 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentSeeker: A Comprehensive Benchmark and A Strong Baseline For Moment Retrieval Within Long Videos
Feb 18, 2025Retrieval augmented generation (RAG) holds great promise in addressing challenges associated with long video understanding. These methods retrieve useful moments from long videos for their presented tasks, thereby enabling multimodal large language models (MLLMs) to generate high-quality answers in a cost-effective way. In this work, we present MomentSeeker, a comprehensive benchmark to evaluate retrieval models' performance in handling general long-video moment retrieval (LVMR) tasks. MomentSeeker offers three key advantages. First, it incorporates long videos of over 500 seconds on average, making it the first benchmark specialized for long-video moment retrieval. Second, it covers a wide range of task categories (including Moment Search, Caption Alignment, Image-conditioned Moment Search, and Video-conditioned Moment Search) and diverse application scenarios (e.g., sports, movies, cartoons, and ego), making it a comprehensive tool for assessing retrieval models' general LVMR performance. Additionally, the evaluation tasks are carefully curated through human annotation, ensuring the reliability of assessment. We further fine-tune an MLLM-based LVMR retriever on synthetic data, which demonstrates strong performance on our benchmark. We perform extensive experiments with various popular multimodal retrievers based on our benchmark, whose results highlight the challenges of LVMR and limitations for existing methods. Our created resources will be shared with community to advance future research in this field.
Practical token pruning for foundation models in few-shot conversational virtual assistant systems
Aug 21, 2024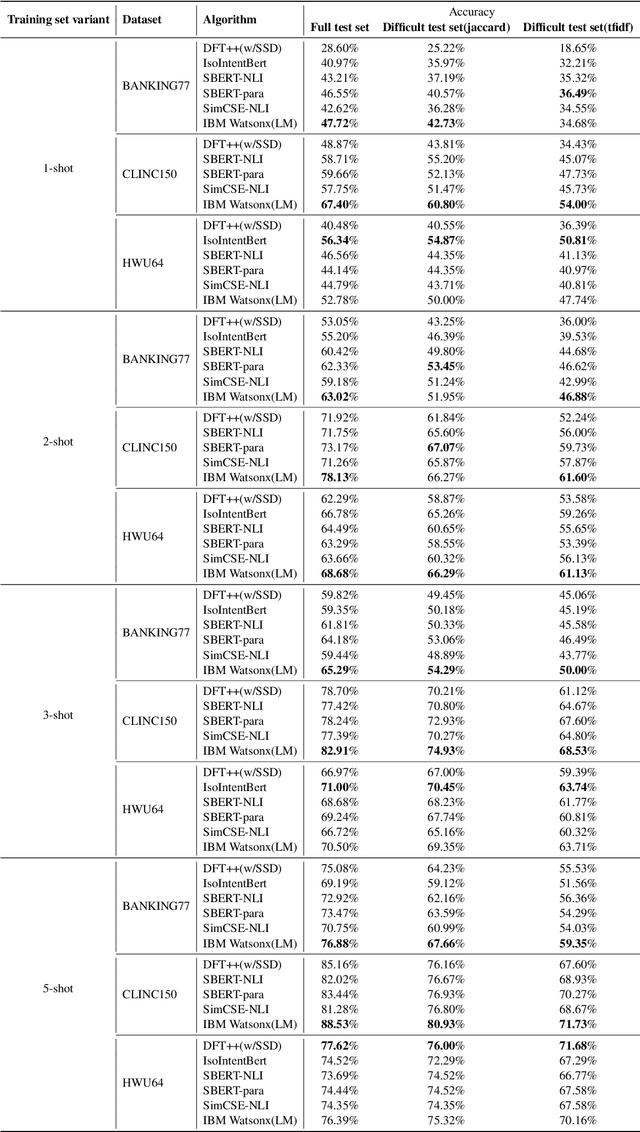
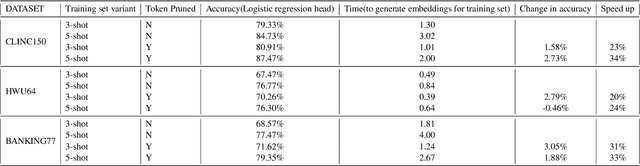
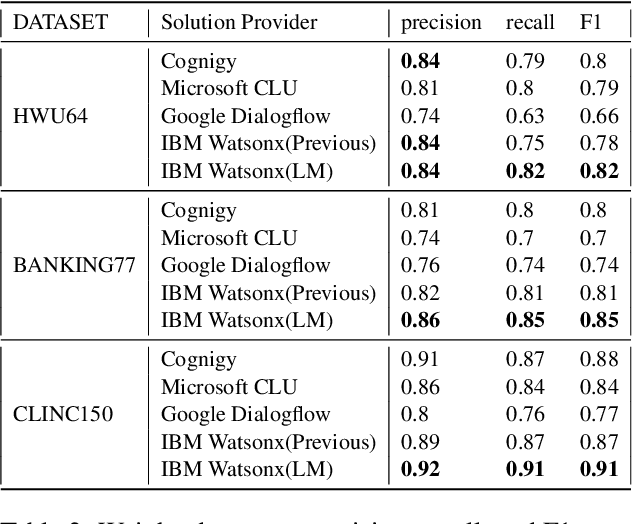
In an enterprise Virtual Assistant (VA) system, intent classification is the crucial component that determines how a user input is handled based on what the user wants. The VA system is expected to be a cost-efficient SaaS service with low training and inference time while achieving high accuracy even with a small number of training samples. We pretrain a transformer-based sentence embedding model with a contrastive learning objective and leverage the embedding of the model as features when training intent classification models. Our approach achieves the state-of-the-art results for few-shot scenarios and performs better than other commercial solutions on popular intent classification benchmarks. However, generating features via a transformer-based model increases the inference