 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Holistic Modeling for Video Frame Interpolation with Auto-regressive Diffusion Transformers
Jan 21, 2026Existing video frame interpolation (VFI) methods often adopt a frame-centric approach, processing videos as independent short segments (e.g., triplets), which leads to temporal inconsistencies and motion artifacts. To overcome this, we propose a holistic, video-centric paradigm named \textbf{L}ocal \textbf{D}iffusion \textbf{F}orcing for \textbf{V}ideo \textbf{F}rame \textbf{I}nterpolation (LDF-VFI). Our framework is built upon an auto-regressive diffusion transformer that models the entire video sequence to ensure long-range temporal coherence. To mitigate error accumulation inherent in auto-regressive generation, we introduce a novel skip-concatenate sampling strategy that effectively maintains temporal stability. Furthermore, LDF-VFI incorporates sparse, local attention and tiled VAE encoding, a combination that not only enables efficient processing of long sequences but also allows generalization to arbitrary spatial resolutions (e.g., 4K) at inference without retraining. An enhanced conditional VAE decoder, which leverages multi-scale features from the input video, further improves reconstruction fidelity. Empirically, LDF-VFI achieves state-of-the-art performance on challenging long-sequence benchmarks, demonstrating superior per-frame quality and temporal consistency, especially in scenes with large motion. The source code is available at https://github.com/xypeng9903/LDF-VFI.
Error-Propagation-Free Learned Video Compression With Dual-Domain Progressive Temporal Alignment
Dec 11, 2025Existing frameworks for learned video compression suffer from a dilemma between inaccurate temporal alignment and error propagation for motion estimation and compensation (ME/MC). The separate-transform framework employs distinct transforms for intra-frame and inter-frame compression to yield impressive rate-distortion (R-D) performance but causes evident error propagation, while the unified-transform framework eliminates error propagation via shared transforms but is inferior in ME/MC in shared latent domains. To address this limitation, in this paper, we propose a novel unifiedtransform framework with dual-domain progressive temporal alignment and quality-conditioned mixture-of-expert (QCMoE) to enable quality-consistent and error-propagation-free streaming for learned video compression. Specifically, we propose dualdomain progressive temporal alignment for ME/MC that leverages coarse pixel-domain alignment and refined latent-domain alignment to significantly enhance temporal context modeling in a coarse-to-fine fashion. The coarse pixel-domain alignment efficiently handles simple motion patterns with optical flow estimated from a single reference frame, while the refined latent-domain alignment develops a Flow-Guided Deformable Transformer (FGDT) over latents from multiple reference frames to achieve long-term motion refinement (LTMR) for complex motion patterns. Furthermore, we design a QCMoE module for continuous bit-rate adaptation that dynamically assigns different experts to adjust quantization steps per pixel based on target quality and content rather than relies on a single quantization step. QCMoE allows continuous and consistent rate control with appealing R-D performance. Experimental results show that the proposed method achieves competitive R-D performance compared with the state-of-the-arts, while successfully eliminating error propagation.
OneCAT: Decoder-Only Auto-Regressive Model for Unified Understanding and Generation
Sep 03, 2025


We introduce OneCAT, a unified multimodal model that seamlessly integrates understanding, generation, and editing within a novel, pure decoder-only transformer architecture. Our framework uniquely eliminates the need for external components such as Vision Transformers (ViT) or vision tokenizer during inference, leading to significant efficiency gains, especially for high-resolution inputs. This is achieved through a modality-specific Mixture-of-Experts (MoE) structure trained with a single autoregressive (AR) objective, which also natively supports dynamic resolutions. Furthermore, we pioneer a multi-scale visual autoregressive mechanism within the Large Language Model (LLM) that drastically reduces decoding steps compared to diffusion-based methods while maintaining state-of-the-art performance. Our findings demonstrate the powerful potential of pure autoregressive modeling as a sufficient and elegant foundation for unified multimodal intelligence. As a result, OneCAT sets a new performance standard, outperforming existing open-source unified multimodal models across benchmarks for multimodal generation, editing, and understanding.
