 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
Dec 17, 2025Recent visual generative models often struggle with consistency during image editing due to the entangled nature of raster images, where all visual content is fused into a single canvas. In contrast, professional design tools employ layered representations, allowing isolated edits while preserving consistency. Motivated by this, we propose \textbf{Qwen-Image-Layered}, an end-to-end diffusion model that decomposes a single RGB image into multiple semantically disentangled RGBA layers, enabling \textbf{inherent editability}, where each RGBA layer can be independently manipulated without affecting other content. To support variable-length decomposition, we introduce three key components: (1) an RGBA-VAE to unify the latent representations of RGB and RGBA images; (2) a VLD-MMDiT (Variable Layers Decomposition MMDiT) architecture capable of decomposing a variable number of image layers; and (3) a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer. Furthermore, to address the scarcity of high-quality multilayer training images, we build a pipeline to extract and annotate multilayer images from Photoshop documents (PSD). Experiments demonstrate that our method significantly surpasses existing approaches in decomposition quality and establishes a new paradigm for consistent image editing. Our code and models are released on \href{https://github.com/QwenLM/Qwen-Image-Layered}{https://github.com/QwenLM/Qwen-Image-Layered}
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
AutoDirector: Online Auto-scheduling Agents for Multi-sensory Composition
Aug 21, 2024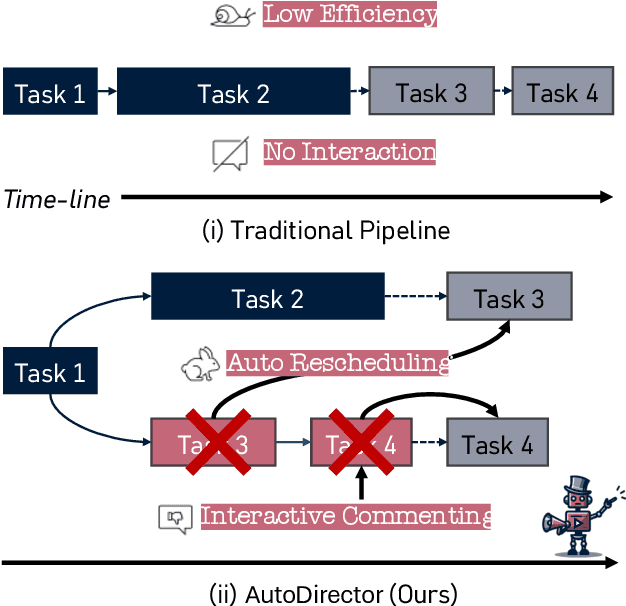

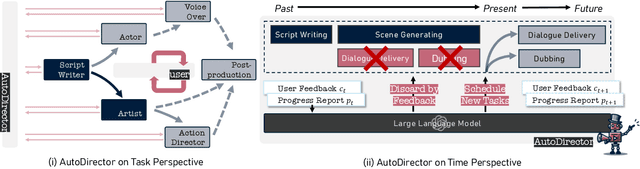

With the advancement of generative models, the synthesis of different sensory elements such as music, visuals, and speech has achieved significant realism. However, the approach to generate multi-sensory outputs has not been fully explored, limiting the application on high-value scenarios such as of directing a film. Developing a movie director agent faces two major challenges: (1) Lack of parallelism and online scheduling with production steps: In the production of multi-sensory films, there are complex dependencies between different sensory elements, and the production time for each element varies. (2) Diverse needs and clear communication demands with users: Users often cannot clearly express their needs until they see a draft, which requires human-computer interaction and iteration to continually adjust and optimize the film content based on user feedback. To address these issues, we introduce AutoDirector, an interactive multi-sensory composition framework that supports long shots, special effects, music scoring, dubbing, and lip-syncing. This framework improves the efficiency of multi-sensory film production through automatic scheduling and supports the modification and improvement of interactive tasks to meet user needs. AutoDirector not only expands the application scope of human-machine collaboration but also demonstrates the potential of AI in collaborating with humans in the role of a film director to complete multi-sensory films.
Predicting Genetic Mutation from Whole Slide Images via Biomedical-Linguistic Knowledge Enhanced Multi-label Classification
Jun 05, 2024Predicting genetic mutations from whole slide images is indispensable for cancer diagnosis. However, existing work training multiple binary classification models faces two challenges: (a) Training multiple binary classifiers is inefficient and would inevitably lead to a class imbalance problem. (b) The biological relationships among genes are overlooked, which limits the prediction performance. To tackle these challenges, we innovatively design a Biological-knowledge enhanced PathGenomic multi-label Transformer to improve genetic mutation prediction performances. BPGT first establishes a novel gene encoder that constructs gene priors by two carefully designed modules: (a) A gene graph whose node features are the genes' linguistic descriptions and the cancer phenotype, with edges modeled by genes' pathway associations and mutation consistencies. (b) A knowledge association module that fuses linguistic and biomedical knowledge into gene priors by transformer-based graph representation learning, capturing the intrinsic relationships between different genes' mutations. BPGT then designs a label decoder that finally performs genetic mutation prediction by two tailored modules: (a) A modality fusion module that firstly fuses the gene priors with critical regions in WSIs and obtains gene-wise mutation logits. (b) A comparative multi-label loss that emphasizes the inherent comparisons among mutation status to enhance the discrimination capabilities. Sufficient experiments on The Cancer Genome Atlas benchmark demonstrate that BPGT outperforms the state-of-the-art.
LVLM-Intrepret: An Interpretability Tool for Large Vision-Language Models
Apr 03, 2024