time, especially for longer user inputs, due to the quadratic runtime of the transformer's attention mechanism. On top of model distillation, we introduce a practical multi-task adaptation approach that configures dynamic token pruning without the need for task-specific training for intent classification. We demonstrate that this approach improves the inference speed of popular sentence transformer models without affecting model performance.
Distilling Event Sequence Knowledge From Large Language Models
Jan 14, 2024



Event sequence models have been found to be highly effective in the analysis and prediction of events. Building such models requires availability of abundant high-quality event sequence data. In certain applications, however, clean structured event sequences are not available, and automated sequence extraction results in data that is too noisy and incomplete. In this work, we explore the use of Large Language Models (LLMs) to generate event sequences that can effectively be used for probabilistic event model construction. This can be viewed as a mechanism of distilling event sequence knowledge from LLMs. Our approach relies on a Knowledge Graph (KG) of event concepts with partial causal relations to guide the generative language model for causal event sequence generation. We show that our approach can generate high-quality event sequences, filling a knowledge gap in the input KG. Furthermore, we explore how the generated sequences can be leveraged to discover useful and more complex structured knowledge from pattern mining and probabilistic event models. We release our sequence generation code and evaluation framework, as well as corpus of event sequence data.
Improving Neural Ranking Models with Traditional IR Methods
Aug 29, 2023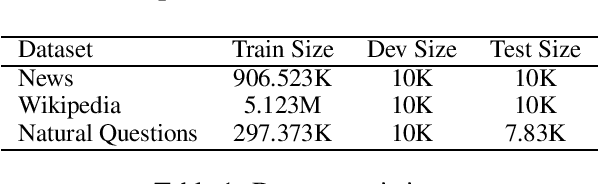
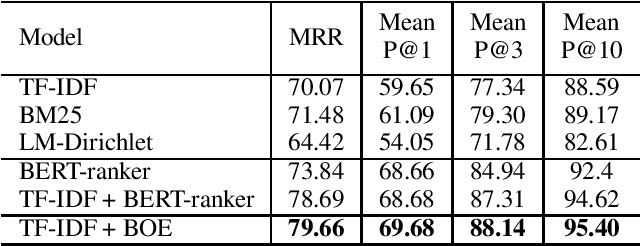


Neural ranking methods based on large transformer models have recently gained significant attention in the information retrieval community, and have been adopted by major commercial solutions. Nevertheless, they are computationally expensive to create, and require a great deal of labeled data for specialized corpora. In this paper, we explore a low resource alternative which is a bag-of-embedding model for document retrieval and find that it is competitive with large transformer models fine tuned on information retrieval tasks. Our results show that a simple combination of TF-IDF, a traditional keyword matching method, with a shallow embedding model provides a low cost path to compete well with the performance of complex neural ranking models on 3 datasets. Furthermore, adding TF-IDF measures improves the performance of large-scale fine tuned models on these tasks.
