 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldGrow: Generating Infinite 3D World
Oct 24, 2025



We tackle the challenge of generating the infinitely extendable 3D world -- large, continuous environments with coherent geometry and realistic appearance. Existing methods face key challenges: 2D-lifting approaches suffer from geometric and appearance inconsistencies across views, 3D implicit representations are hard to scale up, and current 3D foundation models are mostly object-centric, limiting their applicability to scene-level generation. Our key insight is leveraging strong generation priors from pre-trained 3D models for structured scene block generation. To this end, we propose WorldGrow, a hierarchical framework for unbounded 3D scene synthesis. Our method features three core components: (1) a data curation pipeline that extracts high-quality scene blocks for training, making the 3D structured latent representations suitable for scene generation; (2) a 3D block inpainting mechanism that enables context-aware scene extension; and (3) a coarse-to-fine generation strategy that ensures both global layout plausibility and local geometric/textural fidelity. Evaluated on the large-scale 3D-FRONT dataset, WorldGrow achieves SOTA performance in geometry reconstruction, while uniquely supporting infinite scene generation with photorealistic and structurally consistent outputs. These results highlight its capability for constructing large-scale virtual environments and potential for building future world models.
Tackling View-Dependent Semantics in 3D Language Gaussian Splatting
May 30, 2025Recent advancements in 3D Gaussian Splatting (3D-GS) enable high-quality 3D scene reconstruction from RGB images. Many studies extend this paradigm for language-driven open-vocabulary scene understanding. However, most of them simply project 2D semantic features onto 3D Gaussians and overlook a fundamental gap between 2D and 3D understanding: a 3D object may exhibit various semantics from different viewpoints--a phenomenon we term view-dependent semantics. To address this challenge, we propose LaGa (Language Gaussians), which establishes cross-view semantic connections by decomposing the 3D scene into objects. Then, it constructs view-aggregated semantic representations by clustering semantic descriptors and reweighting them based on multi-view semantics. Extensive experiments demonstrate that LaGa effectively captures key information from view-dependent semantics, enabling a more comprehensive understanding of 3D scenes. Notably, under the same settings, LaGa achieves a significant improvement of +18.7% mIoU over the previous SOTA on the LERF-OVS dataset. Our code is available at: https://github.com/SJTU-DeepVisionLab/LaGa.
Segment Any 4D Gaussians
Jul 05, 2024



Modeling, understanding, and reconstructing the real world are crucial in XR/VR. Recently, 3D Gaussian Splatting (3D-GS) methods have shown remarkable success in modeling and understanding 3D scenes. Similarly, various 4D representations have demonstrated the ability to capture the dynamics of the 4D world. However, there is a dearth of research focusing on segmentation within 4D representations. In this paper, we propose Segment Any 4D Gaussians (SA4D), one of the first frameworks to segment anything in the 4D digital world based on 4D Gaussians. In SA4D, an efficient temporal identity feature field is introduced to handle Gaussian drifting, with the potential to learn precise identity features from noisy and sparse input. Additionally, a 4D segmentation refinement process is proposed to remove artifacts. Our SA4D achieves precise, high-quality segmentation within seconds in 4D Gaussians and shows the ability to remove, recolor, compose, and render high-quality anything masks. More demos are available at: https://jsxzs.github.io/sa4d/.
Segment Any 3D Gaussians
Dec 01, 2023



Interactive 3D segmentation in radiance fields is an appealing task since its importance in 3D scene understanding and manipulation. However, existing methods face challenges in either achieving fine-grained, multi-granularity segmentation or contending with substantial computational overhead, inhibiting real-time interaction. In this paper, we introduce Segment Any 3D GAussians (SAGA), a novel 3D interactive segmentation approach that seamlessly blends a 2D segmentation foundation model with 3D Gaussian Splatting (3DGS), a recent breakthrough of radiance fields. SAGA efficiently embeds multi-granularity 2D segmentation results generated by the segmentation foundation model into 3D Gaussian point features through well-designed contrastive training. Evaluation on existing benchmarks demonstrates that SAGA can achieve competitive performance with state-of-the-art methods. Moreover, SAGA achieves multi-granularity segmentation and accommodates various prompts, including points, scribbles, and 2D masks. Notably, SAGA can finish the 3D segmentation within milliseconds, achieving nearly 1000x acceleration compared to previous SOTA. The project page is at https://jumpat.github.io/SAGA.
