 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
Mar 12, 2026Reinforcement learning (RL) has emerged as a promising paradigm for enhancing image editing and text-to-image (T2I) generation. However, current reward models, which act as critics during RL, often suffer from hallucinations and assign noisy scores, inherently misguiding the optimization process. In this paper, we present FIRM (Faithful Image Reward Modeling), a comprehensive framework that develops robust reward models to provide accurate and reliable guidance for faithful image generation and editing. First, we design tailored data curation pipelines to construct high-quality scoring datasets. Specifically, we evaluate editing using both execution and consistency, while generation is primarily assessed via instruction following. Using these pipelines, we collect the FIRM-Edit-370K and FIRM-Gen-293K datasets, and train specialized reward models (FIRM-Edit-8B and FIRM-Gen-8B) that accurately reflect these criteria. Second, we introduce FIRM-Bench, a comprehensive benchmark specifically designed for editing and generation critics. Evaluations demonstrate that our models achieve superior alignment with human judgment compared to existing metrics. Furthermore, to seamlessly integrate these critics into the RL pipeline, we formulate a novel "Base-and-Bonus" reward strategy that balances competing objectives: Consistency-Modulated Execution (CME) for editing and Quality-Modulated Alignment (QMA) for generation. Empowered by this framework, our resulting models FIRM-Qwen-Edit and FIRM-SD3.5 achieve substantial performance breakthroughs. Comprehensive experiments demonstrate that FIRM mitigates hallucinations, establishing a new standard for fidelity and instruction adherence over existing general models. All of our datasets, models, and code have been publicly available at https://firm-reward.github.io.
Combinatorial Sparse PCA Beyond the Spiked Identity Model
Mar 03, 2026Sparse PCA is one of the most well-studied problems in high-dimensional statistics. In this problem, we are given samples from a distribution with covariance $Σ$, whose top eigenvector $v \in R^d$ is $s$-sparse. Existing sparse PCA algorithms can be broadly categorized into (1) combinatorial algorithms (e.g., diagonal or elementwise covariance thresholding) and (2) SDP-based algorithms. While combinatorial algorithms are much simpler, they are typically only analyzed under the spiked identity model (where $Σ= I_d + γvv^\top$ for some $γ> 0$), whereas SDP-based algorithms require no additional assumptions on $Σ$. We demonstrate explicit counterexample covariances $Σ$ against the success of standard combinatorial algorithms for sparse PCA, when moving beyond the spiked identity model. In light of this discrepancy, we give the first combinatorial method for sparse PCA that provably succeeds for general $Σ$ using $s^2 \cdot \mathrm{polylog}(d)$ samples and $d^2 \cdot \mathrm{poly}(s, \log(d))$ time, by providing a global convergence guarantee on a variant of the truncated power method of Yuan and Zhang (2013). We provide a natural generalization of our method to recovering a vector in a sparse leading eigenspace. Finally, we evaluate our method on synthetic and real-world sparse PCA datasets.
d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation
Jan 12, 2026Diffusion large language models (dLLMs) offer capabilities beyond those of autoregressive (AR) LLMs, such as parallel decoding and random-order generation. However, realizing these benefits in practice is non-trivial, as dLLMs inherently face an accuracy-parallelism trade-off. Despite increasing interest, existing methods typically focus on only one-side of the coin, targeting either efficiency or performance. To address this limitation, we propose d3LLM (Pseudo-Distilled Diffusion Large Language Model), striking a balance between accuracy and parallelism: (i) during training, we introduce pseudo-trajectory distillation to teach the model which tokens can be decoded confidently at early steps, thereby improving parallelism; (ii) during inference, we employ entropy-based multi-block decoding with a KV-cache refresh mechanism to achieve high parallelism while maintaining accuracy. To better evaluate dLLMs, we also introduce AUP (Accuracy Under Parallelism), a new metric that jointly measures accuracy and parallelism. Experiments demonstrate that our d3LLM achieves up to 10$\times$ speedup over vanilla LLaDA/Dream and 5$\times$ speedup over AR models without much accuracy drop. Our code is available at https://github.com/hao-ai-lab/d3LLM.