A Cross-Domain Evaluation of Approaches for Causal Knowledge Extraction
Aug 07, 2023



Causal knowledge extraction is the task of extracting relevant causes and effects from text by detecting the causal relation. Although this task is important for language understanding and knowledge discovery, recent works in this domain have largely focused on binary classification of a text segment as causal or non-causal. In this regard, we perform a thorough analysis of three sequence tagging models for causal knowledge extraction and compare it with a span based approach to causality extraction. Our experiments show that embeddings from pre-trained language models (e.g. BERT) provide a significant performance boost on this task compared to previous state-of-the-art models with complex architectures. We observe that span based models perform better than simple sequence tagging models based on BERT across all 4 data sets from diverse domains with different types of cause-effect phrases.
A Generative Model for Relation Extraction and Classification
Feb 26, 2022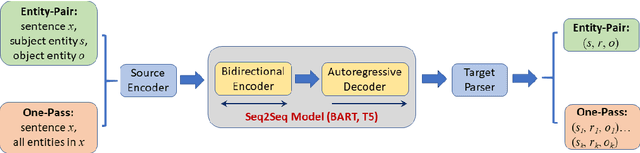
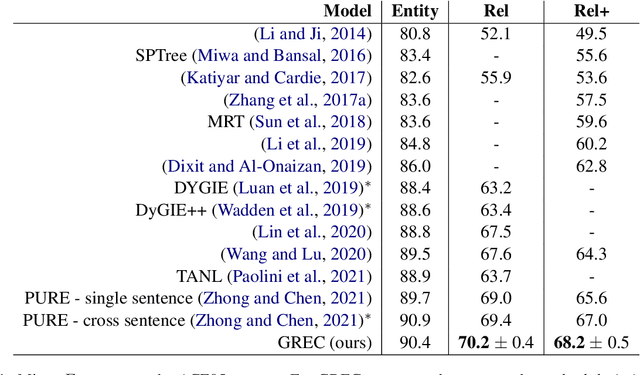
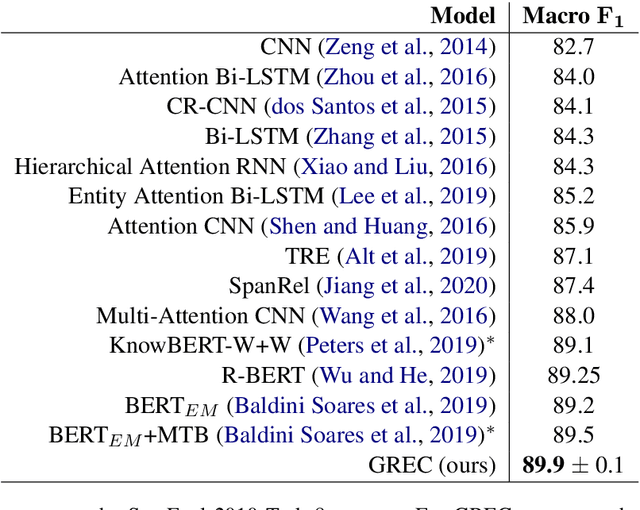
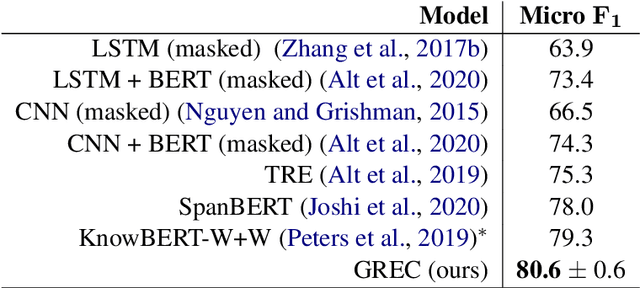
Relation extraction (RE) is an important information extraction task which provides essential information to many NLP applications such as knowledge base population and question answering. In this paper, we present a novel generative model for relation extraction and classification (which we call GREC), where RE is modeled as a sequence-to-sequence generation task. We explore various encoding representations for the source and target sequences, and design effective schemes that enable GREC to achieve state-of-the-art performance on three benchmark RE datasets. In addition, we introduce negative sampling and decoding scaling techniques which provide a flexible tool to tune the precision and recall performance of the model. Our approach can be extended to extract all relation triples from a sentence in one pass. Although the one-pass approach incurs certain performance loss, it is much more computationally efficient.