Segment Anything in 3D with NeRFs
Apr 26, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any object/part in various 2D images, yet its ability for 3D has not been fully explored. The real world is composed of numerous 3D scenes and objects. Due to the scarcity of accessible 3D data and high cost of its acquisition and annotation, lifting SAM to 3D is a challenging but valuable research avenue. With this in mind, we propose a novel framework to Segment Anything in 3D, named SA3D. Given a neural radiance field (NeRF) model, SA3D allows users to obtain the 3D segmentation result of any target object via only one-shot manual prompting in a single rendered view. With input prompts, SAM cuts out the target object from the according view. The obtained 2D segmentation mask is projected onto 3D mask grids via density-guided inverse rendering. 2D masks from other views are then rendered, which are mostly uncompleted but used as cross-view self-prompts to be fed into SAM again. Complete masks can be obtained and projected onto mask grids. This procedure is executed via an iterative manner while accurate 3D masks can be finally learned. SA3D can adapt to various radiance fields effectively without any additional redesigning. The entire segmentation process can be completed in approximately two minutes without any engineering optimization. Our experiments demonstrate the effectiveness of SA3D in different scenes, highlighting the potential of SAM in 3D scene perception. The project page is at https://jumpat.github.io/SA3D/.
A Survey on Label-efficient Deep Segmentation: Bridging the Gap between Weak Supervision and Dense Prediction
Jul 04, 2022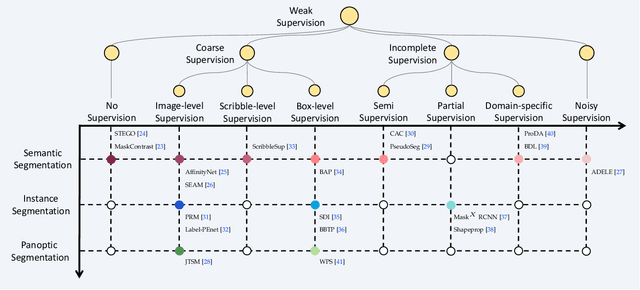
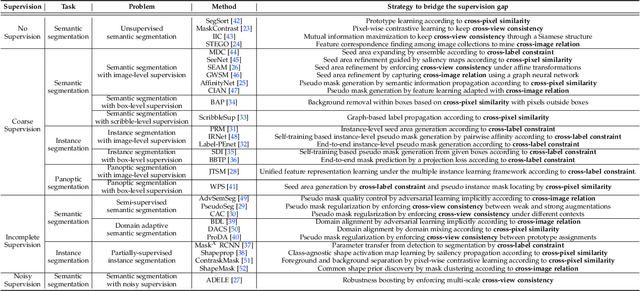

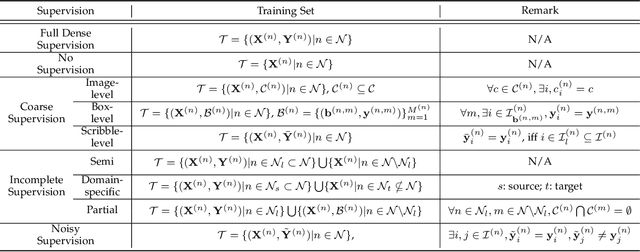
The rapid development of deep learning has made a great progress in segmentation, one of the fundamental tasks of computer vision. However, the current segmentation algorithms mostly rely on the availability of pixel-level annotations, which are often expensive, tedious, and laborious. To alleviate this burden, the past years have witnessed an increasing attention in building label-efficient, deep-learning-based segmentation algorithms. This paper offers a comprehensive review on label-efficient segmentation methods. To this end, we first develop a taxonomy to organize these methods according to the supervision provided by different types of weak labels (including no supervision, coarse supervision, incomplete supervision and noisy supervision) and supplemented by the types of segmentation problems (including semantic segmentation, instance segmentation and panoptic segmentation). Next, we summarize the existing label-efficient segmentation methods from a unified perspective that discusses an important question: how to bridge the gap between weak supervision and dense prediction -- the current methods are mostly based on heuristic priors, such as cross-pixel similarity, cross-label constraint, cross-view consistency, cross-image relation, etc. Finally, we share our opinions about the future research directions for label-efficient deep segmentation.
