 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneCAT: Decoder-Only Auto-Regressive Model for Unified Understanding and Generation
Sep 03, 2025
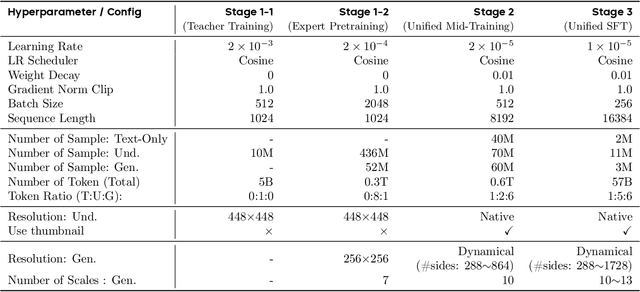


We introduce OneCAT, a unified multimodal model that seamlessly integrates understanding, generation, and editing within a novel, pure decoder-only transformer architecture. Our framework uniquely eliminates the need for external components such as Vision Transformers (ViT) or vision tokenizer during inference, leading to significant efficiency gains, especially for high-resolution inputs. This is achieved through a modality-specific Mixture-of-Experts (MoE) structure trained with a single autoregressive (AR) objective, which also natively supports dynamic resolutions. Furthermore, we pioneer a multi-scale visual autoregressive mechanism within the Large Language Model (LLM) that drastically reduces decoding steps compared to diffusion-based methods while maintaining state-of-the-art performance. Our findings demonstrate the powerful potential of pure autoregressive modeling as a sufficient and elegant foundation for unified multimodal intelligence. As a result, OneCAT sets a new performance standard, outperforming existing open-source unified multimodal models across benchmarks for multimodal generation, editing, and understanding.
NEARL-CLIP: Interacted Query Adaptation with Orthogonal Regularization for Medical Vision-Language Understanding
Aug 06, 2025



Computer-aided medical image analysis is crucial for disease diagnosis and treatment planning, yet limited annotated datasets restrict medical-specific model development. While vision-language models (VLMs) like CLIP offer strong generalization capabilities, their direct application to medical imaging analysis is impeded by a significant domain gap. Existing approaches to bridge this gap, including prompt learning and one-way modality interaction techniques, typically focus on introducing domain knowledge to a single modality. Although this may offer performance gains, it often causes modality misalignment, thereby failing to unlock the full potential of VLMs. In this paper, we propose \textbf{NEARL-CLIP} (i\underline{N}teracted qu\underline{E}ry \underline{A}daptation with o\underline{R}thogona\underline{L} Regularization), a novel cross-modality interaction VLM-based framework that contains two contributions: (1) Unified Synergy Embedding Transformer (USEformer), which dynamically generates cross-modality queries to promote interaction between modalities, thus fostering the mutual enrichment and enhancement of multi-modal medical domain knowledge; (2) Orthogonal Cross-Attention Adapter (OCA). OCA introduces an orthogonality technique to decouple the new knowledge from USEformer into two distinct components: the truly novel information and the incremental knowledge. By isolating the learning process from the interference of incremental knowledge, OCA enables a more focused acquisition of new information, thereby further facilitating modality interaction and unleashing the capability of VLMs. Notably, NEARL-CLIP achieves these two contributions in a parameter-efficient style, which only introduces \textbf{1.46M} learnable parameters.
MedSeg-R: Reasoning Segmentation in Medical Images with Multimodal Large Language Models
Jun 12, 2025



Medical image segmentation is crucial for clinical diagnosis, yet existing models are limited by their reliance on explicit human instructions and lack the active reasoning capabilities to understand complex clinical questions. While recent advancements in multimodal large language models (MLLMs) have improved medical question-answering (QA) tasks, most methods struggle to generate precise segmentation masks, limiting their application in automatic medical diagnosis. In this paper, we introduce medical image reasoning segmentation, a novel task that aims to generate segmentation masks based on complex and implicit medical instructions. To address this, we propose MedSeg-R, an end-to-end framework that leverages the reasoning abilities of MLLMs to interpret clinical questions while also capable of producing corresponding precise segmentation masks for medical images. It is built on two core components: 1) a global context understanding module that interprets images and comprehends complex medical instructions to generate multi-modal intermediate tokens, and 2) a pixel-level grounding module that decodes these tokens to produce precise segmentation masks and textual responses. Furthermore, we introduce MedSeg-QA, a large-scale dataset tailored for the medical image reasoning segmentation task. It includes over 10,000 image-mask pairs and multi-turn conversations, automatically annotated using large language models and refined through physician reviews. Experiments show MedSeg-R's superior performance across several benchmarks, achieving high segmentation accuracy and enabling interpretable textual analysis of medical images.