3DGabSplat: 3D Gabor Splatting for Frequency-adaptive Radiance Field Rendering
Aug 07, 2025Recent prominence in 3D Gaussian Splatting (3DGS) has enabled real-time rendering while maintaining high-fidelity novel view synthesis. However, 3DGS resorts to the Gaussian function that is low-pass by nature and is restricted in representing high-frequency details in 3D scenes. Moreover, it causes redundant primitives with degraded training and rendering efficiency and excessive memory overhead. To overcome these limitations, we propose 3D Gabor Splatting (3DGabSplat) that leverages a novel 3D Gabor-based primitive with multiple directional 3D frequency responses for radiance field representation supervised by multi-view images. The proposed 3D Gabor-based primitive forms a filter bank incorporating multiple 3D Gabor kernels at different frequencies to enhance flexibility and efficiency in capturing fine 3D details. Furthermore, to achieve novel view rendering, an efficient CUDA-based rasterizer is developed to project the multiple directional 3D frequency components characterized by 3D Gabor-based primitives onto the 2D image plane, and a frequency-adaptive mechanism is presented for adaptive joint optimization of primitives. 3DGabSplat is scalable to be a plug-and-play kernel for seamless integration into existing 3DGS paradigms to enhance both efficiency and quality of novel view synthesis. Extensive experiments demonstrate that 3DGabSplat outperforms 3DGS and its variants using alternative primitives, and achieves state-of-the-art rendering quality across both real-world and synthetic scenes. Remarkably, we achieve up to 1.35 dB PSNR gain over 3DGS with simultaneously reduced number of primitives and memory consumption.
METEOR: Multi-Encoder Collaborative Token Pruning for Efficient Vision Language Models
Jul 28, 2025Vision encoders serve as the cornerstone of multimodal understanding. Single-encoder architectures like CLIP exhibit inherent constraints in generalizing across diverse multimodal tasks, while recent multi-encoder fusion methods introduce prohibitive computational overhead to achieve superior performance using complementary visual representations from multiple vision encoders. To address this, we propose a progressive pruning framework, namely Multi-Encoder collaboraTivE tOken pRuning (METEOR), that eliminates redundant visual tokens across the encoding, fusion, and decoding stages for multi-encoder MLLMs. For multi-vision encoding, we discard redundant tokens within each encoder via a rank guided collaborative token assignment strategy. Subsequently, for multi-vision fusion, we combine the visual features from different encoders while reducing cross-encoder redundancy with cooperative pruning. Finally, we propose an adaptive token pruning method in the LLM decoding stage to further discard irrelevant tokens based on the text prompts with dynamically adjusting pruning ratios for specific task demands. To our best knowledge, this is the first successful attempt that achieves an efficient multi-encoder based vision language model with multi-stage pruning strategies. Extensive experiments on 11 benchmarks demonstrate the effectiveness of our proposed approach. Compared with EAGLE, a typical multi-encoder MLLMs, METEOR reduces 76% visual tokens with only 0.3% performance drop in average. The code is available at https://github.com/YuchenLiu98/METEOR.
