 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Guided Sampling for Domain Adaptation of Text Retrievers
Jan 29, 2026General-purpose open-domain dense retrieval systems are usually trained with a large, eclectic mix of corpora and search tasks. How should these diverse corpora and tasks be sampled for training? Conventional approaches sample them uniformly, proportional to their instance population sizes, or depend on human-level expert supervision. It is well known that the training data sampling strategy can greatly impact model performance. However, how to find the optimal strategy has not been adequately studied in the context of embedding models. We propose Inf-DDS, a novel reinforcement learning driven sampling framework that adaptively reweighs training datasets guided by influence-based reward signals and is much more lightweight with respect to GPU consumption. Our technique iteratively refines the sampling policy, prioritizing datasets that maximize model performance on a target development set. We evaluate the efficacy of our sampling strategy on a wide range of text retrieval tasks, demonstrating strong improvements in retrieval performance and better adaptation compared to existing gradient-based sampling methods, while also being 1.5x to 4x cheaper in GPU compute. Our sampling strategy achieves a 5.03 absolute NDCG@10 improvement while training a multilingual bge-m3 model and an absolute NDCG@10 improvement of 0.94 while training all-MiniLM-L6-v2, even when starting from expert-assigned weights on a large pool of training datasets.
LMK > CLS: Landmark Pooling for Dense Embeddings
Jan 29, 2026Representation learning is central to many downstream tasks such as search, clustering, classification, and reranking. State-of-the-art sequence encoders typically collapse a variable-length token sequence to a single vector using a pooling operator, most commonly a special [CLS] token or mean pooling over token embeddings. In this paper, we identify systematic weaknesses of these pooling strategies: [CLS] tends to concentrate information toward the initial positions of the sequence and can under-represent distributed evidence, while mean pooling can dilute salient local signals, sometimes leading to worse short-context performance. To address these issues, we introduce Landmark (LMK) pooling, which partitions a sequence into chunks, inserts landmark tokens between chunks, and forms the final representation by mean-pooling the landmark token embeddings. This simple mechanism improves long-context extrapolation without sacrificing local salient features, at the cost of introducing a small number of special tokens. We empirically demonstrate that LMK pooling matches existing methods on short-context retrieval tasks and yields substantial improvements on long-context tasks, making it a practical and scalable alternative to existing pooling methods.
PRISM: A Personality-Driven Multi-Agent Framework for Social Media Simulation
Dec 22, 2025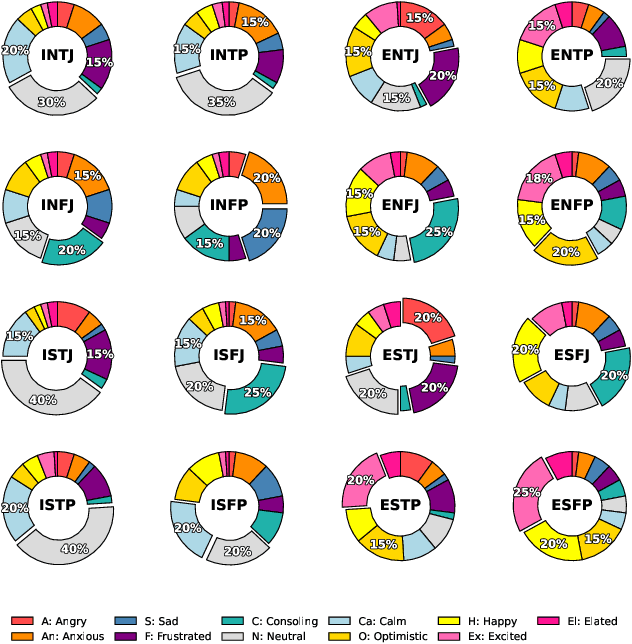
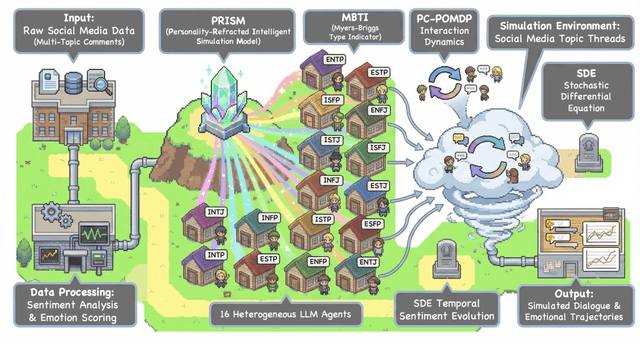
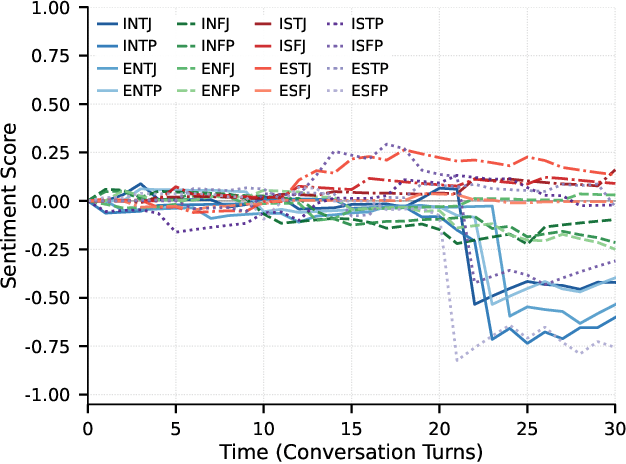

