 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
May 13, 2026Long-context modeling is becoming a core capability of modern large vision-language models (LVLMs), enabling sustained context management across long-document understanding, video analysis, and multi-turn tool use in agentic workflows. Yet practical training recipes remain insufficiently explored, particularly for designing and balancing long-context data mixtures. In this work, we present a systematic study of long-context continued pre-training for LVLMs, extending a 7B model from 32K to 128K context with extensive ablations on long-document data. We first show that long-document VQA is substantially more effective than OCR transcription. Building on this observation, our ablations further yield three key findings: i) for sequence-length distribution, balanced data outperforms target-length-focused data (e.g., 128K), suggesting that long-context ability requires generalizable key-information retrieval across various lengths and positions; ii) retrieval remains the primary bottleneck, favoring retrieval-heavy mixtures with modest reasoning data for task diversity; and iii) pure long-document VQA largely preserves short-context capabilities, suggesting that instruction-formatted long data reduces the need for short-data mixing. Based on these findings, we introduce MMProLong, obtained by long-context continued pre-training from Qwen2.5-VL-7B with only a 5B-token budget. MMProLong improves long-document VQA scores by 7.1% and maintains strong performance at 256K and 512K contexts beyond its 128K training window, without additional training. It further generalizes to webpage-based multimodal needle retrieval, long-context vision-text compression, and long-video understanding without task-specific supervision. Overall, our study establishes a practical LongPT recipe and an empirical foundation for advancing long-context vision-language models.
WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
May 11, 2026Large language and vision-language models increasingly power agents that act on a user's behalf through command-line interface (CLI) harnesses. However, most agent benchmarks still rely on synthetic sandboxes, short-horizon tasks, mock-service APIs, and final-answer checks, leaving open whether agents can complete realistic long-horizon work in the runtimes where they are deployed. This work presents WildClawBench, a native-runtime benchmark of 60 human-authored, bilingual, multimodal tasks spanning six thematic categories. Each task averages roughly 8 minutes of wall-clock time and over 20 tool calls, and runs inside a reproducible Docker container hosting an actual CLI agent harness (OpenClaw, Claude Code, Codex, or Hermes Agent) with access to real tools rather than mock services. Grading is hybrid, combining deterministic rule-based checks, environment-state auditing of side effects, and an LLM/VLM judge for semantic verification. Across 19 frontier models, the best, Claude Opus 4.7, reaches only 62.2% overall under OpenClaw, while every other model stays below 60%, and switching harness alone shifts a single model by up to 18 points. These results show that long-horizon, native-runtime agent evaluation remains a far-from-resolved task for current frontier models. We release the tasks, code, and containerized tooling to support reproducible evaluation.
VideoZeroBench: Probing the Limits of Video MLLMs with Spatio-Temporal Evidence Verification