Partial Weakly-Supervised Oriented Object Detection
Jul 03, 2025
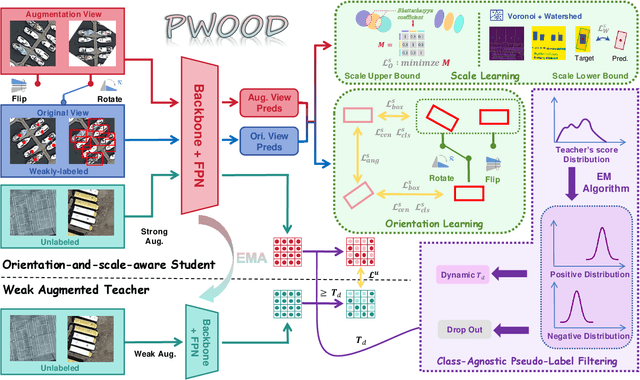


The growing demand for oriented object detection (OOD) across various domains has driven significant research in this area. However, the high cost of dataset annotation remains a major concern. Current mainstream OOD algorithms can be mainly categorized into three types: (1) fully supervised methods using complete oriented bounding box (OBB) annotations, (2) semi-supervised methods using partial OBB annotations, and (3) weakly supervised methods using weak annotations such as horizontal boxes or points. However, these algorithms inevitably increase the cost of models in terms of annotation speed or annotation cost. To address this issue, we propose:(1) the first Partial Weakly-Supervised Oriented Object Detection (PWOOD) framework based on partially weak annotations (horizontal boxes or single points), which can efficiently leverage large amounts of unlabeled data, significantly outperforming weakly supervised algorithms trained with partially weak annotations, also offers a lower cost solution; (2) Orientation-and-Scale-aware Student (OS-Student) model capable of learning orientation and scale information with only a small amount of orientation-agnostic or scale-agnostic weak annotations; and (3) Class-Agnostic Pseudo-Label Filtering strategy (CPF) to reduce the model's sensitivity to static filtering thresholds. Comprehensive experiments on DOTA-v1.0/v1.5/v2.0 and DIOR datasets demonstrate that our PWOOD framework performs comparably to, or even surpasses, traditional semi-supervised algorithms.
An Optimized Franz-Parisi Criterion and its Equivalence with SQ Lower Bounds
Jun 06, 2025Bandeira et al. (2022) introduced the Franz-Parisi (FP) criterion for characterizing the computational hard phases in statistical detection problems. The FP criterion, based on an annealed version of the celebrated Franz-Parisi potential from statistical physics, was shown to be equivalent to low-degree polynomial (LDP) lower bounds for Gaussian additive models, thereby connecting two distinct approaches to understanding the computational hardness in statistical inference. In this paper, we propose a refined FP criterion that aims to better capture the geometric ``overlap" structure of statistical models. Our main result establishes that this optimized FP criterion is equivalent to Statistical Query (SQ) lower bounds -- another foundational framework in computational complexity of statistical inference. Crucially, this equivalence holds under a mild, verifiable assumption satisfied by a broad class of statistical models, including Gaussian additive models, planted sparse models, as well as non-Gaussian component analysis (NGCA), single-index (SI) models, and convex truncation detection settings. For instance, in the case of convex truncation tasks, the assumption is equivalent with the Gaussian correlation inequality (Royen, 2014) from convex geometry. In addition to the above, our equivalence not only unifies and simplifies the derivation of several known SQ lower bounds -- such as for the NGCA model (Diakonikolas et al., 2017) and the SI model (Damian et al., 2024) -- but also yields new SQ lower bounds of independent interest, including for the computational gaps in mixed sparse linear regression (Arpino et al., 2023) and convex truncation (De et al., 2023).
Faster Video Diffusion with Trainable Sparse Attention
May 19, 2025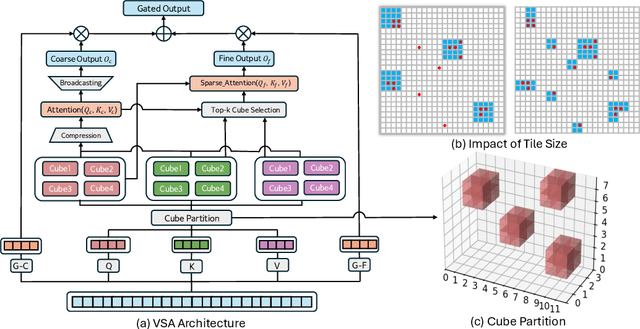
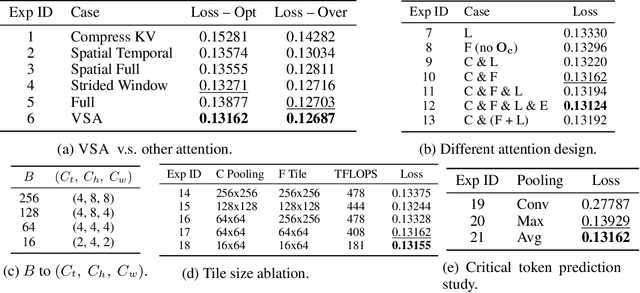
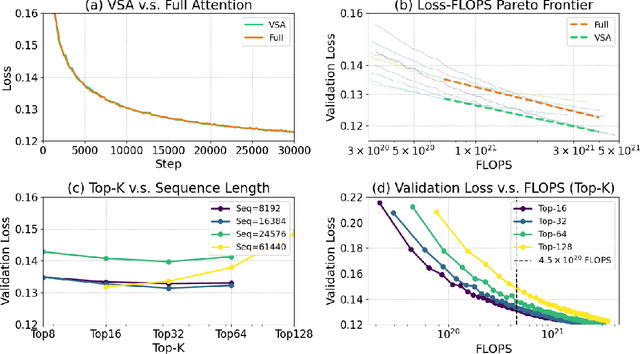
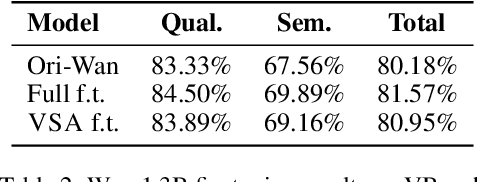
