 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Underwater Light Field Images via Global Geometry-aware Diffusion Process
Jan 29, 2026This work studies the challenging problem of acquiring high-quality underwater images via 4-D light field (LF) imaging. To this end, we propose GeoDiff-LF, a novel diffusion-based framework built upon SD-Turbo to enhance underwater 4-D LF imaging by leveraging its spatial-angular structure. GeoDiff-LF consists of three key adaptations: (1) a modified U-Net architecture with convolutional and attention adapters to model geometric cues, (2) a geometry-guided loss function using tensor decomposition and progressive weighting to regularize global structure, and (3) an optimized sampling strategy with noise prediction to improve efficiency. By integrating diffusion priors and LF geometry, GeoDiff-LF effectively mitigates color distortion in underwater scenes. Extensive experiments demonstrate that our framework outperforms existing methods across both visual fidelity and quantitative performance, advancing the state-of-the-art in enhancing underwater imaging. The code will be publicly available at https://github.com/linlos1234/GeoDiff-LF.
MS-ISSM: Objective Quality Assessment of Point Clouds Using Multi-scale Implicit Structural Similarity
Jan 03, 2026The unstructured and irregular nature of point clouds poses a significant challenge for objective quality assessment (PCQA), particularly in establishing accurate perceptual feature correspondence. To tackle this, we propose the Multi-scale Implicit Structural Similarity Measurement (MS-ISSM). Unlike traditional point-to-point matching, MS-ISSM utilizes Radial Basis Functions (RBF) to represent local features continuously, transforming distortion measurement into a comparison of implicit function coefficients. This approach effectively circumvents matching errors inherent in irregular data. Additionally, we propose a ResGrouped-MLP quality assessment network, which robustly maps multi-scale feature differences to perceptual scores. The network architecture departs from traditional flat MLPs by adopting a grouped encoding strategy integrated with Residual Blocks and Channel-wise Attention mechanisms. This hierarchical design allows the model to preserve the distinct physical semantics of luma, chroma, and geometry while adaptively focusing on the most salient distortion features across High, Medium, and Low scales. Experimental results on multiple benchmarks demonstrate that MS-ISSM outperforms state-of-the-art metrics in both reliability and generalization. The source code is available at: https://github.com/ZhangChen2022/MS-ISSM.
Joint Geometry-Appearance Human Reconstruction in a Unified Latent Space via Bridge Diffusion
Jan 01, 2026Achieving consistent and high-fidelity geometry and appearance reconstruction of 3D digital humans from a single RGB image is inherently a challenging task. Existing studies typically resort to decoupled pipelines for geometry estimation and appearance synthesis, often hindering unified reconstruction and causing inconsistencies. This paper introduces \textbf{JGA-LBD}, a novel framework that unifies the modeling of geometry and appearance into a joint latent representation and formulates the generation process as bridge diffusion. Observing that directly integrating heterogeneous input conditions (e.g., depth maps, SMPL models) leads to substantial training difficulties, we unify all conditions into the 3D Gaussian representations, which can be further compressed into a unified latent space through a shared sparse variational autoencoder (VAE). Subsequently, the specialized form of bridge diffusion enables to start with a partial observation of the target latent code and solely focuses on inferring the missing components. Finally, a dedicated decoding module extracts the complete 3D human geometric structure and renders novel views from the inferred latent representation. Experiments demonstrate that JGA-LBD outperforms current state-of-the-art approaches in terms of both geometry fidelity and appearance quality, including challenging in-the-wild scenarios. Our code will be made publicly available at https://github.com/haiantyz/JGA-LBD.
Towards Better IncomLDL: We Are Unaware of Hidden Labels in Advance
Nov 16, 2025Label distribution learning (LDL) is a novel paradigm that describe the samples by label distribution of a sample. However, acquiring LDL dataset is costly and time-consuming, which leads to the birth of incomplete label distribution learning (IncomLDL). All the previous IncomLDL methods set the description degrees of "missing" labels in an instance to 0, but remains those of other labels unchanged. This setting is unrealistic because when certain labels are missing, the degrees of the remaining labels will increase accordingly. We fix this unrealistic setting in IncomLDL and raise a new problem: LDL with hidden labels (HidLDL), which aims to recover a complete label distribution from a real-world incomplete label distribution where certain labels in an instance are omitted during annotation. To solve this challenging problem, we discover the significance of proportional information of the observed labels and capture it by an innovative constraint to utilize it during the optimization process. We simultaneously use local feature similarity and the global low-rank structure to reveal the mysterious veil of hidden labels. Moreover, we theoretically give the recovery bound of our method, proving the feasibility of our method in learning from hidden labels. Extensive recovery and predictive experiments on various datasets prove the superiority of our method to state-of-the-art LDL and IncomLDL methods.
