 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Image Conditioned 3D Generation
Mar 22, 2026High-quality 3D assets are essential for VR/AR, industrial design, and entertainment, motivating growing interest in generative models that create 3D content from user prompts. Most existing 3D generators, however, rely on a single conditioning modality: image-conditioned models achieve high visual fidelity by exploiting pixel-aligned cues but suffer from viewpoint bias when the input view is limited or ambiguous, while text-conditioned models provide broad semantic guidance yet lack low-level visual detail. This limits how users can express intent and raises a natural question: can these two modalities be combined for more flexible and faithful 3D generation? Our diagnostic study shows that even simple late fusion of text- and image-conditioned predictions outperforms single-modality models, revealing strong cross-modal complementarity. We therefore formalize Text-Image Conditioned 3D Generation, which requires joint reasoning over a visual exemplar and a textual specification. To address this task, we introduce TIGON, a minimalist dual-branch baseline with separate image- and text-conditioned backbones and lightweight cross-modal fusion. Extensive experiments show that text-image conditioning consistently improves over single-modality methods, highlighting complementary vision-language guidance as a promising direction for future 3D generation research. Project page: https://jumpat.github.io/tigon-page
WorldGrow: Generating Infinite 3D World
Oct 24, 2025



We tackle the challenge of generating the infinitely extendable 3D world -- large, continuous environments with coherent geometry and realistic appearance. Existing methods face key challenges: 2D-lifting approaches suffer from geometric and appearance inconsistencies across views, 3D implicit representations are hard to scale up, and current 3D foundation models are mostly object-centric, limiting their applicability to scene-level generation. Our key insight is leveraging strong generation priors from pre-trained 3D models for structured scene block generation. To this end, we propose WorldGrow, a hierarchical framework for unbounded 3D scene synthesis. Our method features three core components: (1) a data curation pipeline that extracts high-quality scene blocks for training, making the 3D structured latent representations suitable for scene generation; (2) a 3D block inpainting mechanism that enables context-aware scene extension; and (3) a coarse-to-fine generation strategy that ensures both global layout plausibility and local geometric/textural fidelity. Evaluated on the large-scale 3D-FRONT dataset, WorldGrow achieves SOTA performance in geometry reconstruction, while uniquely supporting infinite scene generation with photorealistic and structurally consistent outputs. These results highlight its capability for constructing large-scale virtual environments and potential for building future world models.
Few-step Flow for 3D Generation via Marginal-Data Transport Distillation
Sep 04, 2025Flow-based 3D generation models typically require dozens of sampling steps during inference. Though few-step distillation methods, particularly Consistency Models (CMs), have achieved substantial advancements in accelerating 2D diffusion models, they remain under-explored for more complex 3D generation tasks. In this study, we propose a novel framework, MDT-dist, for few-step 3D flow distillation. Our approach is built upon a primary objective: distilling the pretrained model to learn the Marginal-Data Transport. Directly learning this objective needs to integrate the velocity fields, while this integral is intractable to be implemented. Therefore, we propose two optimizable objectives, Velocity Matching (VM) and Velocity Distillation (VD), to equivalently convert the optimization target from the transport level to the velocity and the distribution level respectively. Velocity Matching (VM) learns to stably match the velocity fields between the student and the teacher, but inevitably provides biased gradient estimates. Velocity Distillation (VD) further enhances the optimization process by leveraging the learned velocity fields to perform probability density distillation. When evaluated on the pioneer 3D generation framework TRELLIS, our method reduces sampling steps of each flow transformer from 25 to 1 or 2, achieving 0.68s (1 step x 2) and 0.94s (2 steps x 2) latency with 9.0x and 6.5x speedup on A800, while preserving high visual and geometric fidelity. Extensive experiments demonstrate that our method significantly outperforms existing CM distillation methods, and enables TRELLIS to achieve superior performance in few-step 3D generation.