Seeing Far and Clearly: Mitigating Hallucinations in MLLMs with Attention Causal Decoding
May 22, 2025Recent advancements in multimodal large language models (MLLMs) have significantly improved performance in visual question answering. However, they often suffer from hallucinations. In this work, hallucinations are categorized into two main types: initial hallucinations and snowball hallucinations. We argue that adequate contextual information can be extracted directly from the token interaction process. Inspired by causal inference in the decoding strategy, we propose to leverage causal masks to establish information propagation between multimodal tokens. The hypothesis is that insufficient interaction between those tokens may lead the model to rely on outlier tokens, overlooking dense and rich contextual cues. Therefore, we propose to intervene in the propagation process by tackling outlier tokens to enhance in-context inference. With this goal, we present FarSight, a versatile plug-and-play decoding strategy to reduce attention interference from outlier tokens merely by optimizing the causal mask. The heart of our method is effective token propagation. We design an attention register structure within the upper triangular matrix of the causal mask, dynamically allocating attention to capture attention diverted to outlier tokens. Moreover, a positional awareness encoding method with a diminishing masking rate is proposed, allowing the model to attend to further preceding tokens, especially for video sequence tasks. With extensive experiments, FarSight demonstrates significant hallucination-mitigating performance across different MLLMs on both image and video benchmarks, proving its effectiveness.
ACMamba: Fast Unsupervised Anomaly Detection via An Asymmetrical Consensus State Space Model
Apr 16, 2025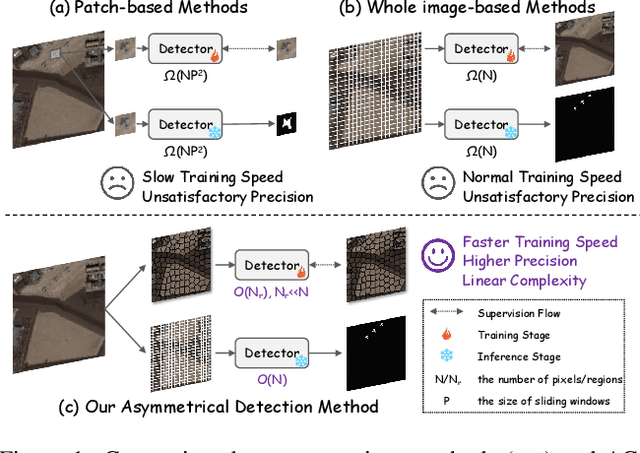
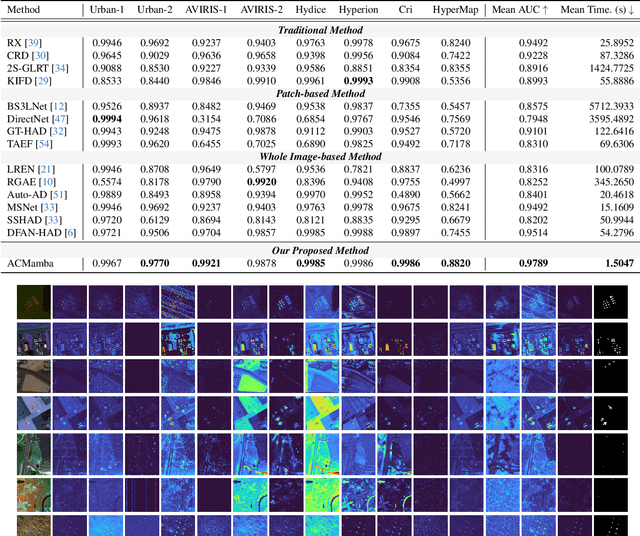
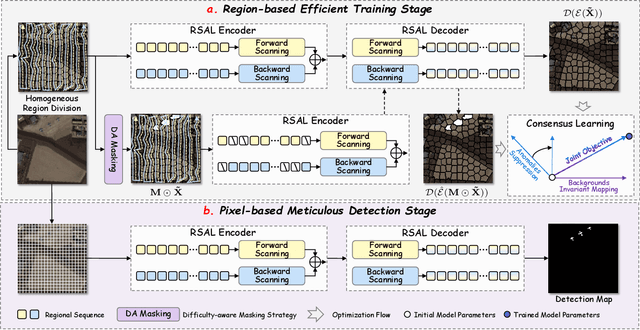
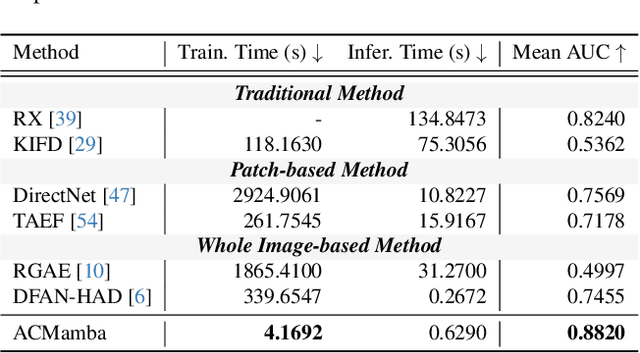
Unsupervised anomaly detection in hyperspectral images (HSI), aiming to detect unknown targets from backgrounds, is challenging for earth surface monitoring. However, current studies are hindered by steep computational costs due to the high-dimensional property of HSI and dense sampling-based training paradigm, constraining their rapid deployment. Our key observation is that, during training, not all samples within the same homogeneous area are indispensable, whereas ingenious sampling can provide a powerful substitute for reducing costs. Motivated by this, we propose an Asymmetrical Consensus State Space Model (ACMamba) to significantly reduce computational costs without compromising accuracy. Specifically, we