 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking in Uncertainty: Mitigating Hallucinations in MLRMs with Latent Entropy-Aware Decoding
Mar 09, 2026Recent advancements in multimodal large reasoning models (MLRMs) have significantly improved performance in visual question answering. However, we observe that transition words (e.g., because, however, and wait) are closely associated with hallucinations and tend to exhibit high-entropy states. We argue that adequate contextual reasoning information can be directly extracted from the token probability distribution. Inspired by superposed representation theory, we propose leveraging latent superposed reasoning to integrate multiple candidate semantics and maintain latent reasoning trajectories. The hypothesis is that reliance on discrete textual inputs may drive the model toward sequential explicit reasoning, underutilizing dense contextual cues during high-entropy reasoning stages. Therefore, we propose constructing rich semantic representations from the token probability distributions to enhance in-context reasoning. With this goal, we present Latent Entropy-Aware Decoding (LEAD), an efficient plug-and-play decoding strategy that leverages semantic context to achieve reliable reasoning. The heart of our method lies in entropy-aware reasoning mode switching. The model employs probability-weighted continuous embeddings under high-entropy states and transitions back to discrete token embeddings as entropy decreases. Moreover, we propose a prior-guided visual anchor injection strategy that encourages the model to focus on visual information. Extensive experiments show that LEAD effectively mitigates hallucinations across various MLRMs on multiple benchmarks.
PsychEthicsBench: Evaluating Large Language Models Against Australian Mental Health Ethics
Jan 07, 2026The increasing integration of large language models (LLMs) into mental health applications necessitates robust frameworks for evaluating professional safety alignment. Current evaluative approaches primarily rely on refusal-based safety signals, which offer limited insight into the nuanced behaviors required in clinical practice. In mental health, clinically inadequate refusals can be perceived as unempathetic and discourage help-seeking. To address this gap, we move beyond refusal-centric metrics and introduce \texttt{PsychEthicsBench}, the first principle-grounded benchmark based on Australian psychology and psychiatry guidelines, designed to evaluate LLMs' ethical knowledge and behavioral responses through multiple-choice and open-ended tasks with fine-grained ethicality annotations. Empirical results across 14 models reveal that refusal rates are poor indicators of ethical behavior, revealing a significant divergence between safety triggers and clinical appropriateness. Notably, we find that domain-specific fine-tuning can degrade ethical robustness, as several specialized models underperform their base backbones in ethical alignment. PsychEthicsBench provides a foundation for systematic, jurisdiction-aware evaluation of LLMs in mental health, encouraging more responsible development in this domain.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Seeing Far and Clearly: Mitigating Hallucinations in MLLMs with Attention Causal Decoding
May 22, 2025Recent advancements in multimodal large language models (MLLMs) have significantly improved performance in visual question answering. However, they often suffer from hallucinations. In this work, hallucinations are categorized into two main types: initial hallucinations and snowball hallucinations. We argue that adequate contextual information can be extracted directly from the token interaction process. Inspired by causal inference in the decoding strategy, we propose to leverage causal masks to establish information propagation between multimodal tokens. The hypothesis is that insufficient interaction between those tokens may lead the model to rely on outlier tokens, overlooking dense and rich contextual cues. Therefore, we propose to intervene in the propagation process by tackling outlier tokens to enhance in-context inference. With this goal, we present FarSight, a versatile plug-and-play decoding strategy to reduce attention interference from outlier tokens merely by optimizing the causal mask. The heart of our method is effective token propagation. We design an attention register structure within the upper triangular matrix of the causal mask, dynamically allocating attention to capture attention diverted to outlier tokens. Moreover, a positional awareness encoding method with a diminishing masking rate is proposed, allowing the model to attend to further preceding tokens, especially for video sequence tasks. With extensive experiments, FarSight demonstrates significant hallucination-mitigating performance across different MLLMs on both image and video benchmarks, proving its effectiveness.