ABC: Adaptive BayesNet Structure Learning for Computational Scalable Multi-task Image Compression
Jun 18, 2025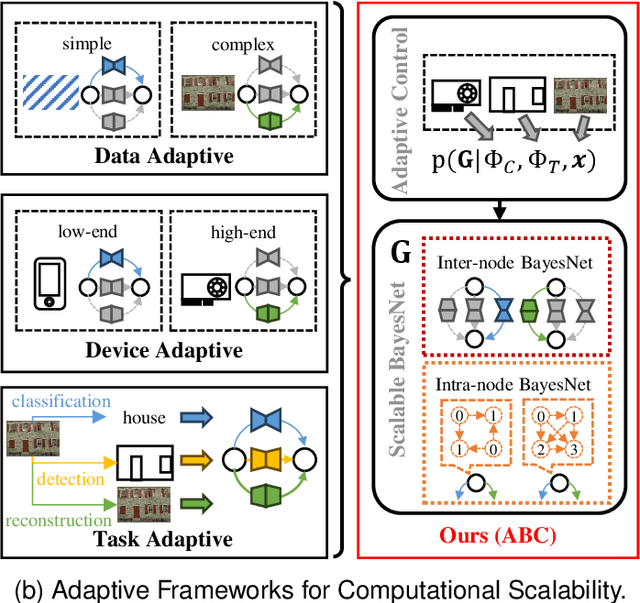

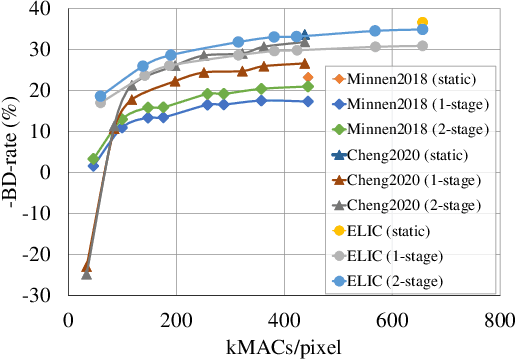
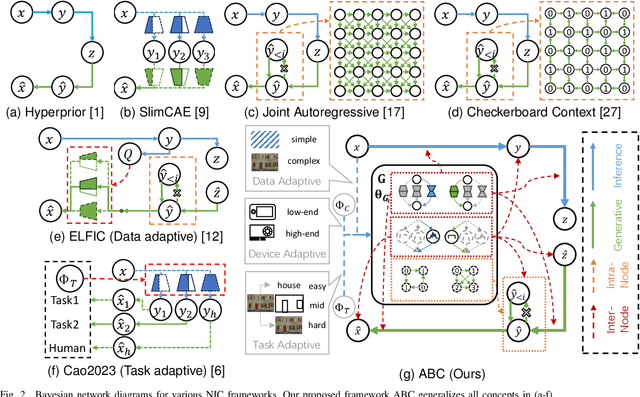
Neural Image Compression (NIC) has revolutionized image compression with its superior rate-distortion performance and multi-task capabilities, supporting both human visual perception and machine vision tasks. However, its widespread adoption is hindered by substantial computational demands. While existing approaches attempt to address this challenge through module-specific optimizations or pre-defined complexity levels, they lack comprehensive control over computational complexity. We present ABC (Adaptive BayesNet structure learning for computational scalable multi-task image Compression), a novel, comprehensive framework that achieves computational scalability across all NIC components through Bayesian network (BayesNet) structure learning. ABC introduces three key innovations: (i) a heterogeneous bipartite BayesNet (inter-node structure) for managing neural backbone computations; (ii) a homogeneous multipartite BayesNet (intra-node structure) for optimizing autoregressive unit processing; and (iii) an adaptive control module that dynamically adjusts the BayesNet structure based on device capabilities, input data complexity, and downstream task requirements. Experiments demonstrate that ABC enables full computational scalability with better complexity adaptivity and broader complexity control span, while maintaining competitive compression performance. Furthermore, the framework's versatility allows integration with various NIC architectures that employ BayesNet representations, making it a robust solution for ensuring computational scalability in NIC applications. Code is available in https://github.com/worldlife123/cbench_BaSIC.
Noise Conditional Variational Score Distillation
Jun 11, 2025
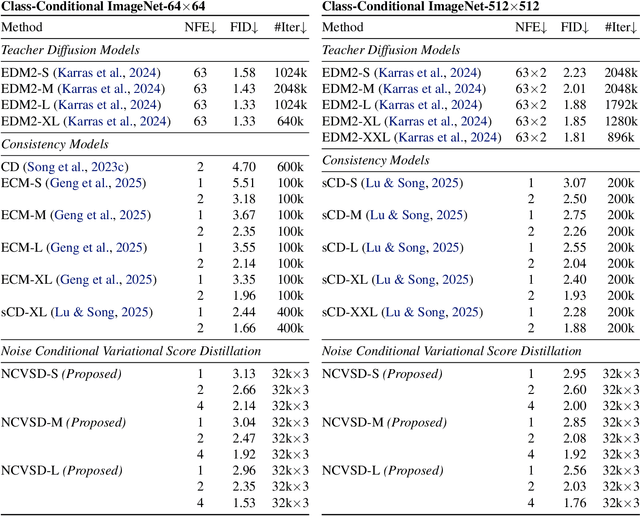
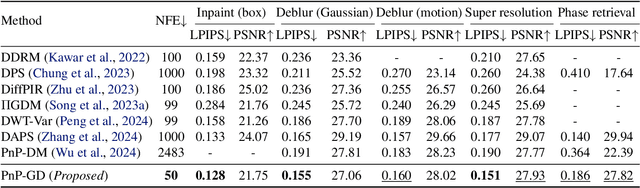

We propose Noise Conditional Variational Score Distillation (NCVSD), a novel method for distilling pretrained diffusion models into generative denoisers. We achieve this by revealing that the unconditional score function implicitly characterizes the score function of denoising posterior distributions. By integrating this insight into the Variational Score Distillation (VSD) framework, we enable scalable learning of generative denoisers capable of approximating samples from the denoising posterior distribution across a wide range of noise levels. The proposed generative denoisers exhibit desirable properties that allow fast generation while preserve the benefit of iterative refinement: (1) fast one-step generation through sampling from pure Gaussian noise at high noise levels; (2) improved sample quality by scaling the test-time compute with multi-step sampling; and (3) zero-shot probabilistic inference for flexible and controllable sampling. We evaluate NCVSD through extensive experiments, including class-conditional image generation and inverse problem solving. By scaling the test-time compute, our method outperforms teacher diffusion models and is on par with consistency models of larger sizes. Additionally, with significantly fewer NFEs than diffusion-based methods, we achieve record-breaking LPIPS on inverse problems.