design an asymmetrical anomaly detection paradigm that utilizes region-level instances as an efficient alternative to dense pixel-level samples. In this paradigm, a low-cost Mamba-based module is introduced to discover global contextual attributes of regions that are essential for HSI reconstruction. Additionally, we develop a consensus learning strategy from the optimization perspective to simultaneously facilitate background reconstruction and anomaly compression, further alleviating the negative impact of anomaly reconstruction. Theoretical analysis and extensive experiments across eight benchmarks verify the superiority of ACMamba, demonstrating a faster speed and stronger performance over the state-of-the-art.
ScalingNoise: Scaling Inference-Time Search for Generating Infinite Videos
Mar 20, 2025Video diffusion models (VDMs) facilitate the generation of high-quality videos, with current research predominantly concentrated on scaling efforts during training through improvements in data quality, computational resources, and model complexity. However, inference-time scaling has received less attention, with most approaches restricting models to a single generation attempt. Recent studies have uncovered the existence of "golden noises" that can enhance video quality during generation. Building on this, we find that guiding the scaling inference-time search of VDMs to identify better noise candidates not only evaluates the quality of the frames generated in the current step but also preserves the high-level object features by referencing the anchor frame from previous multi-chunks, thereby delivering long-term value. Our analysis reveals that diffusion models inherently possess flexible adjustments of computation by varying denoising steps, and even a one-step denoising approach, when guided by a reward signal, yields significant long-term benefits. Based on the observation, we proposeScalingNoise, a plug-and-play inference-time search strategy that identifies golden initial noises for the diffusion sampling process to improve global content consistency and visual diversity. Specifically, we perform one-step denoising to convert initial noises into a clip and subsequently evaluate its long-term value, leveraging a reward model anchored by previously generated content. Moreover, to preserve diversity, we sample candidates from a tilted noise distribution that up-weights promising noises. In this way, ScalingNoise significantly reduces noise-induced errors, ensuring more coherent and spatiotemporally consistent video generation. Extensive experiments on benchmark datasets demonstrate that the proposed ScalingNoise effectively improves long video generation.
