 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Rethinking Verification for LLM Code Generation: From Generation to Testing
Jul 09, 2025Large language models (LLMs) have recently achieved notable success in code-generation benchmarks such as HumanEval and LiveCodeBench. However, a detailed examination reveals that these evaluation suites often comprise only a limited number of homogeneous test cases, resulting in subtle faults going undetected. This not only artificially inflates measured performance but also compromises accurate reward estimation in reinforcement learning frameworks utilizing verifiable rewards (RLVR). To address these critical shortcomings, we systematically investigate the test-case generation (TCG) task by proposing multi-dimensional metrics designed to rigorously quantify test-suite thoroughness. Furthermore, we introduce a human-LLM collaborative method (SAGA), leveraging human programming expertise with LLM reasoning capability, aimed at significantly enhancing both the coverage and the quality of generated test cases. In addition, we develop a TCGBench to facilitate the study of the TCG task. Experiments show that SAGA achieves a detection rate of 90.62% and a verifier accuracy of 32.58% on TCGBench. The Verifier Accuracy (Verifier Acc) of the code generation evaluation benchmark synthesized by SAGA is 10.78% higher than that of LiveCodeBench-v6. These results demonstrate the effectiveness of our proposed method. We hope this work contributes to building a scalable foundation for reliable LLM code evaluation, further advancing RLVR in code generation, and paving the way for automated adversarial test synthesis and adaptive benchmark integration.
Coding Triangle: How Does Large Language Model Understand Code?
Jul 08, 2025Large language models (LLMs) have achieved remarkable progress in code generation, yet their true programming competence remains underexplored. We introduce the Code Triangle framework, which systematically evaluates LLMs across three fundamental dimensions: editorial analysis, code implementation, and test case generation. Through extensive experiments on competitive programming benchmarks, we reveal that while LLMs can form a self-consistent system across these dimensions, their solutions often lack the diversity and robustness of human programmers. We identify a significant distribution shift between model cognition and human expertise, with model errors tending to cluster due to training data biases and limited reasoning transfer. Our study demonstrates that incorporating human-generated editorials, solutions, and diverse test cases, as well as leveraging model mixtures, can substantially enhance both the performance and robustness of LLMs. Furthermore, we reveal both the consistency and inconsistency in the cognition of LLMs that may facilitate self-reflection and self-improvement, providing a potential direction for developing more powerful coding models.
OmniAlign-V: Towards Enhanced Alignment of MLLMs with Human Preference
Feb 25, 2025Recent advancements in open-source multi-modal large language models (MLLMs) have primarily focused on enhancing foundational capabilities, leaving a significant gap in human preference alignment. This paper introduces OmniAlign-V, a comprehensive dataset of 200K high-quality training samples featuring diverse images, complex questions, and varied response formats to improve MLLMs' alignment with human preferences. We also present MM-AlignBench, a human-annotated benchmark specifically designed to evaluate MLLMs' alignment with human values. Experimental results show that finetuning MLLMs with OmniAlign-V, using Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO), significantly enhances human preference alignment while maintaining or enhancing performance on standard VQA benchmarks, preserving their fundamental capabilities. Our datasets, benchmark, code and checkpoints have been released at https://github.com/PhoenixZ810/OmniAlign-V.
Condor: Enhance LLM Alignment with Knowledge-Driven Data Synthesis and Refinement
Jan 21, 2025



The quality of Supervised Fine-Tuning (SFT) data plays a critical role in enhancing the conversational capabilities of Large Language Models (LLMs). However, as LLMs become more advanced, the availability of high-quality human-annotated SFT data has become a significant bottleneck, necessitating a greater reliance on synthetic training data. In this work, we introduce Condor, a novel two-stage synthetic data generation framework that incorporates World Knowledge Tree and Self-Reflection Refinement to produce high-quality SFT data at scale. Our experimental results demonstrate that a base model fine-tuned on only 20K Condor-generated samples achieves superior performance compared to counterparts. The additional refinement stage in Condor further enables iterative self-improvement for LLMs at various scales (up to 72B), validating the effectiveness of our approach. Furthermore, our investigation into the scaling for synthetic data in post-training reveals substantial unexplored potential for performance improvements, opening promising avenues for future research.
CompassJudger-1: All-in-one Judge Model Helps Model Evaluation and Evolution
Oct 21, 2024