HiPART: Hierarchical Pose AutoRegressive Transformer for Occluded 3D Human Pose Estimation
Mar 30, 2025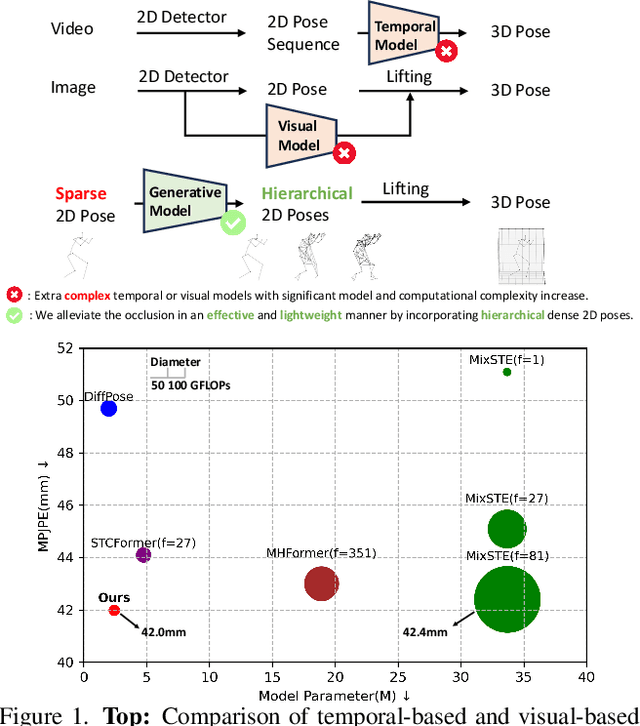
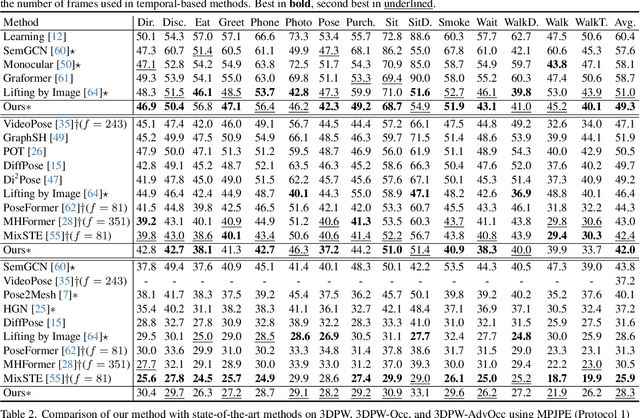
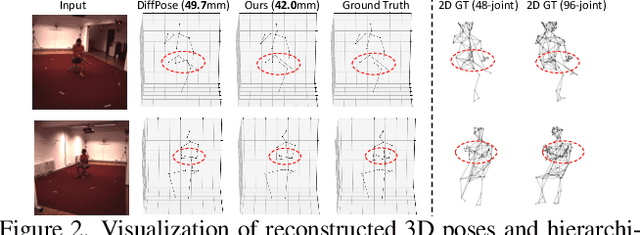
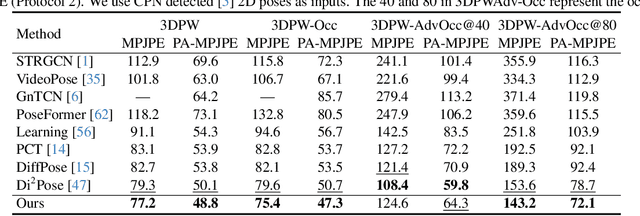
Existing 2D-to-3D human pose estimation (HPE) methods struggle with the occlusion issue by enriching information like temporal and visual cues in the lifting stage. In this paper, we argue that these methods ignore the limitation of the sparse skeleton 2D input representation, which fundamentally restricts the 2D-to-3D lifting and worsens the occlusion issue. To address these, we propose a novel two-stage generative densification method, named Hierarchical Pose AutoRegressive Transformer (HiPART), to generate hierarchical 2D dense poses from the original sparse 2D pose. Specifically, we first develop a multi-scale skeleton tokenization module to quantize the highly dense 2D pose into hierarchical tokens and propose a Skeleton-aware Alignment to strengthen token connections. We then develop a Hierarchical AutoRegressive Modeling scheme for hierarchical 2D pose generation. With generated hierarchical poses as inputs for 2D-to-3D lifting, the proposed method shows strong robustness in occluded scenarios and achieves state-of-the-art performance on the single-frame-based 3D HPE. Moreover, it outperforms numerous multi-frame methods while reducing parameter and computational complexity and can also complement them to further enhance performance and robustness.
On Disentangled Training for Nonlinear Transform in Learned Image Compression
Jan 23, 2025Learned image compression (LIC) has demonstrated superior rate-distortion (R-D) performance compared to traditional codecs, but is challenged by training inefficiency that could incur more than two weeks to train a state-of-the-art model from scratch. Existing LIC methods overlook the slow convergence caused by compacting energy in learning nonlinear transforms. In this paper, we first reveal that such energy compaction consists of two components, i.e., feature decorrelation and uneven energy modulation. On such basis, we propose a linear auxiliary transform (AuxT) to disentangle energy compaction in training nonlinear transforms. The proposed AuxT obtains coarse approximation to achieve efficient energy compaction such that distribution fitting