Incomplete Modality Disentangled Representation for Ophthalmic Disease Grading and Diagnosis
Feb 17, 2025



Ophthalmologists typically require multimodal data sources to improve diagnostic accuracy in clinical decisions. However, due to medical device shortages, low-quality data and data privacy concerns, missing data modalities are common in real-world scenarios. Existing deep learning methods tend to address it by learning an implicit latent subspace representation for different modality combinations. We identify two significant limitations of these methods: (1) implicit representation constraints that hinder the model's ability to capture modality-specific information and (2) modality heterogeneity, causing distribution gaps and redundancy in feature representations. To address these, we propose an Incomplete Modality Disentangled Representation (IMDR) strategy, which disentangles features into explicit independent modal-common and modal-specific features by guidance of mutual information, distilling informative knowledge and enabling it to reconstruct valuable missing semantics and produce robust multimodal representations. Furthermore, we introduce a joint proxy learning module that assists IMDR in eliminating intra-modality redundancy by exploiting the extracted proxies from each class. Experiments on four ophthalmology multimodal datasets demonstrate that the proposed IMDR outperforms the state-of-the-art methods significantly.
* 7 Pages, 6 figures
MMRC: A Large-Scale Benchmark for Understanding Multimodal Large Language Model in Real-World Conversation
Feb 17, 2025Recent multimodal large language models (MLLMs) have demonstrated significant potential in open-ended conversation, generating more accurate and personalized responses. However, their abilities to memorize, recall, and reason in sustained interactions within real-world scenarios remain underexplored. This paper introduces MMRC, a Multi-Modal Real-world Conversation benchmark for evaluating six core open-ended abilities of MLLMs: information extraction, multi-turn reasoning, information update, image management, memory recall, and answer refusal. With data collected from real-world scenarios, MMRC comprises 5,120 conversations and 28,720 corresponding manually labeled questions, posing a significant challenge to existing MLLMs. Evaluations on 20 MLLMs in MMRC indicate an accuracy drop during open-ended interactions. We identify four common failure patterns: long-term memory degradation, inadequacies in updating factual knowledge, accumulated assumption of error propagation, and reluctance to say no. To mitigate these issues, we propose a simple yet effective NOTE-TAKING strategy, which can record key information from the conversation and remind the model during its responses, enhancing conversational capabilities. Experiments across six MLLMs demonstrate significant performance improvements.
Toward Modality Gap: Vision Prototype Learning for Weakly-supervised Semantic Segmentation with CLIP
Dec 27, 2024



The application of Contrastive Language-Image Pre-training (CLIP) in Weakly Supervised Semantic Segmentation (WSSS) research powerful cross-modal semantic understanding capabilities. Existing methods attempt to optimize input text prompts for improved alignment of images and text, by finely adjusting text prototypes to facilitate semantic matching. Nevertheless, given the modality gap between text and vision spaces, the text prototypes employed by these methods have not effectively established a close correspondence with pixel-level vision features. In this work, our theoretical analysis indicates that the inherent modality gap results in misalignment of text and region features, and that this gap cannot be sufficiently reduced by minimizing contrast loss in CLIP. To mitigate the impact of the modality gap, we propose a Vision Prototype Learning (VPL) framework, by introducing more representative vision prototypes. The core of this framework is to learn class-specific vision prototypes in vision space with the help of text prototypes, for capturing high-quality localization maps. Moreover, we propose a regional semantic contrast module that contrasts regions embedding with corresponding prototypes, leading to more comprehensive and robust feature learning. Experimental results show that our proposed framework achieves state-of-the-art performance on two benchmark datasets.
Neighbor Does Matter: Density-Aware Contrastive Learning for Medical Semi-supervised Segmentation
Dec 27, 2024



In medical image analysis, multi-organ semi-supervised segmentation faces challenges such as insufficient labels and low contrast in soft tissues. To address these issues, existing studies typically employ semi-supervised segmentation techniques using pseudo-labeling and consistency regularization. However, these methods mainly rely on individual data samples for training, ignoring the rich neighborhood information present in the feature space. In this work, we argue that supervisory information can be directly extracted from the geometry of the feature space. Inspired by the density-based clustering hypothesis, we propose using feature density to locate sparse regions within feature clusters. Our goal is to increase intra-class compactness by addressing sparsity issues. To achieve this, we propose a Density-Aware Contrastive Learning (DACL) strategy, pushing anchored features in sparse regions towards cluster centers approximated by high-density positive samples, resulting in more compact clusters. Specifically, our method constructs density-aware neighbor graphs using labeled and unlabeled data samples to estimate feature density and locate sparse regions. We also combine label-guided co-training with density-guided geometric regularization to form complementary supervision for unlabeled data. Experiments on the Multi-Organ Segmentation Challenge dataset demonstrate that our proposed method outperforms state-of-the-art methods, highlighting its efficacy in medical image segmentation tasks.