Apr 02, 2026Recent video multimodal large language models achieve impressive results across various benchmarks. However, current evaluations suffer from two critical limitations: (1) inflated scores can mask deficiencies in fine-grained visual understanding and reasoning, and (2) answer correctness is often measured without verifying whether models identify the precise spatio-temporal evidence supporting their predictions. To address this, we present VideoZeroBench, a hierarchical benchmark designed for challenging long-video question answering that rigorously verifies spatio-temporal evidence. It comprises 500 manually annotated questions across 13 domains, paired with temporal intervals and spatial bounding boxes as evidence. To disentangle answering generation, temporal grounding, and spatial grounding, we introduce a five-level evaluation protocol that progressively tightens evidence requirements. Experiments show that even Gemini-3-Pro correctly answers fewer than 17% of questions under the standard end-to-end QA setting (Level-3). When grounding constraints are imposed, performance drops sharply: No model exceeds 1% accuracy when both correct answering and accurate spatio-temporal localization are required (Level-5), with most failing to achieve any correct grounded predictions. These results expose a significant gap between surface-level answer correctness and genuine evidence-based reasoning, revealing that grounded video understanding remains a bottleneck for long-video QA. We further analyze performance across minimal evidence spans, atomic abilities, and inference paradigms, providing insights for future research in grounded video reasoning. The benchmark and code will be made publicly available.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
PosterIQ: A Design Perspective Benchmark for Poster Understanding and Generation
Mar 25, 2026We present PosterIQ, a design-driven benchmark for poster understanding and generation, annotated across composition structure, typographic hierarchy, and semantic intent. It includes 7,765 image-annotation instances and 822 generation prompts spanning real, professional, and synthetic cases. To bridge visual design cognition and generative modeling, we define tasks for layout parsing, text-image correspondence, typography/readability and font perception, design quality assessment, and controllable, composition-aware generation with metaphor. We evaluate state-of-the-art MLLMs and diffusion-based generators, finding persistent gaps in visual hierarchy, typographic semantics, saliency control, and intention communication; commercial models lead on high-level reasoning but act as insensitive automatic raters, while generators render text well yet struggle with composition-aware synthesis. Extensive analyses show PosterIQ is both a quantitative benchmark and a diagnostic tool for design reasoning, offering reproducible, task-specific metrics. We aim to catalyze models' creativity and integrate human-centred design principles into generative vision-language systems.
MIBench: Evaluating LMMs on Multimodal Interaction
Mar 13, 2026In different multimodal scenarios, it needs to integrate and utilize information across modalities in a specific way based on the demands of the task. Different integration ways between modalities are referred to as "multimodal interaction". How well a model handles various multimodal interactions largely characterizes its multimodal ability. In this paper, we introduce MIBench, a comprehensive benchmark designed to evaluate the multimodal interaction capabilities of Large Multimodal Models (LMMs), which formulates each instance as a (con_v , con_t, task) triplet with contexts from vision and text, necessitating that LMMs employ correct forms of multimodal interaction to effectively complete the task. MIBench assesses models from three key aspects: the ability to source information from vision-centric or text-centric cues, and the ability to generate new information from their joint synergy. Each interaction capability is evaluated hierarchically across three cognitive levels: Recognition, Understanding, and Reasoning. MIBench comprises over 10,000 vision-text context pairs spanning 32 distinct tasks. Evaluation of state-of-the-art LMMs show that: (1) LMMs' ability on multimodal interaction remains constrained, despite the scaling of model parameters and training data; (2) they are easily distracted by textual modalities when processing vision information; (3) they mostly possess a basic capacity for multimodal synergy; and (4) natively trained multimodal models show noticeable deficits in fundamental interaction ability. We expect that these observations can serve as a reference for developing LMMs with more enhanced multimodal ability in the future.