with the nonlinear transforms can be simplified to fine details. We then develop wavelet-based linear shortcuts (WLSs) for AuxT that leverages wavelet-based downsampling and orthogonal linear projection for feature decorrelation and subband-aware scaling for uneven energy modulation. AuxT is lightweight and plug-and-play to be integrated into diverse LIC models to address the slow convergence issue. Experimental results demonstrate that the proposed approach can accelerate training of LIC models by 2 times and simultaneously achieves an average 1\% BD-rate reduction. To our best knowledge, this is one of the first successful attempt that can significantly improve the convergence of LIC with comparable or superior rate-distortion performance. Code will be released at \url{https://github.com/qingshi9974/AuxT}
LiftImage3D: Lifting Any Single Image to 3D Gaussians with Video Generation Priors
Dec 12, 2024



Single-image 3D reconstruction remains a fundamental challenge in computer vision due to inherent geometric ambiguities and limited viewpoint information. Recent advances in Latent Video Diffusion Models (LVDMs) offer promising 3D priors learned from large-scale video data. However, leveraging these priors effectively faces three key challenges: (1) degradation in quality across large camera motions, (2) difficulties in achieving precise camera control, and (3) geometric distortions inherent to the diffusion process that damage 3D consistency. We address these challenges by proposing LiftImage3D, a framework that effectively releases LVDMs' generative priors while ensuring 3D consistency. Specifically, we design an articulated trajectory strategy to generate video frames, which decomposes video sequences with large camera motions into ones with controllable small motions. Then we use robust neural matching models, i.e. MASt3R, to calibrate the camera poses of generated frames and produce corresponding point clouds. Finally, we propose a distortion-aware 3D Gaussian splatting representation, which can learn independent distortions between frames and output undistorted canonical Gaussians. Extensive experiments demonstrate that LiftImage3D achieves state-of-the-art performance on two challenging datasets, i.e. LLFF, DL3DV, and Tanks and Temples, and generalizes well to diverse in-the-wild images, from cartoon illustrations to complex real-world scenes.