Traditional agent-based models (ABMs) of opinion dynamics often fail to capture the psychological heterogeneity driving online polarization due to simplistic homogeneity assumptions. This limitation obscures the critical interplay between individual cognitive biases and information propagation, thereby hindering a mechanistic understanding of how ideological divides are amplified. To address this challenge, we introduce the Personality-Refracted Intelligent Simulation Model (PRISM), a hybrid framework coupling stochastic differential equations (SDE) for continuous emotional evolution with a personality-conditional partially observable Markov decision process (PC-POMDP) for discrete decision-making. In contrast to continuous trait approaches, PRISM assigns distinct Myers-Briggs Type Indicator (MBTI) based cognitive policies to multimodal large language model (MLLM) agents, initialized via data-driven priors from large-scale social media datasets. PRISM achieves superior personality consistency aligned with human ground truth, significantly outperforming standard homogeneous and Big Five benchmarks. This framework effectively replicates emergent phenomena such as rational suppression and affective resonance, offering a robust tool for analyzing complex social media ecosystems.
Resource Efficient Sleep Staging via Multi-Level Masking and Prompt Learning
Nov 18, 2025Automatic sleep staging plays a vital role in assessing sleep quality and diagnosing sleep disorders. Most existing methods rely heavily on long and continuous EEG recordings, which poses significant challenges for data acquisition in resource-constrained systems, such as wearable or home-based monitoring systems. In this paper, we propose the task of resource-efficient sleep staging, which aims to reduce the amount of signal collected per sleep epoch while maintaining reliable classification performance. To solve this task, we adopt the masking and prompt learning strategy and propose a novel framework called Mask-Aware Sleep Staging (MASS). Specifically, we design a multi-level masking strategy to promote effective feature modeling under partial and irregular observations. To mitigate the loss of contextual information introduced by masking, we further propose a hierarchical prompt learning mechanism that aggregates unmasked data into a global prompt, serving as a semantic anchor for guiding both patch-level and epoch-level feature modeling. MASS is evaluated on four datasets, demonstrating state-of-the-art performance, especially when the amount of data is very limited. This result highlights its potential for efficient and scalable deployment in real-world low-resource sleep monitoring environments.
Phenome-Wide Multi-Omics Integration Uncovers Distinct Archetypes of Human Aging
Oct 14, 2025Aging is a highly complex and heterogeneous process that progresses at different rates across individuals, making biological age (BA) a more accurate indicator of physiological decline than chronological age. While previous studies have built aging clocks using single-omics data, they often fail to capture the full molecular complexity of human aging. In this work, we leveraged the Human Phenotype Project, a large-scale cohort of 12,000 adults aged 30--70 years, with extensive longitudinal profiling that includes clinical, behavioral, environmental, and multi-omics datasets -- spanning transcriptomics, lipidomics, metabolomics, and the microbiome. By employing advanced machine learning frameworks capable of modeling nonlinear biological dynamics, we developed and rigorously validated a multi-omics aging clock that robustly predicts diverse health outcomes and future disease risk. Unsupervised clustering of the integrated molecular profiles from multi-omics uncovered distinct biological subtypes of aging, revealing striking heterogeneity in aging trajectories and pinpointing pathway-specific alterations associated with different aging patterns. These findings demonstrate the power of multi-omics integration to decode the molecular landscape of aging and lay the groundwork for personalized healthspan monitoring and precision strategies to prevent age-related diseases.