Efficient and accurate evaluation is crucial for the continuous improvement of large language models (LLMs). Among various assessment methods, subjective evaluation has garnered significant attention due to its superior alignment with real-world usage scenarios and human preferences. However, human-based evaluations are costly and lack reproducibility, making precise automated evaluators (judgers) vital in this process. In this report, we introduce \textbf{CompassJudger-1}, the first open-source \textbf{all-in-one} judge LLM. CompassJudger-1 is a general-purpose LLM that demonstrates remarkable versatility. It is capable of: 1. Performing unitary scoring and two-model comparisons as a reward model; 2. Conducting evaluations according to specified formats; 3. Generating critiques; 4. Executing diverse tasks like a general LLM. To assess the evaluation capabilities of different judge models under a unified setting, we have also established \textbf{JudgerBench}, a new benchmark that encompasses various subjective evaluation tasks and covers a wide range of topics. CompassJudger-1 offers a comprehensive solution for various evaluation tasks while maintaining the flexibility to adapt to diverse requirements. Both CompassJudger and JudgerBench are released and available to the research community athttps://github.com/open-compass/CompassJudger. We believe that by open-sourcing these tools, we can foster collaboration and accelerate progress in LLM evaluation methodologies.
InternLM-Law: An Open Source Chinese Legal Large Language Model
Jun 21, 2024While large language models (LLMs) have showcased impressive capabilities, they struggle with addressing legal queries due to the intricate complexities and specialized expertise required in the legal field. In this paper, we introduce InternLM-Law, a specialized LLM tailored for addressing diverse legal queries related to Chinese laws, spanning from responding to standard legal questions (e.g., legal exercises in textbooks) to analyzing complex real-world legal situations. We meticulously construct a dataset in the Chinese legal domain, encompassing over 1 million queries, and implement a data filtering and processing pipeline to ensure its diversity and quality. Our training approach involves a novel two-stage process: initially fine-tuning LLMs on both legal-specific and general-purpose content to equip the models with broad knowledge, followed by exclusive fine-tuning on high-quality legal data to enhance structured output generation. InternLM-Law achieves the highest average performance on LawBench, outperforming state-of-the-art models, including GPT-4, on 13 out of 20 subtasks. We make InternLM-Law and our dataset publicly available to facilitate future research in applying LLMs within the legal domain.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model
Jan 29, 2024
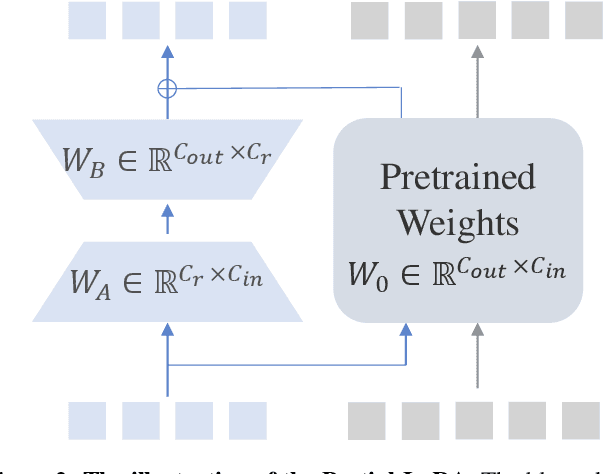

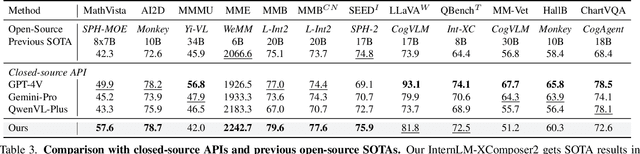
We introduce InternLM-XComposer2, a cutting-edge vision-language model excelling in free-form text-image composition and comprehension. This model goes beyond conventional vision-language understanding, adeptly crafting interleaved text-image content from diverse inputs like outlines, detailed textual specifications, and reference images, enabling highly customizable content creation. InternLM-XComposer2 proposes a Partial LoRA (PLoRA) approach that applies additional LoRA parameters exclusively to image tokens to preserve the integrity of pre-trained language knowledge, striking a balance between precise vision understanding and text composition with literary talent. Experimental results demonstrate the superiority of InternLM-XComposer2 based on InternLM2-7B in producing high-quality long-text multi-modal content and its exceptional vision-language understanding performance across various benchmarks, where it not only significantly outperforms existing multimodal models but also matches or even surpasses GPT-4V and Gemini Pro in certain assessments. This highlights its remarkable proficiency in the realm of multimodal understanding. The InternLM-XComposer2 model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
EIPE-text: Evaluation-Guided Iterative Plan Extraction for Long-Form Narrative Text Generation
Oct 12, 2023



Plan-and-Write is a common hierarchical approach in long-form narrative text generation, which first creates a plan to guide the narrative writing. Following this approach, several studies rely on simply prompting large language models for planning, which often yields suboptimal results. In this paper, we propose a new framework called Evaluation-guided Iterative Plan Extraction for long-form narrative text generation (EIPE-text), which extracts plans from the corpus of narratives and utilizes the extracted plans to construct a better planner. EIPE-text has three stages: plan extraction, learning, and inference. In the plan extraction stage, it iteratively extracts and improves plans from the narrative corpus and constructs a plan corpus. We propose a question answer (QA) based evaluation mechanism to automatically evaluate the plans and generate detailed plan refinement instructions to guide the iterative improvement. In the learning stage, we build a better planner by fine-tuning with the plan corpus or in-context learning with examples in the plan corpus. Finally, we leverage a hierarchical approach to generate long-form narratives. We evaluate the effectiveness of EIPE-text in the domains of novels and storytelling. Both GPT-4-based evaluations and human evaluations demonstrate that our method can generate more coherent and relevant long-form narratives. Our code will be released in the future.