth images so that our full framework can be trained end-to-end without ground truth supervision. Extensive experiments on several different datasets demonstrate that our proposed method outperforms the previous state-of-the-art by a large margin.
Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model
Apr 20, 2020


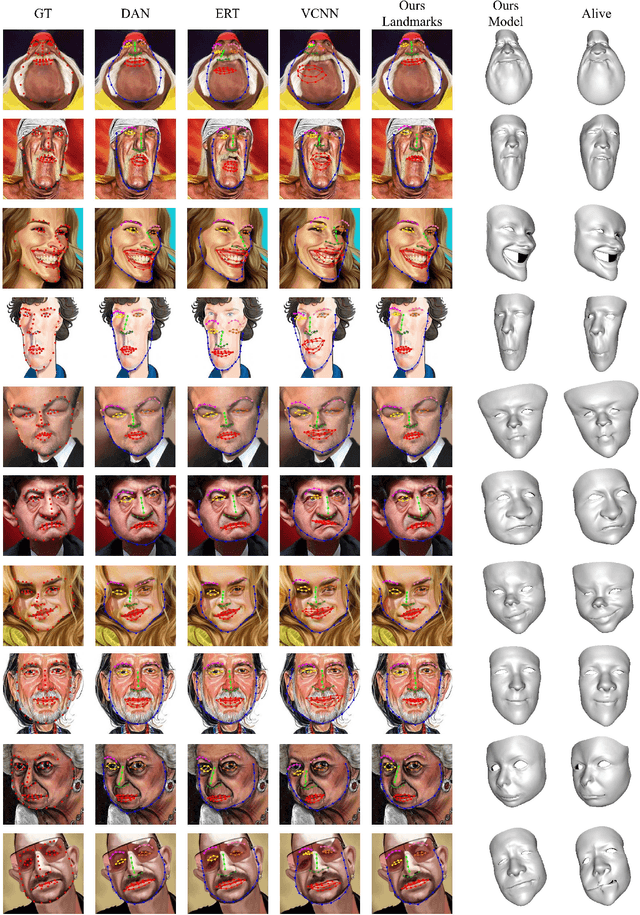
Caricature is an artistic abstraction of the human face by distorting or exaggerating certain facial features, while still retains a likeness with the given face. Due to the large diversity of geometric and texture variations, automatic landmark detection and 3D face reconstruction for caricature is a challenging problem and has rarely been studied before. In this paper, we propose the first automatic method for this task by a novel 3D approach. To this end, we first build a dataset with various styles of 2D caricatures and their corresponding 3D shapes, and then build a parametric model on vertex based deformation space for 3D caricature face. Based on the constructed dataset and the nonlinear parametric model, we propose a neural network based method to regress the 3D face shape and orientation from the input 2D caricature image. Ablation studies and comparison with baseline methods demonstrate the effectiveness of our algorithm design, and extensive experimental results demonstrate that our method works well for various caricatures. Our constructed dataset, source code and trained model are available at https://github.com/Juyong/CaricatureFace.