 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Multilingual R2 Models
May 13, 2026We introduce the multilingual Granite Embedding R2 models, a family of encoder-based embedding models for enterprise-scale dense retrieval across 200+ languages. Extending our English-focused R2 release, these models add enhanced support for 52 languages and programming code, a 32,768-token context window (a 64x expansion over R1), and state-of-the-art overall performance across multilingual and cross-lingual text search, code retrieval, long-document search, and reasoning retrieval datasets. The release consists of two bi-encoder models based on the ModernBERT architecture with an expanded multilingual vocabulary: a 311M-parameter full-size, and a 97M-parameter compact model built via model pruning and vocabulary selection that achieves the highest retrieval score of any open multilingual embedding model under 100M parameters. The full-size also supports Matryoshka Representation Learning for flexible embedding dimensionality. Both models are trained on enterprise-appropriate data with governance oversight, and released under the Apache 2.0 license at https://huggingface.co/collections/ibm-granite, designed to support responsible use and enable unrestricted research and enterprise adoption.
LMK > CLS: Landmark Pooling for Dense Embeddings
Jan 29, 2026Representation learning is central to many downstream tasks such as search, clustering, classification, and reranking. State-of-the-art sequence encoders typically collapse a variable-length token sequence to a single vector using a pooling operator, most commonly a special [CLS] token or mean pooling over token embeddings. In this paper, we identify systematic weaknesses of these pooling strategies: [CLS] tends to concentrate information toward the initial positions of the sequence and can under-represent distributed evidence, while mean pooling can dilute salient local signals, sometimes leading to worse short-context performance. To address these issues, we introduce Landmark (LMK) pooling, which partitions a sequence into chunks, inserts landmark tokens between chunks, and forms the final representation by mean-pooling the landmark token embeddings. This simple mechanism improves long-context extrapolation without sacrificing local salient features, at the cost of introducing a small number of special tokens. We empirically demonstrate that LMK pooling matches existing methods on short-context retrieval tasks and yields substantial improvements on long-context tasks, making it a practical and scalable alternative to existing pooling methods.
Granite Embedding Models
Feb 27, 2025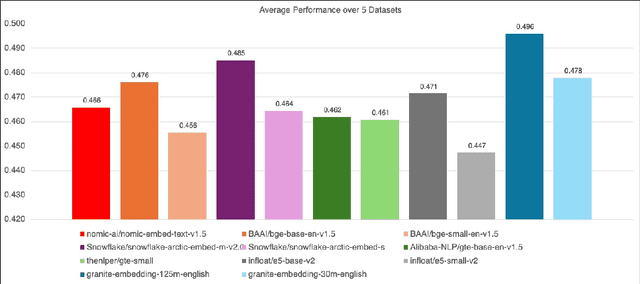



We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
An Empirical Investigation into the Effect of Parameter Choices in Knowledge Distillation
Jan 12, 2024



We present a large-scale empirical study of how choices of configuration parameters affect performance in knowledge distillation (KD). An example of such a KD parameter is the measure of distance between the predictions of the teacher and the student, common choices for which include the mean squared error (MSE) and the KL-divergence. Although scattered efforts have been made to understand the differences between such options, the KD literature still lacks a systematic study on their general effect on student performance. We take an empirical approach to this question in this paper, seeking to find out the extent to which such choices influence student performance across 13 datasets from 4 NLP tasks and 3 student sizes. We quantify the cost of making sub-optimal choices and identify a single configuration that performs well across the board.