In the rapidly evolving landscape of artificial intelligence, multi-modal large language models are emerging as a significant area of interest. These models, which combine various forms of data input, are becoming increasingly popular. However, understanding their internal mechanisms remains a complex task. Numerous advancements have been made in the field of explainability tools and mechanisms, yet there is still much to explore. In this work, we present a novel interactive application aimed towards understanding the internal mechanisms of large vision-language models. Our interface is designed to enhance the interpretability of the image patches, which are instrumental in generating an answer, and assess the efficacy of the language model in grounding its output in the image. With our application, a user can systematically investigate the model and uncover system limitations, paving the way for enhancements in system capabilities. Finally, we present a case study of how our application can aid in understanding failure mechanisms in a popular large multi-modal model: LLaVA.
Using Left and Right Brains Together: Towards Vision and Language Planning
Feb 16, 2024



Large Language Models (LLMs) and Large Multi-modality Models (LMMs) have demonstrated remarkable decision masking capabilities on a variety of tasks. However, they inherently operate planning within the language space, lacking the vision and spatial imagination ability. In contrast, humans utilize both left and right hemispheres of the brain for language and visual planning during the thinking process. Therefore, we introduce a novel vision-language planning framework in this work to perform concurrent visual and language planning for tasks with inputs of any form. Our framework incorporates visual planning to capture intricate environmental details, while language planning enhances the logical coherence of the overall system. We evaluate the effectiveness of our framework across vision-language tasks, vision-only tasks, and language-only tasks. The results demonstrate the superior performance of our approach, indicating that the integration of visual and language planning yields better contextually aware task execution.
StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis
Jan 30, 2024To leverage LLMs for visual synthesis, traditional methods convert raster image information into discrete grid tokens through specialized visual modules, while disrupting the model's ability to capture the true semantic representation of visual scenes. This paper posits that an alternative representation of images, vector graphics, can effectively surmount this limitation by enabling a more natural and semantically coherent segmentation of the image information. Thus, we introduce StrokeNUWA, a pioneering work exploring a better visual representation ''stroke tokens'' on vector graphics, which is inherently visual semantics rich, naturally compatible with LLMs, and highly compressed. Equipped with stroke tokens, StrokeNUWA can significantly surpass traditional LLM-based and optimization-based methods across various metrics in the vector graphic generation task. Besides, StrokeNUWA achieves up to a 94x speedup in inference over the speed of prior methods with an exceptional SVG code compression ratio of 6.9%.
EIPE-text: Evaluation-Guided Iterative Plan Extraction for Long-Form Narrative Text Generation
Oct 12, 2023



Plan-and-Write is a common hierarchical approach in long-form narrative text generation, which first creates a plan to guide the narrative writing. Following this approach, several studies rely on simply prompting large language models for planning, which often yields suboptimal results. In this paper, we propose a new framework called Evaluation-guided Iterative Plan Extraction for long-form narrative text generation (EIPE-text), which extracts plans from the corpus of narratives and utilizes the extracted plans to construct a better planner. EIPE-text has three stages: plan extraction, learning, and inference. In the plan extraction stage, it iteratively extracts and improves plans from the narrative corpus and constructs a plan corpus. We propose a question answer (QA) based evaluation mechanism to automatically evaluate the plans and generate detailed plan refinement instructions to guide the iterative improvement. In the learning stage, we build a better planner by fine-tuning with the plan corpus or in-context learning with examples in the plan corpus. Finally, we leverage a hierarchical approach to generate long-form narratives. We evaluate the effectiveness of EIPE-text in the domains of novels and storytelling. Both GPT-4-based evaluations and human evaluations demonstrate that our method can generate more coherent and relevant long-form narratives. Our code will be released in the future.
LayoutNUWA: Revealing the Hidden Layout Expertise of Large Language Models
Sep 19, 2023



Graphic layout generation, a growing research field, plays a significant role in user engagement and information perception. Existing methods primarily treat layout generation as a numerical optimization task, focusing on quantitative aspects while overlooking the semantic information of layout, such as the relationship between each layout element. In this paper, we propose LayoutNUWA, the first model that treats layout generation as a code generation task to enhance semantic information and harness the hidden layout expertise of large language models~(LLMs). More concretely, we develop a Code Instruct Tuning (CIT) approach comprising three interconnected modules: 1) the Code Initialization (CI) module quantifies the numerical conditions and initializes them as HTML code with strategically placed masks; 2) the Code Completion (CC) module employs the formatting knowledge of LLMs to fill in the masked portions within the HTML code; 3) the Code Rendering (CR) module transforms the completed code into the final layout output, ensuring a highly interpretable and transparent layout generation procedure that directly maps code to a visualized layout. We attain significant state-of-the-art performance (even over 50\% improvements) on multiple datasets, showcasing the strong capabilities of LayoutNUWA. Our code is available at https://github.com/ProjectNUWA/LayoutNUWA.
ORES: Open-vocabulary Responsible Visual Synthesis
Aug 26, 2023



Avoiding synthesizing specific visual concepts is an essential challenge in responsible visual synthesis. However, the visual concept that needs to be avoided for responsible visual synthesis tends to be diverse, depending on the region, context, and usage scenarios. In this work, we formalize a new task, Open-vocabulary Responsible Visual Synthesis (ORES), where the synthesis model is able to avoid forbidden visual concepts while allowing users to input any desired content. To address this problem, we present a Two-stage Intervention (TIN) framework. By introducing 1) rewriting with learnable instruction through a large-scale language model (LLM) and 2) synthesizing with prompt intervention on a diffusion synthesis model, it can effectively synthesize images avoiding any concepts but following the user's query as much as possible. To evaluate on ORES, we provide a publicly available dataset, baseline models, and benchmark. Experimental results demonstrate the effectiveness of our method in reducing risks of image generation. Our work highlights the potential of LLMs in responsible visual synthesis. Our code and dataset is public available.