RISE-Video: Can Video Generators Decode Implicit World Rules?
Feb 05, 2026While generative video models have achieved remarkable visual fidelity, their capacity to internalize and reason over implicit world rules remains a critical yet under-explored frontier. To bridge this gap, we present RISE-Video, a pioneering reasoning-oriented benchmark for Text-Image-to-Video (TI2V) synthesis that shifts the evaluative focus from surface-level aesthetics to deep cognitive reasoning. RISE-Video comprises 467 meticulously human-annotated samples spanning eight rigorous categories, providing a structured testbed for probing model intelligence across diverse dimensions, ranging from commonsense and spatial dynamics to specialized subject domains. Our framework introduces a multi-dimensional evaluation protocol consisting of four metrics: \textit{Reasoning Alignment}, \textit{Temporal Consistency}, \textit{Physical Rationality}, and \textit{Visual Quality}. To further support scalable evaluation, we propose an automated pipeline leveraging Large Multimodal Models (LMMs) to emulate human-centric assessment. Extensive experiments on 11 state-of-the-art TI2V models reveal pervasive deficiencies in simulating complex scenarios under implicit constraints, offering critical insights for the advancement of future world-simulating generative models.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
Think Visually, Reason Textually: Vision-Language Synergy in ARC
Nov 19, 2025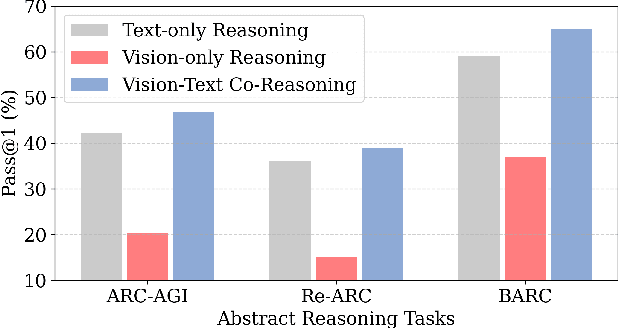
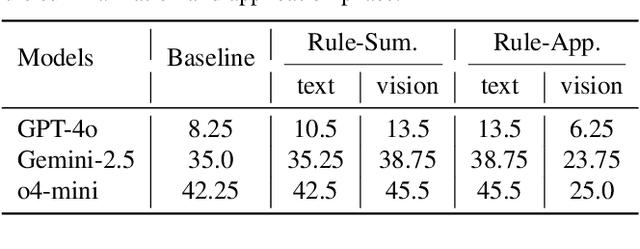

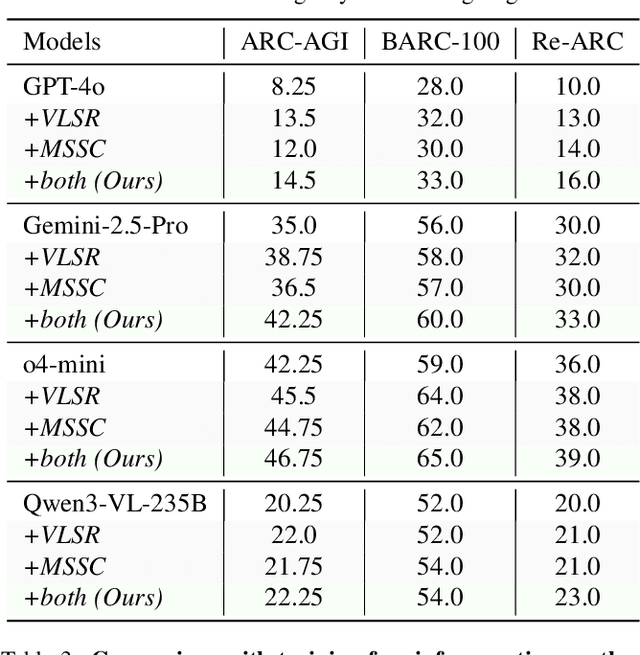
Abstract reasoning from minimal examples remains a core unsolved problem for frontier foundation models such as GPT-5 and Grok 4. These models still fail to infer structured transformation rules from a handful of examples, which is a key hallmark of human intelligence. The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) provides a rigorous testbed for this capability, demanding conceptual rule induction and transfer to novel tasks. Most existing methods treat ARC-AGI as a purely textual reasoning task, overlooking the fact that humans rely heavily on visual abstraction when solving such puzzles. However, our pilot experiments reveal a paradox: naively rendering ARC-AGI grids as images degrades performance due to imprecise rule execution. This leads to our central hypothesis that vision and language possess complementary strengths across distinct reasoning stages: vision supports global pattern abstraction and verification, whereas language specializes in symbolic rule formulation and precise execution. Building on this insight, we introduce two synergistic strategies: (1) Vision-Language Synergy Reasoning (VLSR), which decomposes ARC-AGI into modality-aligned subtasks; and (2) Modality-Switch Self-Correction (MSSC), which leverages vision to verify text-based reasoning for intrinsic error correction. Extensive experiments demonstrate that our approach yields up to a 4.33% improvement over text-only baselines across diverse flagship models and multiple ARC-AGI tasks. Our findings suggest that unifying visual abstraction with linguistic reasoning is a crucial step toward achieving generalizable, human-like intelligence in future foundation models. Source code will be released soon.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.