Cross-Lingual Relation Extraction with Transformers
Oct 16, 2020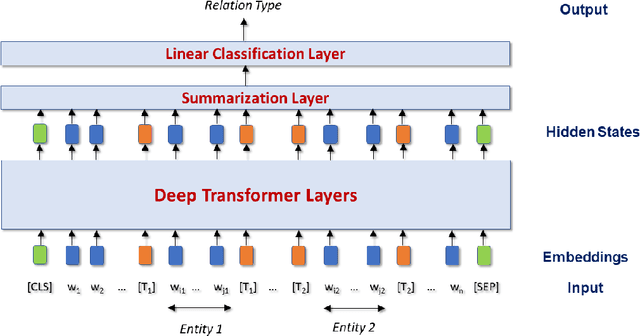
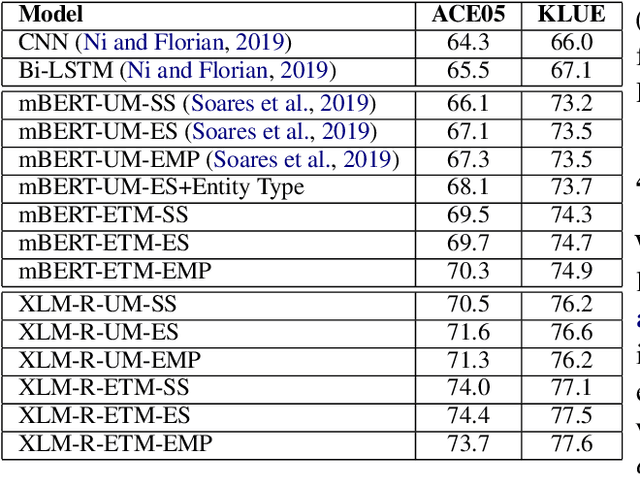
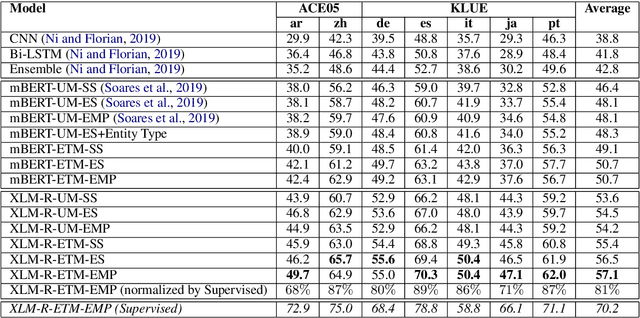
Relation extraction (RE) is one of the most important tasks in information extraction, as it provides essential information for many NLP applications. In this paper, we propose a cross-lingual RE approach that does not require any human annotation in a target language or any cross-lingual resources. Building upon unsupervised cross-lingual representation learning frameworks, we develop several deep Transformer based RE models with a novel encoding scheme that can effectively encode both entity location and entity type information. Our RE models, when trained with English data, outperform several deep neural network based English RE models. More importantly, our models can be applied to perform zero-shot cross-lingual RE, achieving the state-of-the-art cross-lingual RE performance on two datasets (68-89% of the accuracy of the supervised target-language RE model). The high cross-lingual transfer efficiency without requiring additional training data or cross-lingual resources shows that our RE models are especially useful for low-resource languages.