Snap-Snap: Taking Two Images to Reconstruct 3D Human Gaussians in Milliseconds
Aug 20, 2025Reconstructing 3D human bodies from sparse views has been an appealing topic, which is crucial to broader the related applications. In this paper, we propose a quite challenging but valuable task to reconstruct the human body from only two images, i.e., the front and back view, which can largely lower the barrier for users to create their own 3D digital humans. The main challenges lie in the difficulty of building 3D consistency and recovering missing information from the highly sparse input. We redesign a geometry reconstruction model based on foundation reconstruction models to predict consistent point clouds even input images have scarce overlaps with extensive human data training. Furthermore, an enhancement algorithm is applied to supplement the missing color information, and then the complete human point clouds with colors can be obtained, which are directly transformed into 3D Gaussians for better rendering quality. Experiments show that our method can reconstruct the entire human in 190 ms on a single NVIDIA RTX 4090, with two images at a resolution of 1024x1024, demonstrating state-of-the-art performance on the THuman2.0 and cross-domain datasets. Additionally, our method can complete human reconstruction even with images captured by low-cost mobile devices, reducing the requirements for data collection. Demos and code are available at https://hustvl.github.io/Snap-Snap/.
Tackling View-Dependent Semantics in 3D Language Gaussian Splatting
May 30, 2025Recent advancements in 3D Gaussian Splatting (3D-GS) enable high-quality 3D scene reconstruction from RGB images. Many studies extend this paradigm for language-driven open-vocabulary scene understanding. However, most of them simply project 2D semantic features onto 3D Gaussians and overlook a fundamental gap between 2D and 3D understanding: a 3D object may exhibit various semantics from different viewpoints--a phenomenon we term view-dependent semantics. To address this challenge, we propose LaGa (Language Gaussians), which establishes cross-view semantic connections by decomposing the 3D scene into objects. Then, it constructs view-aggregated semantic representations by clustering semantic descriptors and reweighting them based on multi-view semantics. Extensive experiments demonstrate that LaGa effectively captures key information from view-dependent semantics, enabling a more comprehensive understanding of 3D scenes. Notably, under the same settings, LaGa achieves a significant improvement of +18.7% mIoU over the previous SOTA on the LERF-OVS dataset. Our code is available at: https://github.com/SJTU-DeepVisionLab/LaGa.
Dereflection Any Image with Diffusion Priors and Diversified Data
Mar 21, 2025Reflection removal of a single image remains a highly challenging task due to the complex entanglement between target scenes and unwanted reflections. Despite significant progress, existing methods are hindered by the scarcity of high-quality, diverse data and insufficient restoration priors, resulting in limited generalization across various real-world scenarios. In this paper, we propose Dereflection Any Image, a comprehensive solution with an efficient data preparation pipeline and a generalizable model for robust reflection removal. First, we introduce a dataset named Diverse Reflection Removal (DRR) created by randomly rotating reflective mediums in target scenes, enabling variation of reflection angles and intensities, and setting a new benchmark in scale, quality, and diversity. Second, we propose a diffusion-based framework with one-step diffusion for deterministic outputs and fast inference. To ensure stable learning, we design a three-stage progressive training strategy, including reflection-invariant finetuning to encourage consistent outputs across varying reflection patterns that characterize our dataset. Extensive experiments show that our method achieves SOTA performance on both common benchmarks and challenging in-the-wild images, showing superior generalization across diverse real-world scenes.
LiftImage3D: Lifting Any Single Image to 3D Gaussians with Video Generation Priors
Dec 12, 2024



Single-image 3D reconstruction remains a fundamental challenge in computer vision due to inherent geometric ambiguities and limited viewpoint information. Recent advances in Latent Video Diffusion Models (LVDMs) offer promising 3D priors learned from large-scale video data. However, leveraging these priors effectively faces three key challenges: (1) degradation in quality across large camera motions, (2) difficulties in achieving precise camera control, and (3) geometric distortions inherent to the diffusion process that damage 3D consistency. We address these challenges by proposing LiftImage3D, a framework that effectively releases LVDMs' generative priors while ensuring 3D consistency. Specifically, we design an articulated trajectory strategy to generate video frames, which decomposes video sequences with large camera motions into ones with controllable small motions. Then we use robust neural matching models, i.e. MASt3R, to calibrate the camera poses of generated frames and produce corresponding point clouds. Finally, we propose a distortion-aware 3D Gaussian splatting representation, which can learn independent distortions between frames and output undistorted canonical Gaussians. Extensive experiments demonstrate that LiftImage3D achieves state-of-the-art performance on two challenging datasets, i.e. LLFF, DL3DV, and Tanks and Temples, and generalizes well to diverse in-the-wild images, from cartoon illustrations to complex real-world scenes.