Consensus Synergizes with Memory: A Simple Approach for Anomaly Segmentation in Urban Scenes
Nov 24, 2021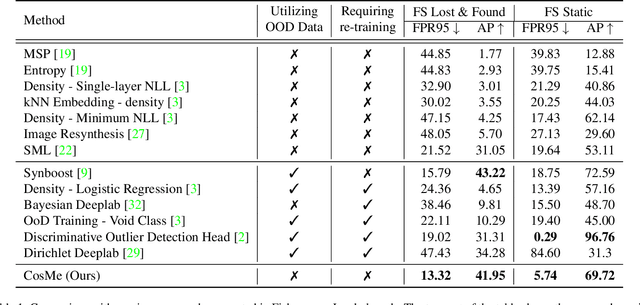
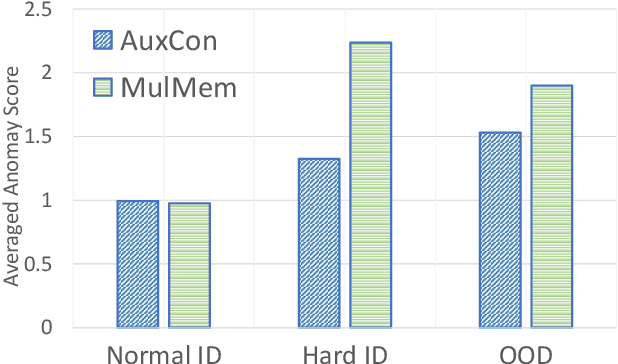
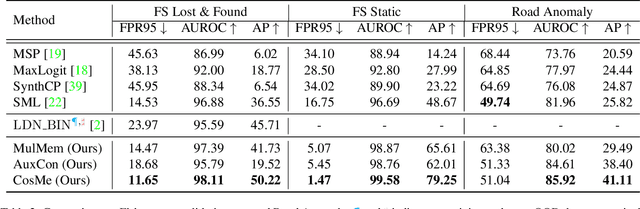
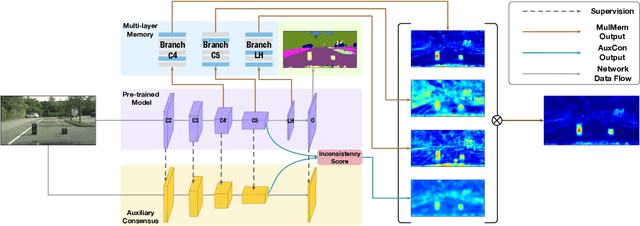
Anomaly segmentation is a crucial task for safety-critical applications, such as autonomous driving in urban scenes, where the goal is to detect out-of-distribution (OOD) objects with categories which are unseen during training. The core challenge of this task is how to distinguish hard in-distribution samples from OOD samples, which has not been explicitly discussed yet. In this paper, we propose a novel and simple approach named Consensus Synergizes with Memory (CosMe) to address this challenge, inspired by the psychology finding that groups perform better than individuals on memory tasks. The main idea is 1) building a memory bank which consists of seen prototypes extracted from multiple layers of the pre-trained segmentation model and 2) training an auxiliary model that mimics the behavior of the pre-trained model, and then measuring the consensus of their mid-level features as complementary cues that synergize with the memory bank. CosMe is good at distinguishing between hard in-distribution examples and OOD samples. Experimental results on several urban scene anomaly segmentation datasets show that CosMe outperforms previous approaches by large margins.