 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-XL-2: Towards Very Long-Video Understanding Through Task-Aware KV Sparsification
Jun 24, 2025Multi-modal large language models (MLLMs) models have made significant progress in video understanding over the past few years. However, processing long video inputs remains a major challenge due to high memory and computational costs. This makes it difficult for current models to achieve both strong performance and high efficiency in long video understanding. To address this challenge, we propose Video-XL-2, a novel MLLM that delivers superior cost-effectiveness for long-video understanding based on task-aware KV sparsification. The proposed framework operates with two key steps: chunk-based pre-filling and bi-level key-value decoding. Chunk-based pre-filling divides the visual token sequence into chunks, applying full attention within each chunk and sparse attention across chunks. This significantly reduces computational and memory overhead. During decoding, bi-level key-value decoding selectively reloads either dense or sparse key-values for each chunk based on its relevance to the task. This approach further improves memory efficiency and enhances the model's ability to capture fine-grained information. Video-XL-2 achieves state-of-the-art performance on various long video understanding benchmarks, outperforming existing open-source lightweight models. It also demonstrates exceptional efficiency, capable of processing over 10,000 frames on a single NVIDIA A100 (80GB) GPU and thousands of frames in just a few seconds.
VideoDeepResearch: Long Video Understanding With Agentic Tool Using
Jun 12, 2025Long video understanding (LVU) presents a significant challenge for current multi-modal large language models (MLLMs) due to the task's inherent complexity and context window constraint. It is widely assumed that addressing LVU tasks requires foundation MLLMs with extended context windows, strong visual perception capabilities, and proficient domain expertise. In this work, we challenge this common belief by introducing VideoDeepResearch, a novel agentic framework for long video understanding. Our approach relies solely on a text-only large reasoning model (LRM) combined with a modular multi-modal toolkit, including multimodal retrievers and visual perceivers, all of which are readily available in practice. For each LVU task, the system formulates a problem-solving strategy through reasoning, while selectively accessing and utilizing essential video content via tool using. We conduct extensive experiments on popular LVU benchmarks, including MLVU, Video-MME, and LVBench. Our results demonstrate that VideoDeepResearch achieves substantial improvements over existing MLLM baselines, surpassing the previous state-of-the-art by 9.6%, 6.6%, and 3.9% on MLVU (test), LVBench, and LongVideoBench, respectively. These findings highlight the promise of agentic systems in overcoming key challenges in LVU problems.
Memory-enhanced Retrieval Augmentation for Long Video Understanding
Mar 12, 2025Retrieval-augmented generation (RAG) shows strong potential in addressing long-video understanding (LVU) tasks. However, traditional RAG methods remain fundamentally limited due to their dependence on explicit search queries, which are unavailable in many situations. To overcome this challenge, we introduce a novel RAG-based LVU approach inspired by the cognitive memory of human beings, which is called MemVid. Our approach operates with four basics steps: memorizing holistic video information, reasoning about the task's information needs based on the memory, retrieving critical moments based on the information needs, and focusing on the retrieved moments to produce the final answer. To enhance the system's memory-grounded reasoning capabilities and achieve optimal end-to-end performance, we propose a curriculum learning strategy. This approach begins with supervised learning on well-annotated reasoning results, then progressively explores and reinforces more plausible reasoning outcomes through reinforcement learning. We perform extensive evaluations on popular LVU benchmarks, including MLVU, VideoMME and LVBench. In our experiment, MemVid significantly outperforms existing RAG-based methods and popular LVU models, which demonstrate the effectiveness of our approach. Our model and source code will be made publicly available upon acceptance.
MomentSeeker: A Comprehensive Benchmark and A Strong Baseline For Moment Retrieval Within Long Videos
Feb 18, 2025Retrieval augmented generation (RAG) holds great promise in addressing challenges associated with long video understanding. These methods retrieve useful moments from long videos for their presented tasks, thereby enabling multimodal large language models (MLLMs) to generate high-quality answers in a cost-effective way. In this work, we present MomentSeeker, a comprehensive benchmark to evaluate retrieval models' performance in handling general long-video moment retrieval (LVMR) tasks. MomentSeeker offers three key advantages. First, it incorporates long videos of over 500 seconds on average, making it the first benchmark specialized for long-video moment retrieval. Second, it covers a wide range of task categories (including Moment Search, Caption Alignment, Image-conditioned Moment Search, and Video-conditioned Moment Search) and diverse application scenarios (e.g., sports, movies, cartoons, and ego), making it a comprehensive tool for assessing retrieval models' general LVMR performance. Additionally, the evaluation tasks are carefully curated through human annotation, ensuring the reliability of assessment. We further fine-tune an MLLM-based LVMR retriever on synthetic data, which demonstrates strong performance on our benchmark. We perform extensive experiments with various popular multimodal retrievers based on our benchmark, whose results highlight the challenges of LVMR and limitations for existing methods. Our created resources will be shared with community to advance future research in this field.