Contrastive Retrieval Heads Improve Attention-Based Re-Ranking
Oct 02, 2025The strong zero-shot and long-context capabilities of recent Large Language Models (LLMs) have paved the way for highly effective re-ranking systems. Attention-based re-rankers leverage attention weights from transformer heads to produce relevance scores, but not all heads are created equally: many contribute noise and redundancy, thus limiting performance. To address this, we introduce CoRe heads, a small set of retrieval heads identified via a contrastive scoring metric that explicitly rewards high attention heads that correlate with relevant documents, while downplaying nodes with higher attention that correlate with irrelevant documents. This relative ranking criterion isolates the most discriminative heads for re-ranking and yields a state-of-the-art list-wise re-ranker. Extensive experiments with three LLMs show that aggregated signals from CoRe heads, constituting less than 1% of all heads, substantially improve re-ranking accuracy over strong baselines. We further find that CoRe heads are concentrated in middle layers, and pruning the computation of final 50% of model layers preserves accuracy while significantly reducing inference time and memory usage.
Towards Robust Visual Continual Learning with Multi-Prototype Supervision
Sep 19, 2025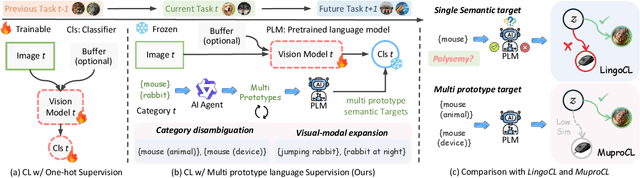
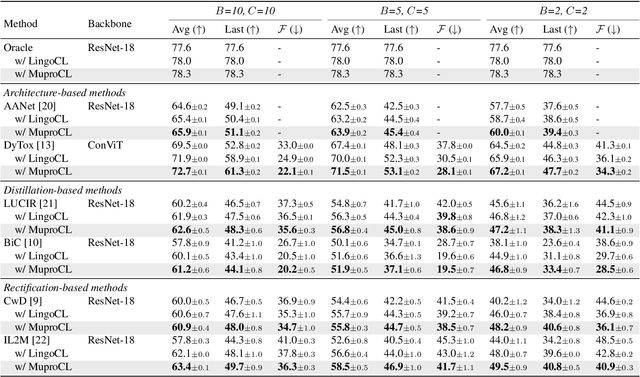
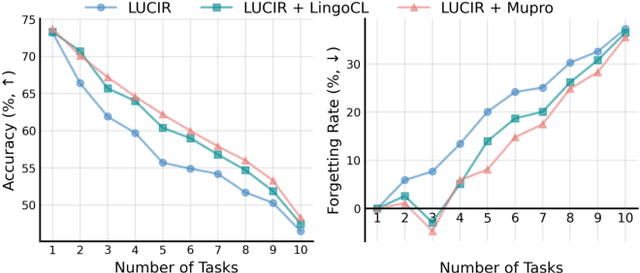
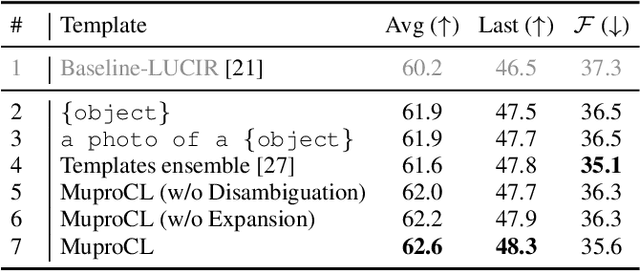
Language-guided supervision, which utilizes a frozen semantic target from a Pretrained Language Model (PLM), has emerged as a promising paradigm for visual Continual Learning (CL). However, relying on a single target introduces two critical limitations: 1) semantic ambiguity, where a polysemous category name results in conflicting visual representations, and 2) intra-class visual diversity, where a single prototype fails to capture the rich variety of visual appearances within a class. To this end, we propose MuproCL, a novel framework that replaces the single target with multiple, context-aware prototypes. Specifically, we employ a lightweight LLM agent to perform category disambiguation and visual-modal expansion to generate a robust set of semantic prototypes. A LogSumExp aggregation mechanism allows the vision model to adaptively align with the most relevant prototype for a given image. Extensive experiments across various CL baselines demonstrate that MuproCL consistently enhances performance and robustness, establishing a more effective path for language-guided continual learning.