OphCLIP: Hierarchical Retrieval-Augmented Learning for Ophthalmic Surgical Video-Language Pretraining
Nov 23, 2024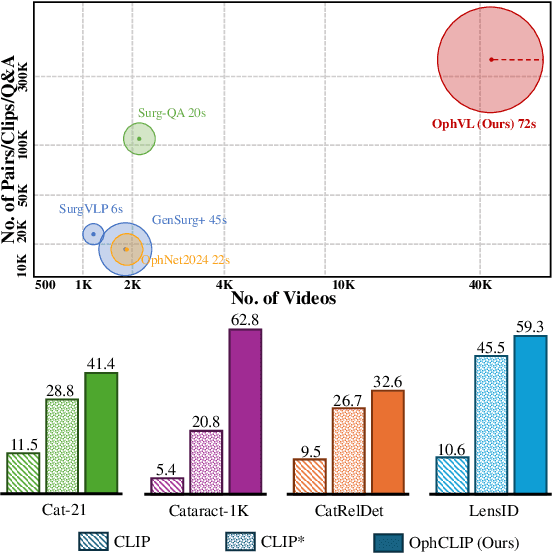
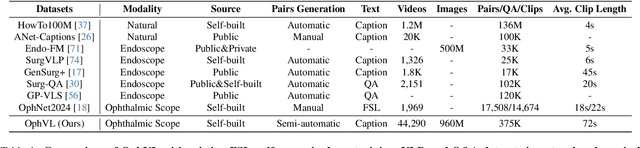
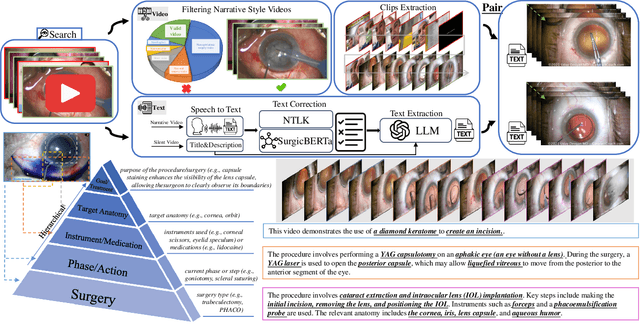
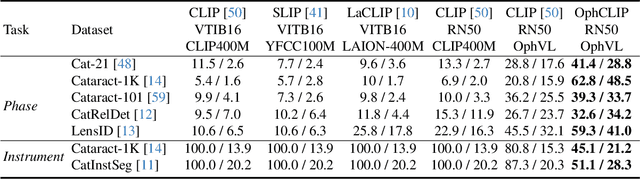
Surgical practice involves complex visual interpretation, procedural skills, and advanced medical knowledge, making surgical vision-language pretraining (VLP) particularly challenging due to this complexity and the limited availability of annotated data. To address the gap, we propose OphCLIP, a hierarchical retrieval-augmented vision-language pretraining framework specifically designed for ophthalmic surgical workflow understanding. OphCLIP leverages the OphVL dataset we constructed, a large-scale and comprehensive collection of over 375K hierarchically structured video-text pairs with tens of thousands of different combinations of attributes (surgeries, phases/operations/actions, instruments, medications, as well as more advanced aspects like the causes of eye diseases, surgical objectives, and postoperative recovery recommendations, etc). These hierarchical video-text correspondences enable OphCLIP to learn both fine-grained and long-term visual representations by aligning short video clips with detailed narrative descriptions and full videos with structured titles, capturing intricate surgical details and high-level procedural insights, respectively. Our OphCLIP also designs a retrieval-augmented pretraining framework to leverage the underexplored large-scale silent surgical procedure videos, automatically retrieving semantically relevant content to enhance the representation learning of narrative videos. Evaluation across 11 datasets for phase recognition and multi-instrument identification shows OphCLIP's robust generalization and superior performance.