OmniGen: Unified Image Generation
Sep 17, 2024
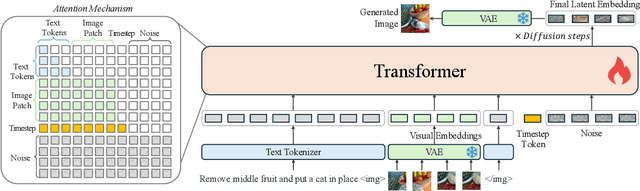
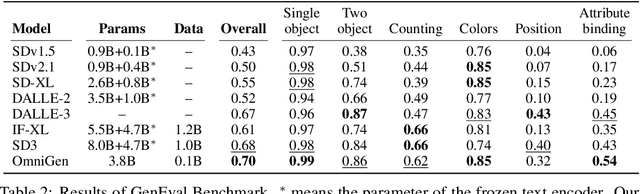

In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at https://github.com/VectorSpaceLab/OmniGen to foster advancements in this field.
AutoDirector: Online Auto-scheduling Agents for Multi-sensory Composition
Aug 21, 2024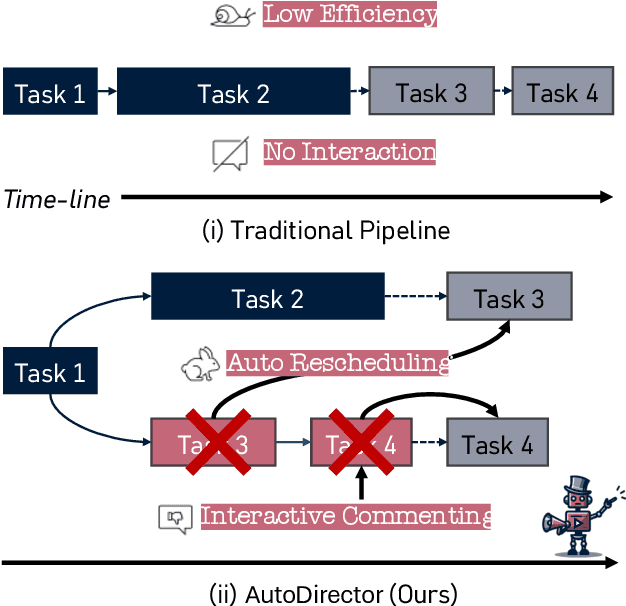

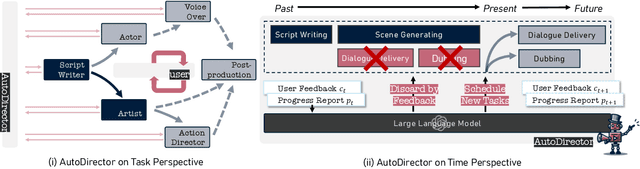

With the advancement of generative models, the synthesis of different sensory elements such as music, visuals, and speech has achieved significant realism. However, the approach to generate multi-sensory outputs has not been fully explored, limiting the application on high-value scenarios such as of directing a film. Developing a movie director agent faces two major challenges: (1) Lack of parallelism and online scheduling with production steps: In the production of multi-sensory films, there are complex dependencies between different sensory elements, and the production time for each element varies. (2) Diverse needs and clear communication demands with users: Users often cannot clearly express their needs until they see a draft, which requires human-computer interaction and iteration to continually adjust and optimize the film content based on user feedback. To address these issues, we introduce AutoDirector, an interactive multi-sensory composition framework that supports long shots, special effects, music scoring, dubbing, and lip-syncing. This framework improves the efficiency of multi-sensory film production through automatic scheduling and supports the modification and improvement of interactive tasks to meet user needs. AutoDirector not only expands the application scope of human-machine collaboration but also demonstrates the potential of AI in collaborating with humans in the role of a film director to complete multi-sensory films.
