Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Presence Prediction Helps Trigger Detection Across Languages
Paper and Code
Sep 15, 2020
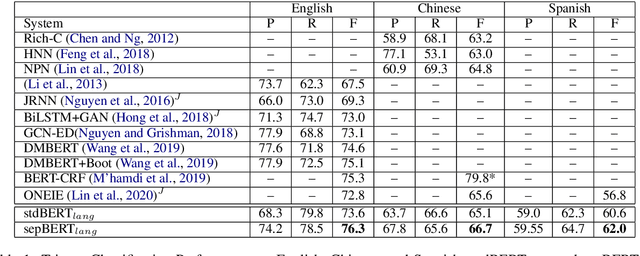
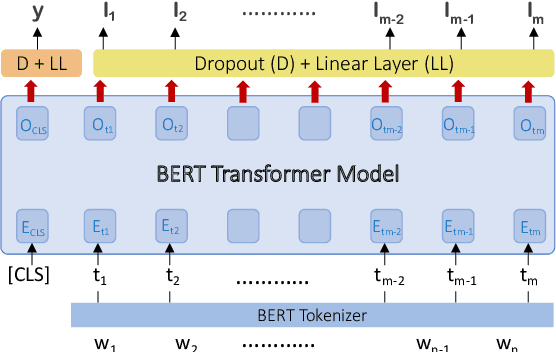
The task of event detection and classification is central to most information retrieval applications. We show that a Transformer based architecture can effectively model event extraction as a sequence labeling task. We propose a combination of sentence level and token level training objectives that significantly boosts the performance of a BERT based event extraction model. Our approach achieves a new state-of-the-art performance on ACE 2005 data for English and Chinese. We also test our model on ERE Spanish, achieving an average gain of 2 absolute F1 points over prior best performing model.
View paper on