Cross-Lingual Relation Extraction with Transformers
Oct 16, 2020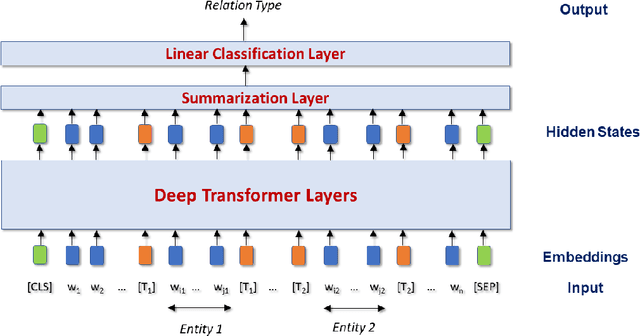
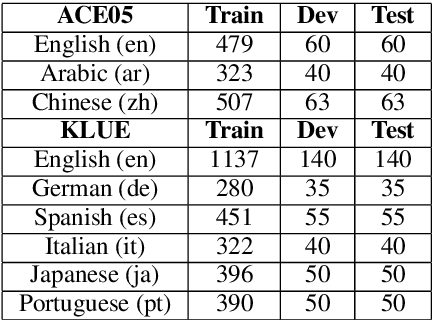
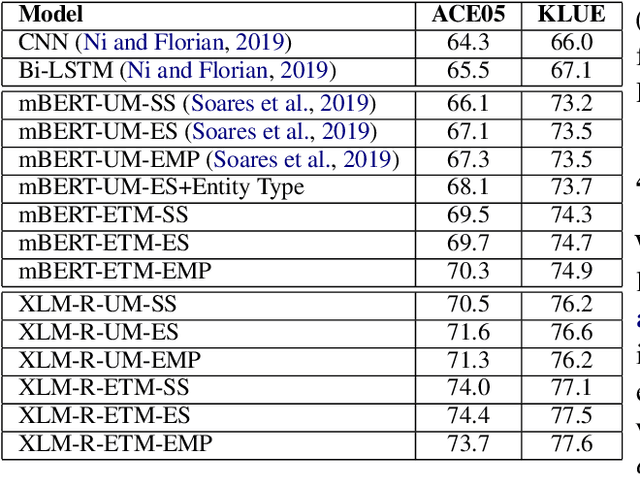
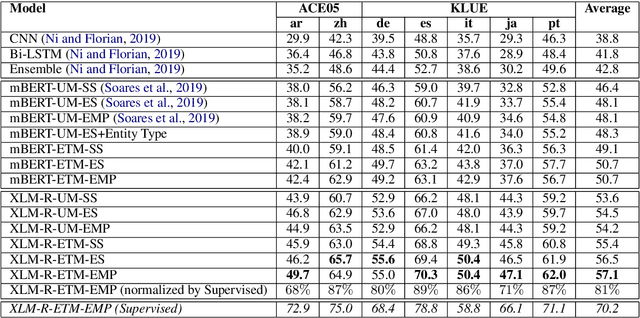
Relation extraction (RE) is one of the most important tasks in information extraction, as it provides essential information for many NLP applications. In this paper, we propose a cross-lingual RE approach that does not require any human annotation in a target language or any cross-lingual resources. Building upon unsupervised cross-lingual representation learning frameworks, we develop several deep Transformer based RE models with a novel encoding scheme that can effectively encode both entity location and entity type information. Our RE models, when trained with English data, outperform several deep neural network based English RE models. More importantly, our models can be applied to perform zero-shot cross-lingual RE, achieving the state-of-the-art cross-lingual RE performance on two datasets (68-89% of the accuracy of the supervised target-language RE model). The high cross-lingual transfer efficiency without requiring additional training data or cross-lingual resources shows that our RE models are especially useful for low-resource languages.