Voronoi-Assisted Diffusion for Computing Unsigned Distance Fields from Unoriented Points
Oct 14, 2025Unsigned Distance Fields (UDFs) provide a flexible representation for 3D shapes with arbitrary topology, including open and closed surfaces, orientable and non-orientable geometries, and non-manifold structures. While recent neural approaches have shown promise in learning UDFs, they often suffer from numerical instability, high computational cost, and limited controllability. We present a lightweight, network-free method, Voronoi-Assisted Diffusion (VAD), for computing UDFs directly from unoriented point clouds. Our approach begins by assigning bi-directional normals to input points, guided by two Voronoi-based geometric criteria encoded in an energy function for optimal alignment. The aligned normals are then diffused to form an approximate UDF gradient field, which is subsequently integrated to recover the final UDF. Experiments demonstrate that VAD robustly handles watertight and open surfaces, as well as complex non-manifold and non-orientable geometries, while remaining computationally efficient and stable.
Exploring Non-Local Spatial-Angular Correlations with a Hybrid Mamba-Transformer Framework for Light Field Super-Resolution
Sep 05, 2025Recently, Mamba-based methods, with its advantage in long-range information modeling and linear complexity, have shown great potential in optimizing both computational cost and performance of light field image super-resolution (LFSR). However, current multi-directional scanning strategies lead to inefficient and redundant feature extraction when applied to complex LF data. To overcome this challenge, we propose a Subspace Simple Scanning (Sub-SS) strategy, based on which we design the Subspace Simple Mamba Block (SSMB) to achieve more efficient and precise feature extraction. Furthermore, we propose a dual-stage modeling strategy to address the limitation of state space in preserving spatial-angular and disparity information, thereby enabling a more comprehensive exploration of non-local spatial-angular correlations. Specifically, in stage I, we introduce the Spatial-Angular Residual Subspace Mamba Block (SA-RSMB) for shallow spatial-angular feature extraction; in stage II, we use a dual-branch parallel structure combining the Epipolar Plane Mamba Block (EPMB) and Epipolar Plane Transformer Block (EPTB) for deep epipolar feature refinement. Building upon meticulously designed modules and strategies, we introduce a hybrid Mamba-Transformer framework, termed LFMT. LFMT integrates the strengths of Mamba and Transformer models for LFSR, enabling comprehensive information exploration across spatial, angular, and epipolar-plane domains. Experimental results demonstrate that LFMT significantly outperforms current state-of-the-art methods in LFSR, achieving substantial improvements in performance while maintaining low computational complexity on both real-word and synthetic LF datasets.
Optimizing Multi-Modal Trackers via Sensitivity-aware Regularized Tuning