Cascaded Models for Better Fine-Grained Named Entity Recognition
Sep 15, 2020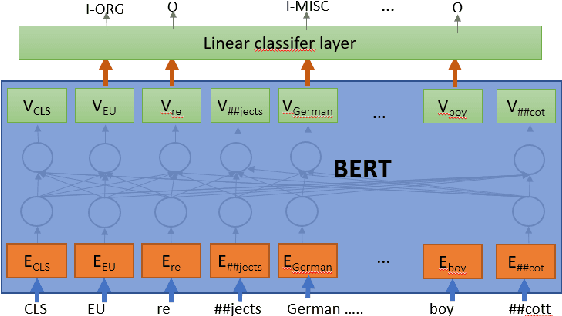
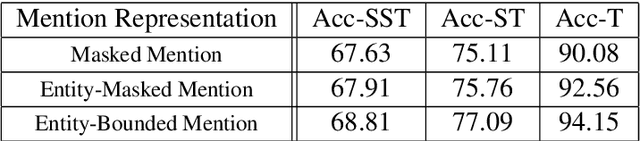
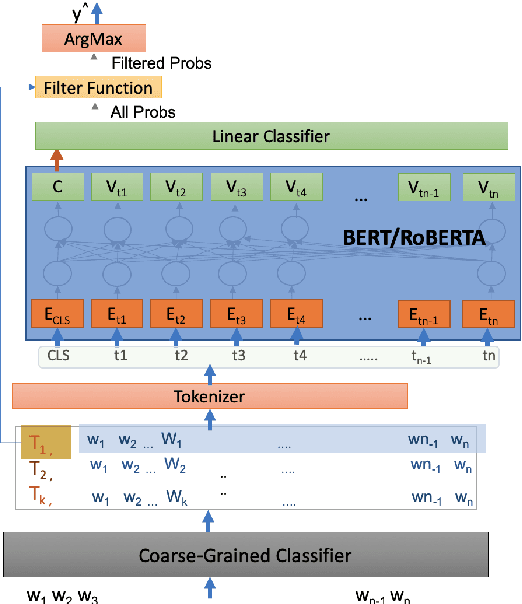
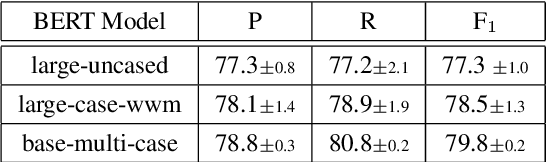
Named Entity Recognition (NER) is an essential precursor task for many natural language applications, such as relation extraction or event extraction. Much of the NER research has been done on datasets with few classes of entity types (e.g. PER, LOC, ORG, MISC), but many real world applications (disaster relief, complex event extraction, law enforcement) can benefit from a larger NER typeset. More recently, datasets were created that have hundreds to thousands of types of entities, sparking new lines of research (Sekine, 2008;Ling and Weld, 2012; Gillick et al., 2014; Choiet al., 2018). In this paper we present a cascaded approach to labeling fine-grained NER, applying to a newly released fine-grained NER dataset that was used in the TAC KBP 2019 evaluation (Ji et al., 2019), inspired by the fact that training data is available for some of the coarse labels. Using a combination of transformer networks, we show that performance can be improved by about 20 F1 absolute, as compared with the straightforward model built on the full fine-grained types, and show that, surprisingly, using course-labeled data in three languages leads to an improvement in the English data.
Event Presence Prediction Helps Trigger Detection Across Languages
Sep 15, 2020
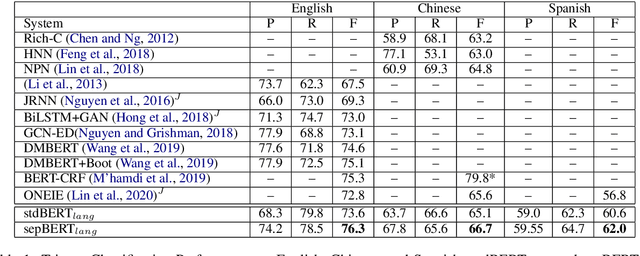
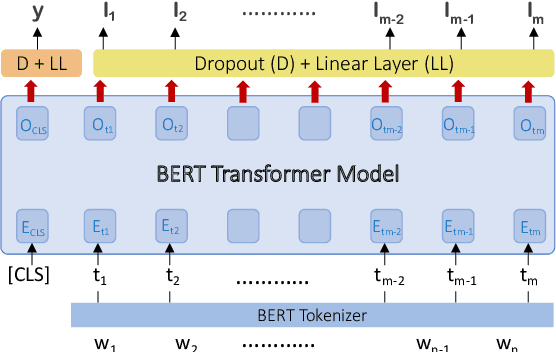
The task of event detection and classification is central to most information retrieval applications. We show that a Transformer based architecture can effectively model event extraction as a sequence labeling task. We propose a combination of sentence level and token level training objectives that significantly boosts the performance of a BERT based event extraction model. Our approach achieves a new state-of-the-art performance on ACE 2005 data for English and Chinese. We also test our model on ERE Spanish, achieving an average gain of 2 absolute F1 points over prior best performing model.