Cascaded Models for Better Fine-Grained Named Entity Recognition
Sep 15, 2020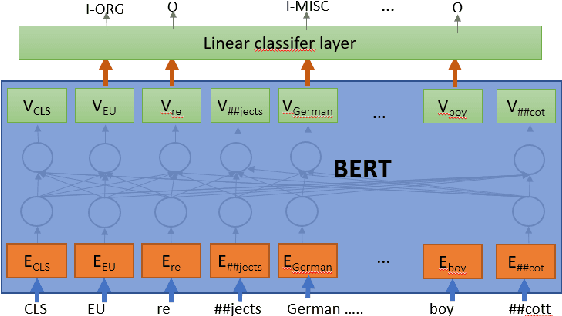
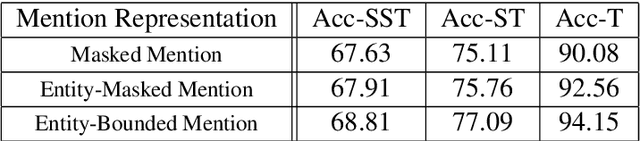
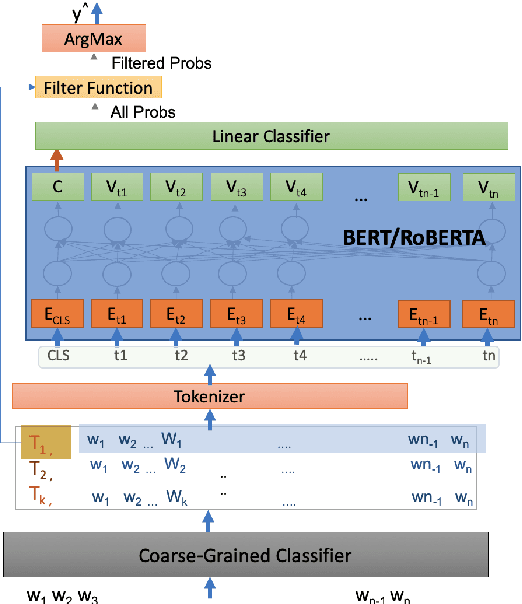
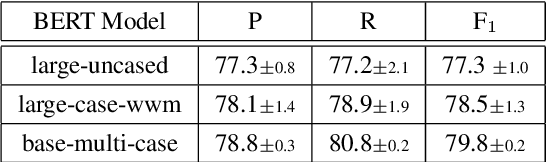
Named Entity Recognition (NER) is an essential precursor task for many natural language applications, such as relation extraction or event extraction. Much of the NER research has been done on datasets with few classes of entity types (e.g. PER, LOC, ORG, MISC), but many real world applications (disaster relief, complex event extraction, law enforcement) can benefit from a larger NER typeset. More recently, datasets were created that have hundreds to thousands of types of entities, sparking new lines of research (Sekine, 2008;Ling and Weld, 2012; Gillick et al., 2014; Choiet al., 2018). In this paper we present a cascaded approach to labeling fine-grained NER, applying to a newly released fine-grained NER dataset that was used in the TAC KBP 2019 evaluation (Ji et al., 2019), inspired by the fact that training data is available for some of the coarse labels. Using a combination of transformer networks, we show that performance can be improved by about 20 F1 absolute, as compared with the straightforward model built on the full fine-grained types, and show that, surprisingly, using course-labeled data in three languages leads to an improvement in the English data.
Event Presence Prediction Helps Trigger Detection Across Languages
Sep 15, 2020
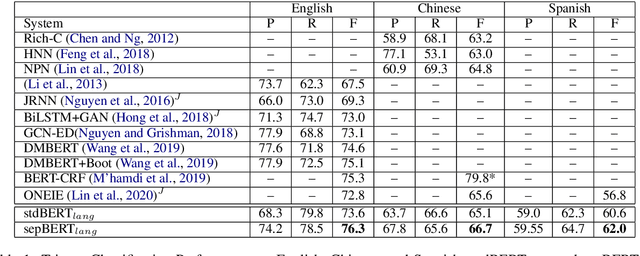
The task of event detection and classification is central to most information retrieval applications. We show that a Transformer based architecture can effectively model event extraction as a sequence labeling task. We propose a combination of sentence level and token level training objectives that significantly boosts the performance of a BERT based event extraction model. Our approach achieves a new state-of-the-art performance on ACE 2005 data for English and Chinese. We also test our model on ERE Spanish, achieving an average gain of 2 absolute F1 points over prior best performing model.