Deep Reactive Policy: Learning Reactive Manipulator Motion Planning for Dynamic Environments
Sep 08, 2025Generating collision-free motion in dynamic, partially observable environments is a fundamental challenge for robotic manipulators. Classical motion planners can compute globally optimal trajectories but require full environment knowledge and are typically too slow for dynamic scenes. Neural motion policies offer a promising alternative by operating in closed-loop directly on raw sensory inputs but often struggle to generalize in complex or dynamic settings. We propose Deep Reactive Policy (DRP), a visuo-motor neural motion policy designed for reactive motion generation in diverse dynamic environments, operating directly on point cloud sensory input. At its core is IMPACT, a transformer-based neural motion policy pretrained on 10 million generated expert trajectories across diverse simulation scenarios. We further improve IMPACT's static obstacle avoidance through iterative student-teacher finetuning. We additionally enhance the policy's dynamic obstacle avoidance at inference time using DCP-RMP, a locally reactive goal-proposal module. We evaluate DRP on challenging tasks featuring cluttered scenes, dynamic moving obstacles, and goal obstructions. DRP achieves strong generalization, outperforming prior classical and neural methods in success rate across both simulated and real-world settings. Video results and code available at https://deep-reactive-policy.com
How Effectively Can Large Language Models Connect SNP Variants and ECG Phenotypes for Cardiovascular Risk Prediction?
Aug 10, 2025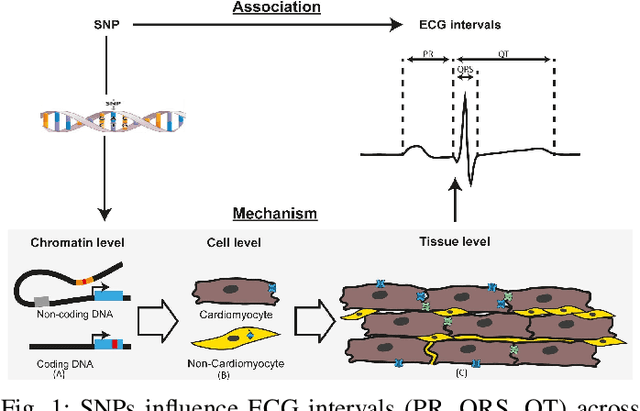
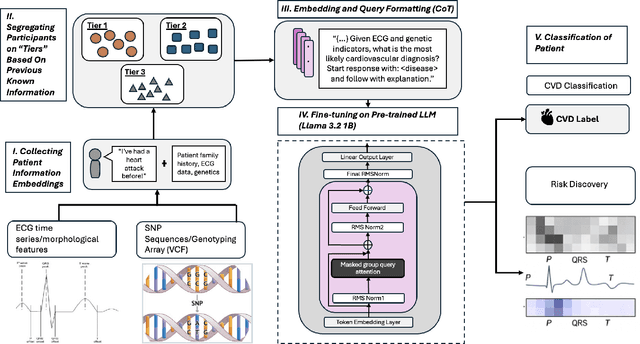
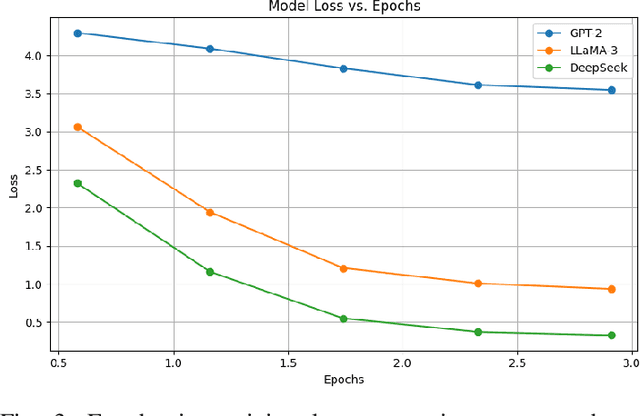
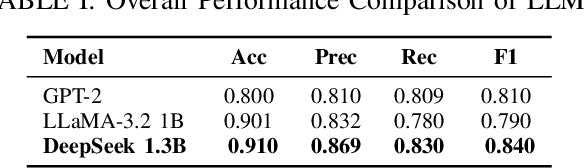
Cardiovascular disease (CVD) prediction remains a tremendous challenge due to its multifactorial etiology and global burden of morbidity and mortality. Despite the growing availability of genomic and electrophysiological data, extracting biologically meaningful insights from such high-dimensional, noisy, and sparsely annotated datasets remains a non-trivial task. Recently, LLMs has been applied effectively to predict structural variations in biological sequences. In this work, we explore the potential of fine-tuned LLMs to predict cardiac diseases and SNPs potentially leading to CVD risk using genetic markers derived from high-throughput genomic profiling. We investigate the effect of genetic patterns associated with cardiac conditions and evaluate how LLMs can learn latent biological relationships from structured and semi-structured genomic data obtained by mapping genetic aspects that are inherited from the family tree. By framing the problem as a Chain of Thought (CoT) reasoning task, the models are prompted to generate disease labels and articulate informed clinical deductions across diverse patient profiles and phenotypes. The findings highlight the promise of LLMs in contributing to early detection, risk assessment, and ultimately, the advancement of personalized medicine in cardiac care.