Towards Lingua Franca Named Entity Recognition with BERT
Dec 12, 2019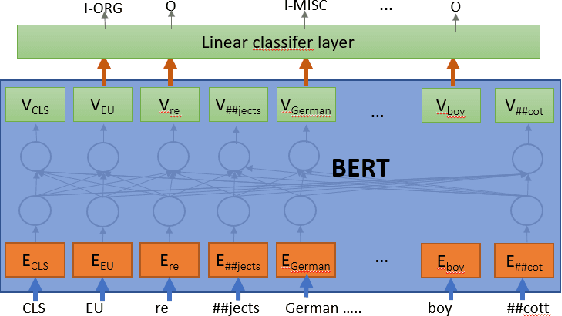
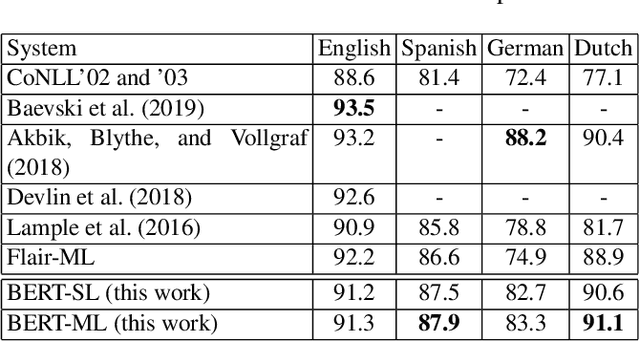
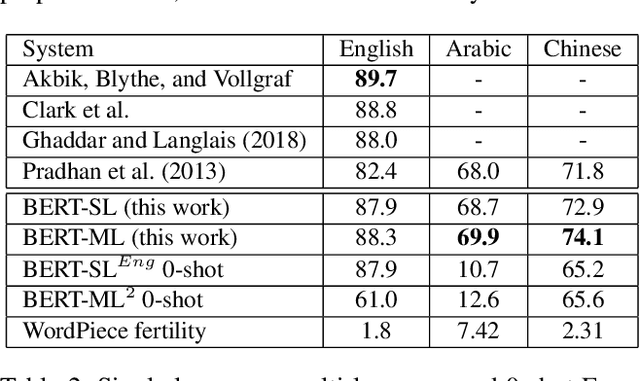
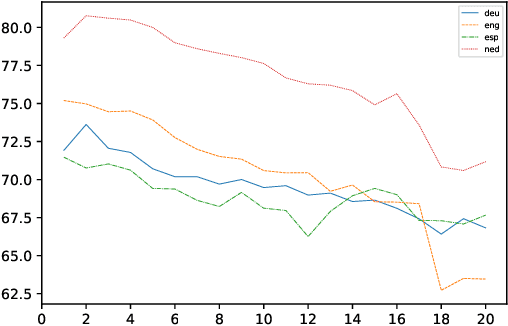
Information extraction is an important task in NLP, enabling the automatic extraction of data for relational database filling. Historically, research and data was produced for English text, followed in subsequent years by datasets in Arabic, Chinese (ACE/OntoNotes), Dutch, Spanish, German (CoNLL evaluations), and many others. The natural tendency has been to treat each language as a different dataset and build optimized models for each. In this paper we investigate a single Named Entity Recognition model, based on a multilingual BERT, that is trained jointly on many languages simultaneously, and is able to decode these languages with better accuracy than models trained only on one language. To improve the initial model, we study the use of regularization strategies such as multitask learning and partial gradient updates. In addition to being a single model that can tackle multiple languages (including code switch), the model could be used to make zero-shot predictions on a new language, even ones for which training data is not available, out of the box. The results show that this model not only performs competitively with monolingual models, but it also achieves state-of-the-art results on the CoNLL02 Dutch and Spanish datasets, OntoNotes Arabic and Chinese datasets. Moreover, it performs reasonably well on unseen languages, achieving state-of-the-art for zero-shot on three CoNLL languages.