Segment Any 4D Gaussians
Jul 05, 2024



Modeling, understanding, and reconstructing the real world are crucial in XR/VR. Recently, 3D Gaussian Splatting (3D-GS) methods have shown remarkable success in modeling and understanding 3D scenes. Similarly, various 4D representations have demonstrated the ability to capture the dynamics of the 4D world. However, there is a dearth of research focusing on segmentation within 4D representations. In this paper, we propose Segment Any 4D Gaussians (SA4D), one of the first frameworks to segment anything in the 4D digital world based on 4D Gaussians. In SA4D, an efficient temporal identity feature field is introduced to handle Gaussian drifting, with the potential to learn precise identity features from noisy and sparse input. Additionally, a 4D segmentation refinement process is proposed to remove artifacts. Our SA4D achieves precise, high-quality segmentation within seconds in 4D Gaussians and shows the ability to remove, recolor, compose, and render high-quality anything masks. More demos are available at: https://jsxzs.github.io/sa4d/.
GaussianDreamerPro: Text to Manipulable 3D Gaussians with Highly Enhanced Quality
Jun 26, 2024Recently, 3D Gaussian splatting (3D-GS) has achieved great success in reconstructing and rendering real-world scenes. To transfer the high rendering quality to generation tasks, a series of research works attempt to generate 3D-Gaussian assets from text. However, the generated assets have not achieved the same quality as those in reconstruction tasks. We observe that Gaussians tend to grow without control as the generation process may cause indeterminacy. Aiming at highly enhancing the generation quality, we propose a novel framework named GaussianDreamerPro. The main idea is to bind Gaussians to reasonable geometry, which evolves over the whole generation process. Along different stages of our framework, both the geometry and appearance can be enriched progressively. The final output asset is constructed with 3D Gaussians bound to mesh, which shows significantly enhanced details and quality compared with previous methods. Notably, the generated asset can also be seamlessly integrated into downstream manipulation pipelines, e.g. animation, composition, and simulation etc., greatly promoting its potential in wide applications. Demos are available at https://taoranyi.com/gaussiandreamerpro/.
GaussianObject: Just Taking Four Images to Get A High-Quality 3D Object with Gaussian Splatting
Feb 20, 2024

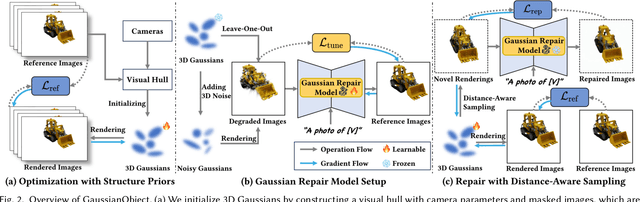
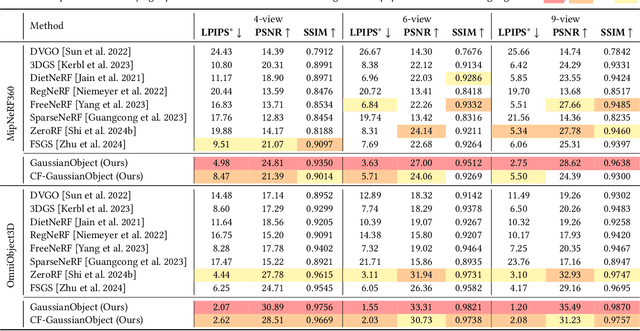
Reconstructing and rendering 3D objects from highly sparse views is of critical importance for promoting applications of 3D vision techniques and improving user experience. However, images from sparse views only contain very limited 3D information, leading to two significant challenges: 1) Difficulty in building multi-view consistency as images for matching are too few; 2) Partially omitted or highly compressed object information as view coverage is insufficient. To tackle these challenges, we propose GaussianObject, a framework to represent and render the 3D object with Gaussian splatting, that achieves high rendering quality with only 4 input images. We first introduce techniques of visual hull and floater elimination which explicitly inject structure priors into the initial optimization process for helping build multi-view consistency, yielding a coarse 3D Gaussian representation. Then we construct a Gaussian repair model based on diffusion models to supplement the omitted object information, where Gaussians are further refined. We design a self-generating strategy to obtain image pairs for training the repair model. Our GaussianObject is evaluated on several challenging datasets, including MipNeRF360, OmniObject3D, and OpenIllumination, achieving strong reconstruction results from only 4 views and significantly outperforming previous state-of-the-art methods.