OphCLIP: Hierarchical Retrieval-Augmented Learning for Ophthalmic Surgical Video-Language Pretraining
Nov 23, 2024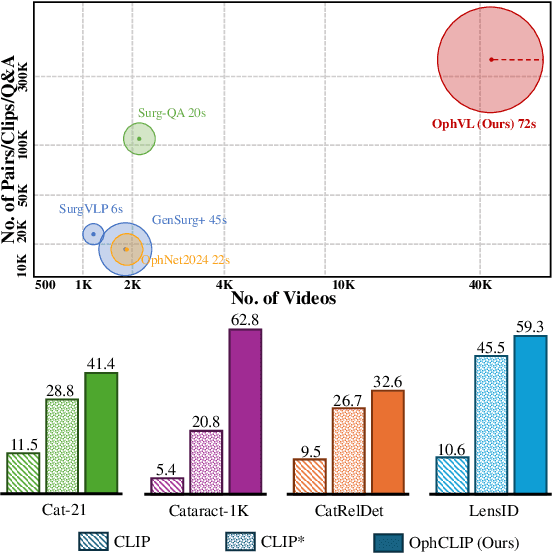
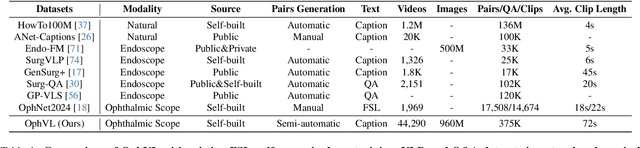
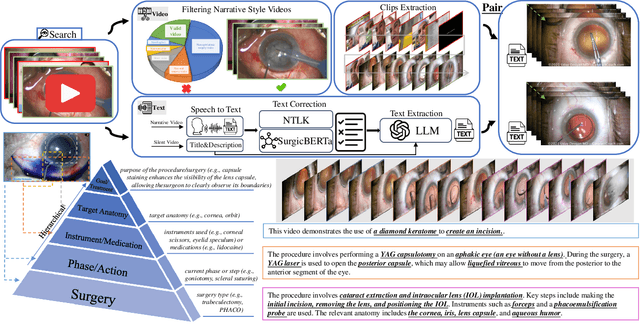
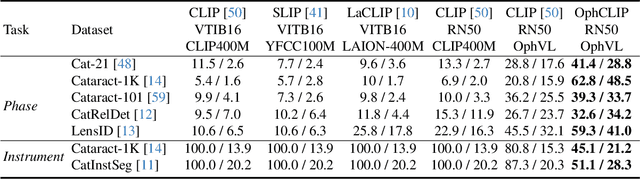
Surgical practice involves complex visual interpretation, procedural skills, and advanced medical knowledge, making surgical vision-language pretraining (VLP) particularly challenging due to this complexity and the limited availability of annotated data. To address the gap, we propose OphCLIP, a hierarchical retrieval-augmented vision-language pretraining framework specifically designed for ophthalmic surgical workflow understanding. OphCLIP leverages the OphVL dataset we constructed, a large-scale and comprehensive collection of over 375K hierarchically structured video-text pairs with tens of thousands of different combinations of attributes (surgeries, phases/operations/actions, instruments, medications, as well as more advanced aspects like the causes of eye diseases, surgical objectives, and postoperative recovery recommendations, etc). These hierarchical video-text correspondences enable OphCLIP to learn both fine-grained and long-term visual representations by aligning short video clips with detailed narrative descriptions and full videos with structured titles, capturing intricate surgical details and high-level procedural insights, respectively. Our OphCLIP also designs a retrieval-augmented pretraining framework to leverage the underexplored large-scale silent surgical procedure videos, automatically retrieving semantically relevant content to enhance the representation learning of narrative videos. Evaluation across 11 datasets for phase recognition and multi-instrument identification shows OphCLIP's robust generalization and superior performance.