SAM-aware Test-time Adaptation for Universal Medical Image Segmentation
Jun 05, 2025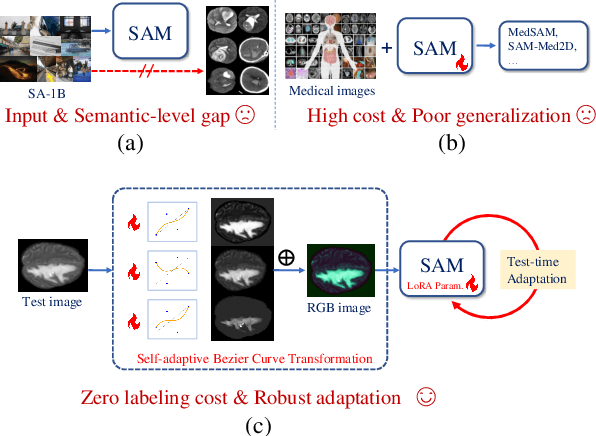
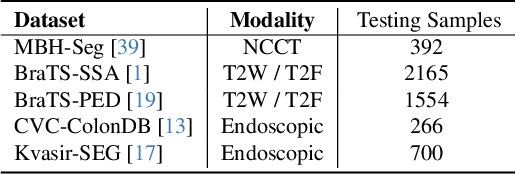
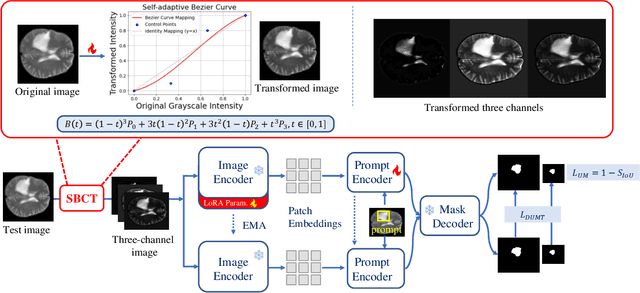
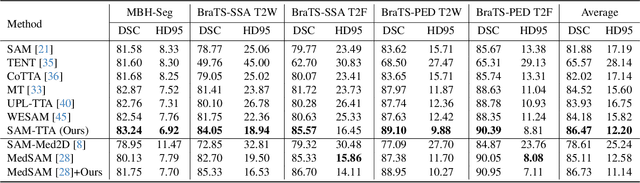
Universal medical image segmentation using the Segment Anything Model (SAM) remains challenging due to its limited adaptability to medical domains. Existing adaptations, such as MedSAM, enhance SAM's performance in medical imaging but at the cost of reduced generalization to unseen data. Therefore, in this paper, we propose SAM-aware Test-Time Adaptation (SAM-TTA), a fundamentally different pipeline that preserves the generalization of SAM while improving its segmentation performance in medical imaging via a test-time framework. SAM-TTA tackles two key challenges: (1) input-level discrepancies caused by differences in image acquisition between natural and medical images and (2) semantic-level discrepancies due to fundamental differences in object definition between natural and medical domains (e.g., clear boundaries vs. ambiguous structures). Specifically, our SAM-TTA framework comprises (1) Self-adaptive Bezier Curve-based Transformation (SBCT), which adaptively converts single-channel medical images into three-channel SAM-compatible inputs while maintaining structural integrity, to mitigate the input gap between medical and natural images, and (2) Dual-scale Uncertainty-driven Mean Teacher adaptation (DUMT), which employs consistency learning to align SAM's internal representations to medical semantics, enabling efficient adaptation without auxiliary supervision or expensive retraining. Extensive experiments on five public datasets demonstrate that our SAM-TTA outperforms existing TTA approaches and even surpasses fully fine-tuned models such as MedSAM in certain scenarios, establishing a new paradigm for universal medical image segmentation. Code can be found at https://github.com/JianghaoWu/SAM-TTA.