Aug 24, 2025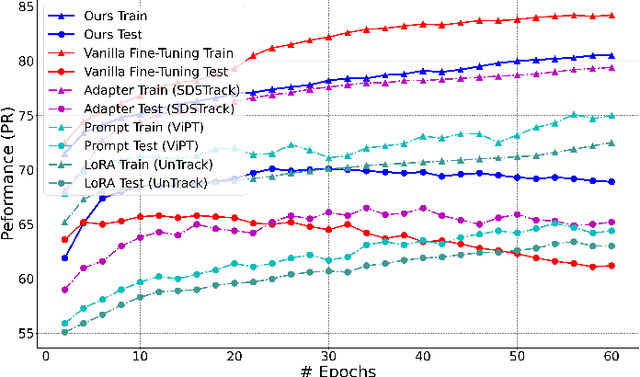

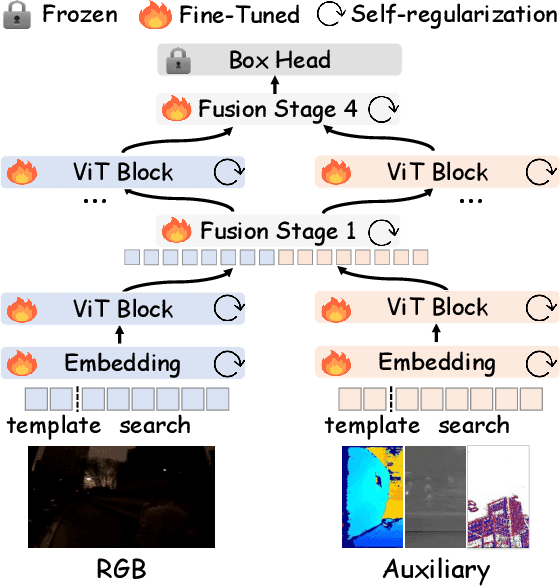
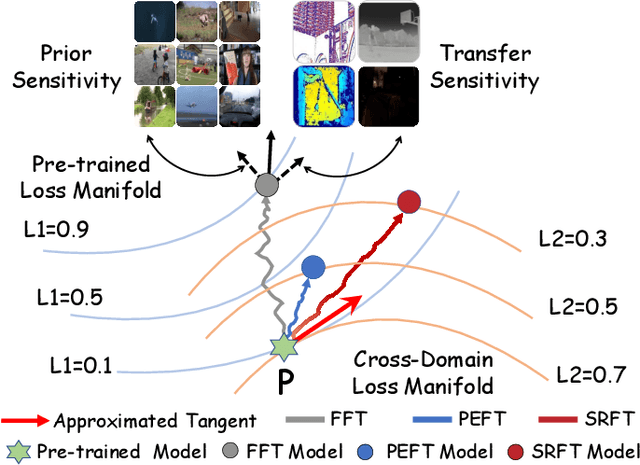
This paper tackles the critical challenge of optimizing multi-modal trackers by effectively adapting the pre-trained models for RGB data. Existing fine-tuning paradigms oscillate between excessive freedom and over-restriction, both leading to a suboptimal plasticity-stability trade-off. To mitigate this dilemma, we propose a novel sensitivity-aware regularized tuning framework, which delicately refines the learning process by incorporating intrinsic parameter sensitivities. Through a comprehensive investigation from pre-trained to multi-modal contexts, we identify that parameters sensitive to pivotal foundational patterns and cross-domain shifts are primary drivers of this issue. Specifically, we first analyze the tangent space of pre-trained weights to measure and orient prior sensitivities, dedicated to preserving generalization. Then, we further explore transfer sensitivities during the tuning phase, emphasizing adaptability and stability. By incorporating these sensitivities as regularization terms, our method significantly enhances the transferability across modalities. Extensive experiments showcase the superior performance of the proposed method, surpassing current state-of-the-art techniques across various multi-modal tracking. The source code and models will be publicly available at https://github.com/zhiwen-xdu/SRTrack.
PVNet: Point-Voxel Interaction LiDAR Scene Upsampling Via Diffusion Models
Aug 23, 2025Accurate 3D scene understanding in outdoor environments heavily relies on high-quality point clouds. However, LiDAR-scanned data often suffer from extreme sparsity, severely hindering downstream 3D perception tasks. Existing point cloud upsampling methods primarily focus on individual objects, thus demonstrating limited generalization capability for complex outdoor scenes. To address this issue, we propose PVNet, a diffusion model-based point-voxel interaction framework to perform LiDAR point cloud upsampling without dense supervision. Specifically, we adopt the classifier-free guidance-based DDPMs to guide the generation, in which we employ a sparse point cloud as the guiding condition and the synthesized point clouds derived from its nearby frames as the input. Moreover, we design a voxel completion module to refine and complete the coarse voxel features for enriching the feature representation. In addition, we propose a point-voxel interaction module to integrate features from both points and voxels, which efficiently improves the environmental perception capability of each upsampled point. To the best of our knowledge, our approach is the first scene-level point cloud upsampling method supporting arbitrary upsampling rates. Extensive experiments on various benchmarks demonstrate that our method achieves state-of-the-art performance. The source code will be available at https://github.com/chengxianjing/PVNet.