Large Language Models for Information Retrieval: A Survey
Aug 15, 2023
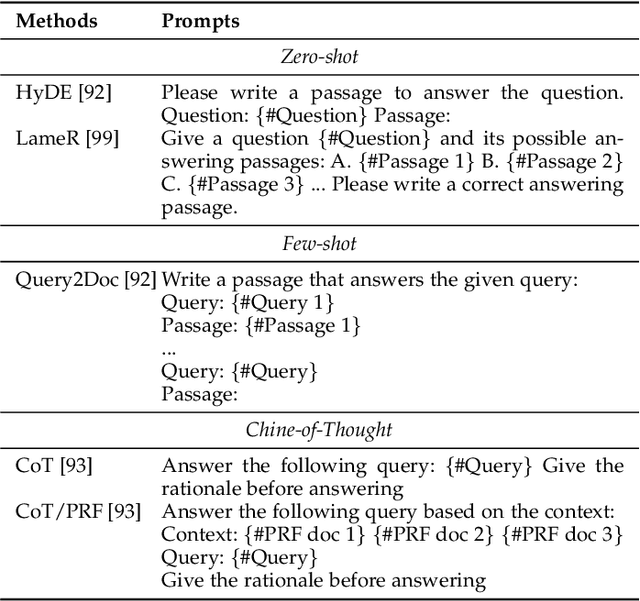
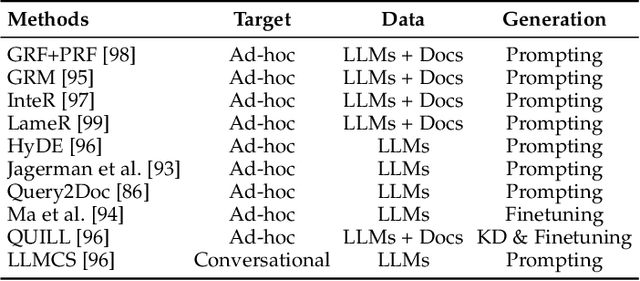
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.
Socialformer: Social Network Inspired Long Document Modeling for Document Ranking
Feb 22, 2022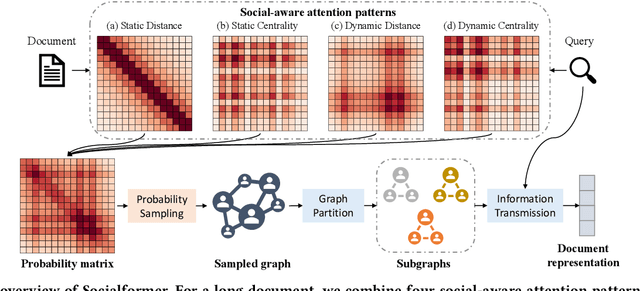
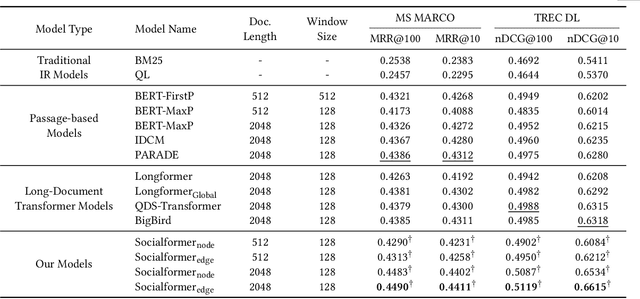
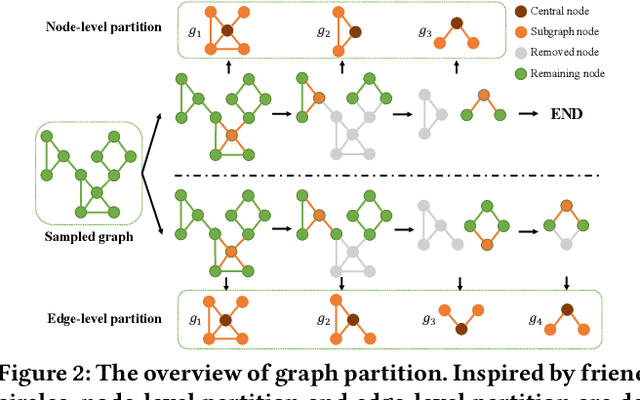

Utilizing pre-trained language models has achieved great success for neural document ranking. Limited by the computational and memory requirements, long document modeling becomes a critical issue. Recent works propose to modify the full attention matrix in Transformer by designing sparse attention patterns. However, most of them only focus on local connections of terms within a fixed-size window. How to build suitable remote connections between terms to better model document representation remains underexplored. In this paper, we propose the model Socialformer, which introduces the characteristics of social networks into designing sparse attention patterns for long document modeling in document ranking. Specifically, we consider several attention patterns to construct a graph like social networks. Endowed with the characteristic of social networks, most pairs of nodes in such a graph can reach with a short path while ensuring the sparsity. To facilitate efficient calculation, we segment the graph into multiple subgraphs to simulate friend circles in social scenarios. Experimental results confirm the effectiveness of our model on long document modeling.