OphNet: A Large-Scale Video Benchmark for Ophthalmic Surgical Workflow Understanding
Jun 12, 2024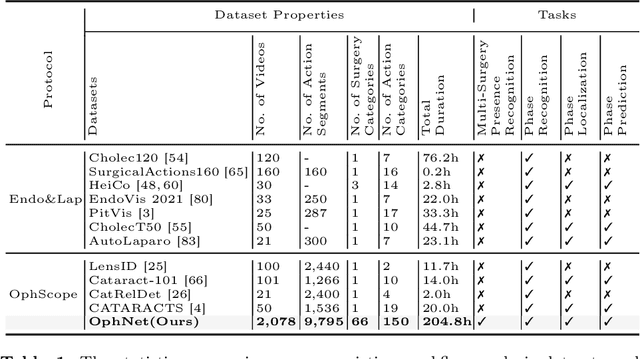
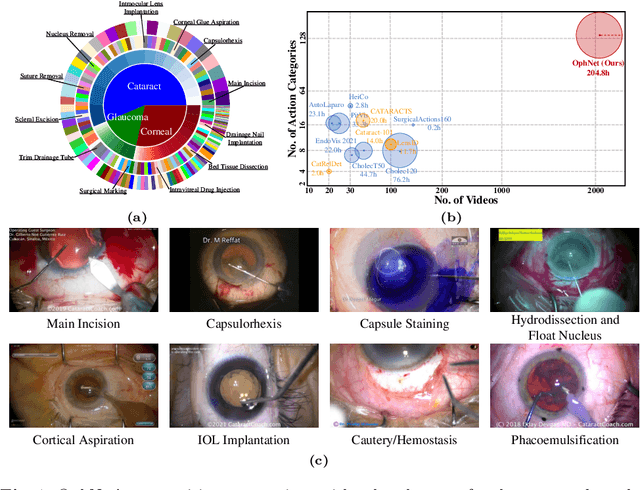

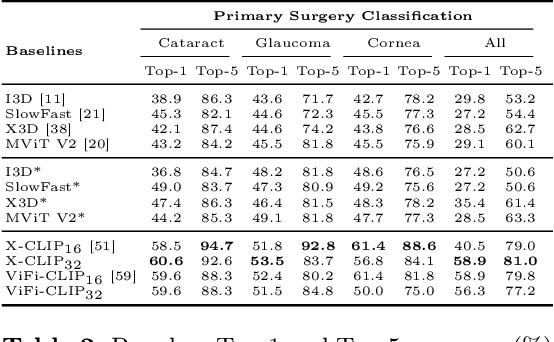
Surgical scene perception via videos are critical for advancing robotic surgery, telesurgery, and AI-assisted surgery, particularly in ophthalmology. However, the scarcity of diverse and richly annotated video datasets has hindered the development of intelligent systems for surgical workflow analysis. Existing datasets for surgical workflow analysis, which typically face challenges such as small scale, a lack of diversity in surgery and phase categories, and the absence of time-localized annotations, limit the requirements for action understanding and model generalization validation in complex and diverse real-world surgical scenarios. To address this gap, we introduce OphNet, a large-scale, expert-annotated video benchmark for ophthalmic surgical workflow understanding. OphNet features: 1) A diverse collection of 2,278 surgical videos spanning 66 types of cataract, glaucoma, and corneal surgeries, with detailed annotations for 102 unique surgical phases and 150 granular operations; 2) It offers sequential and hierarchical annotations for each surgery, phase, and operation, enabling comprehensive understanding and improved interpretability; 3) Moreover, OphNet provides time-localized annotations, facilitating temporal localization and prediction tasks within surgical workflows. With approximately 205 hours of surgical videos, OphNet is about 20 times larger than the largest existing surgical workflow analysis benchmark. Our dataset and code have been made available at: \url{https://github.com/minghu0830/OphNet-benchmark}.