Parameter-efficient Fine-tuning in Hyperspherical Space for Open-vocabulary Semantic Segmentation
May 29, 2024Open-vocabulary semantic segmentation seeks to label each pixel in an image with arbitrary text descriptions. Vision-language foundation models, especially CLIP, have recently emerged as powerful tools for acquiring open-vocabulary capabilities. However, fine-tuning CLIP to equip it with pixel-level prediction ability often suffers three issues: 1) high computational cost, 2) misalignment between the two inherent modalities of CLIP, and 3) degraded generalization ability on unseen categories. To address these issues, we propose H-CLIP a symmetrical parameter-efficient fine-tuning (PEFT) strategy conducted in hyperspherical space for both of the two CLIP modalities. Specifically, the PEFT strategy is achieved by a series of efficient block-diagonal learnable transformation matrices and a dual cross-relation communication module among all learnable matrices. Since the PEFT strategy is conducted symmetrically to the two CLIP modalities, the misalignment between them is mitigated. Furthermore, we apply an additional constraint to PEFT on the CLIP text encoder according to the hyperspherical energy principle, i.e., minimizing hyperspherical energy during fine-tuning preserves the intrinsic structure of the original parameter space, to prevent the destruction of the generalization ability offered by the CLIP text encoder. Extensive evaluations across various benchmarks show that H-CLIP achieves new SOTA open-vocabulary semantic segmentation results while only requiring updating approximately 4% of the total parameters of CLIP.
S$^2$Mamba: A Spatial-spectral State Space Model for Hyperspectral Image Classification
Apr 28, 2024



Land cover analysis using hyperspectral images (HSI) remains an open problem due to their low spatial resolution and complex spectral information. Recent studies are primarily dedicated to designing Transformer-based architectures for spatial-spectral long-range dependencies modeling, which is computationally expensive with quadratic complexity. Selective structured state space model (Mamba), which is efficient for modeling long-range dependencies with linear complexity, has recently shown promising progress. However, its potential in hyperspectral image processing that requires handling numerous spectral bands has not yet been explored. In this paper, we innovatively propose S$^2$Mamba, a spatial-spectral state space model for hyperspectral image classification, to excavate spatial-spectral contextual features, resulting in more efficient and accurate land cover analysis. In S$^2$Mamba, two selective structured state space models through different dimensions are designed for feature extraction, one for spatial, and the other for spectral, along with a spatial-spectral mixture gate for optimal fusion. More specifically, S$^2$Mamba first captures spatial contextual relations by interacting each pixel with its adjacent through a Patch Cross Scanning module and then explores semantic information from continuous spectral bands through a Bi-directional Spectral Scanning module. Considering the distinct expertise of the two attributes in homogenous and complicated texture scenes, we realize the Spatial-spectral Mixture Gate by a group of learnable matrices, allowing for the adaptive incorporation of representations learned across different dimensions. Extensive experiments conducted on HSI classification benchmarks demonstrate the superiority and prospect of S$^2$Mamba. The code will be available at: https://github.com/PURE-melo/S2Mamba.
Parameter Efficient Fine-tuning via Cross Block Orchestration for Segment Anything Model
Nov 28, 2023Parameter-efficient fine-tuning (PEFT) is an effective methodology to unleash the potential of large foundation models in novel scenarios with limited training data. In the computer vision community, PEFT has shown effectiveness in image classification, but little research has studied its ability for image segmentation. Fine-tuning segmentation models usually require a heavier adjustment of parameters to align the proper projection directions in the parameter space for new scenarios. This raises a challenge to existing PEFT algorithms, as they often inject a limited number of individual parameters into each block, which prevents substantial adjustment of the projection direction of the parameter space due to the limitation of Hidden Markov Chain along blocks. In this paper, we equip PEFT with a cross-block orchestration mechanism to enable the adaptation of the Segment Anything Model (SAM) to various downstream scenarios. We introduce a novel inter-block communication module, which integrates a learnable relation matrix to facilitate communication among different coefficient sets of each PEFT block's parameter space. Moreover, we propose an intra-block enhancement module, which introduces a linear projection head whose weights are generated from a hyper-complex layer, further enhancing the impact of the adjustment of projection directions on the entire parameter space. Extensive experiments on diverse benchmarks demonstrate that our proposed approach consistently improves the segmentation performance significantly on novel scenarios with only around 1K additional parameters.