Towards Lingua Franca Named Entity Recognition with BERT
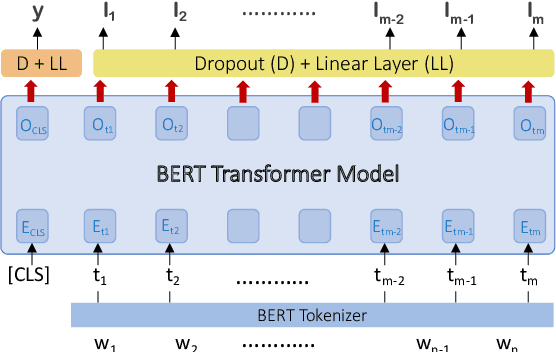
Dec 12, 2019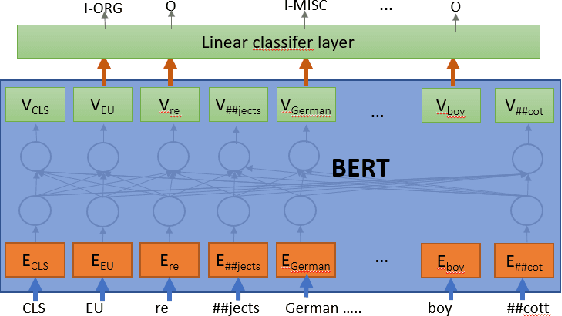
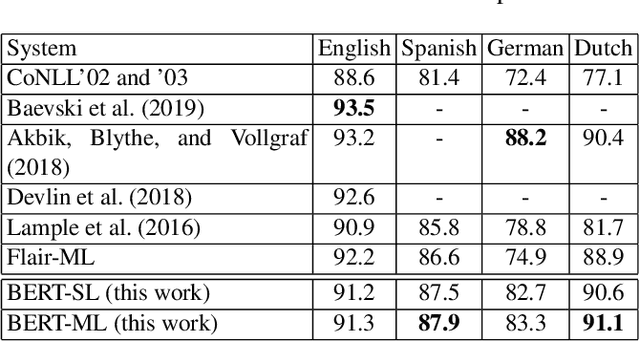
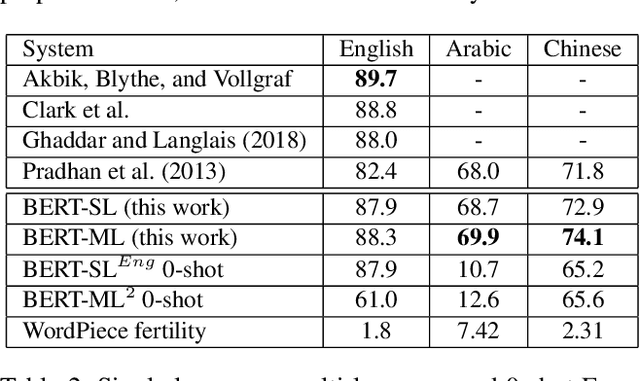
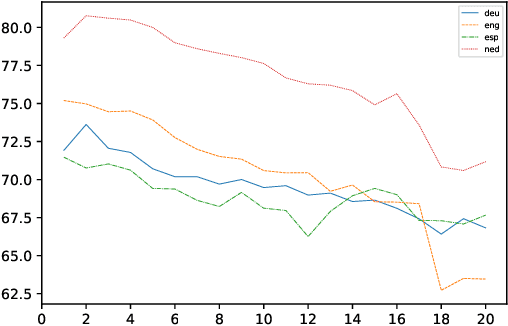
Information extraction is an important task in NLP, enabling the automatic extraction of data for relational database filling. Historically, research and data was produced for English text, followed in subsequent years by datasets in Arabic, Chinese (ACE/OntoNotes), Dutch, Spanish, German (CoNLL evaluations), and many others. The natural tendency has been to treat each language as a different dataset and build optimized models for each. In this paper we investigate a single Named Entity Recognition model, based on a multilingual BERT, that is trained jointly on many languages simultaneously, and is able to decode these languages with better accuracy than models trained only on one language. To improve the initial model, we study the use of regularization strategies such as multitask learning and partial gradient updates. In addition to being a single model that can tackle multiple languages (including code switch), the model could be used to make zero-shot predictions on a new language, even ones for which training data is not available, out of the box. The results show that this model not only performs competitively with monolingual models, but it also achieves state-of-the-art results on the CoNLL02 Dutch and Spanish datasets, OntoNotes Arabic and Chinese datasets. Moreover, it performs reasonably well on unseen languages, achieving state-of-the-art for zero-shot on three CoNLL languages.