ABC: Adaptive BayesNet Structure Learning for Computational Scalable Multi-task Image Compression
Jun 18, 2025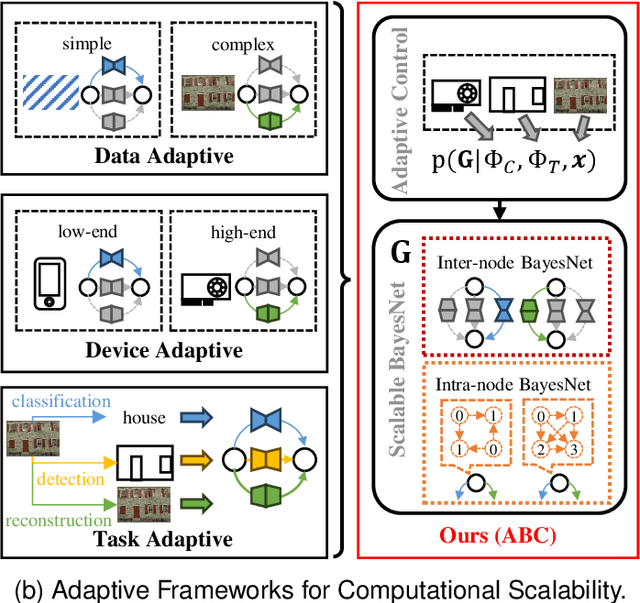

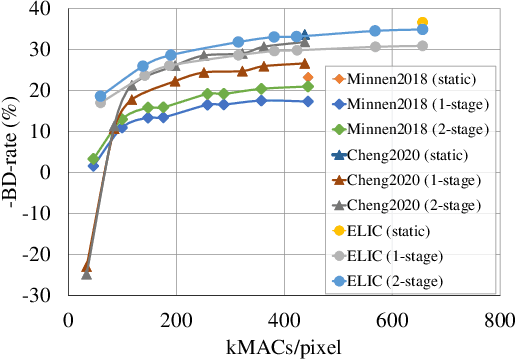
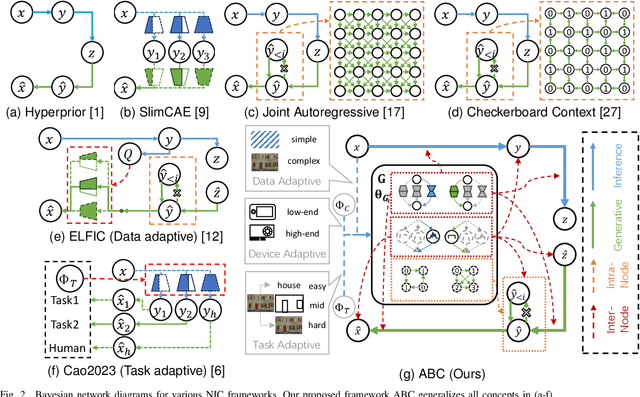
Neural Image Compression (NIC) has revolutionized image compression with its superior rate-distortion performance and multi-task capabilities, supporting both human visual perception and machine vision tasks. However, its widespread adoption is hindered by substantial computational demands. While existing approaches attempt to address this challenge through module-specific optimizations or pre-defined complexity levels, they lack comprehensive control over computational complexity. We present ABC (Adaptive BayesNet structure learning for computational scalable multi-task image Compression), a novel, comprehensive framework that achieves computational scalability across all NIC components through Bayesian network (BayesNet) structure learning. ABC introduces three key innovations: (i) a heterogeneous bipartite BayesNet (inter-node structure) for managing neural backbone computations; (ii) a homogeneous multipartite BayesNet (intra-node structure) for optimizing autoregressive unit processing; and (iii) an adaptive control module that dynamically adjusts the BayesNet structure based on device capabilities, input data complexity, and downstream task requirements. Experiments demonstrate that ABC enables full computational scalability with better complexity adaptivity and broader complexity control span, while maintaining competitive compression performance. Furthermore, the framework's versatility allows integration with various NIC architectures that employ BayesNet representations, making it a robust solution for ensuring computational scalability in NIC applications. Code is available in https://github.com/worldlife123/cbench_BaSIC.
Structural-Spectral Graph Convolution with Evidential Edge Learning for Hyperspectral Image Clustering
Jun 11, 2025



Hyperspectral image (HSI) clustering assigns similar pixels to the same class without any annotations, which is an important yet challenging task. For large-scale HSIs, most methods rely on superpixel segmentation and perform superpixel-level clustering based on graph neural networks (GNNs). However, existing GNNs cannot fully exploit the spectral information of the input HSI, and the inaccurate superpixel topological graph may lead to the confusion of different class semantics during information aggregation. To address these challenges, we first propose a structural-spectral graph convolutional operator (SSGCO) tailored for graph-structured HSI superpixels to improve their representation quality through the co-extraction of spatial and spectral features. Second, we propose an evidence-guided adaptive edge learning (EGAEL) module that adaptively predicts and refines edge weights in the superpixel topological graph. We integrate the proposed method into a contrastive learning framework to achieve clustering, where representation learning and clustering are simultaneously conducted. Experiments demonstrate that the proposed method improves clustering accuracy by 2.61%, 6.06%, 4.96% and 3.15% over the best compared methods on four HSI datasets. Our code is available at https://github.com/jhqi/SSGCO-EGAEL.