Scaling video diffusion transformers (DiTs) is limited by their quadratic 3D attention, even though most of the attention mass concentrates on a small subset of positions. We turn this observation into VSA, a trainable, hardware-efficient sparse attention that replaces full attention at \emph{both} training and inference. In VSA, a lightweight coarse stage pools tokens into tiles and identifies high-weight \emph{critical tokens}; a fine stage computes token-level attention only inside those tiles subjecting to block computing layout to ensure hard efficiency. This leads to a single differentiable kernel that trains end-to-end, requires no post-hoc profiling, and sustains 85\% of FlashAttention3 MFU. We perform a large sweep of ablation studies and scaling-law experiments by pretraining DiTs from 60M to 1.4B parameters. VSA reaches a Pareto point that cuts training FLOPS by 2.53$\times$ with no drop in diffusion loss. Retrofitting the open-source Wan-2.1 model speeds up attention time by 6$\times$ and lowers end-to-end generation time from 31s to 18s with comparable quality. These results establish trainable sparse attention as a practical alternative to full attention and a key enabler for further scaling of video diffusion models.
Envisioning Beyond the Pixels: Benchmarking Reasoning-Informed Visual Editing
Apr 03, 2025Large Multi-modality Models (LMMs) have made significant progress in visual understanding and generation, but they still face challenges in General Visual Editing, particularly in following complex instructions, preserving appearance consistency, and supporting flexible input formats. To address this gap, we introduce RISEBench, the first benchmark for evaluating Reasoning-Informed viSual Editing (RISE). RISEBench focuses on four key reasoning types: Temporal, Causal, Spatial, and Logical Reasoning. We curate high-quality test cases for each category and propose an evaluation framework that assesses Instruction Reasoning, Appearance Consistency, and Visual Plausibility with both human judges and an LMM-as-a-judge approach. Our experiments reveal that while GPT-4o-Native significantly outperforms other open-source and proprietary models, even this state-of-the-art system struggles with logical reasoning tasks, highlighting an area that remains underexplored. As an initial effort, RISEBench aims to provide foundational insights into reasoning-aware visual editing and to catalyze future research. Though still in its early stages, we are committed to continuously expanding and refining the benchmark to support more comprehensive, reliable, and scalable evaluations of next-generation multimodal systems. Our code and data will be released at https://github.com/PhoenixZ810/RISEBench.
EgoLife: Towards Egocentric Life Assistant
Mar 05, 2025We introduce EgoLife, a project to develop an egocentric life assistant that accompanies and enhances personal efficiency through AI-powered wearable glasses. To lay the foundation for this assistant, we conducted a comprehensive data collection study where six participants lived together for one week, continuously recording their daily activities - including discussions, shopping, cooking, socializing, and entertainment - using AI glasses for multimodal egocentric video capture, along with synchronized third-person-view video references. This effort resulted in the EgoLife Dataset, a comprehensive 300-hour egocentric, interpersonal, multiview, and multimodal daily life dataset with intensive annotation. Leveraging this dataset, we introduce EgoLifeQA, a suite of long-context, life-oriented question-answering tasks designed to provide meaningful assistance in daily life by addressing practical questions such as recalling past relevant events, monitoring health habits, and offering personalized recommendations. To address the key technical challenges of (1) developing robust visual-audio models for egocentric data, (2) enabling identity recognition, and (3) facilitating long-context question answering over extensive temporal information, we introduce EgoButler, an integrated system comprising EgoGPT and EgoRAG. EgoGPT is an omni-modal model trained on egocentric datasets, achieving state-of-the-art performance on egocentric video understanding. EgoRAG is a retrieval-based component that supports answering ultra-long-context questions. Our experimental studies verify their working mechanisms and reveal critical factors and bottlenecks, guiding future improvements. By releasing our datasets, models, and benchmarks, we aim to stimulate further research in egocentric AI assistants.
Efficient-vDiT: Efficient Video Diffusion Transformers With Attention Tile
Feb 10, 2025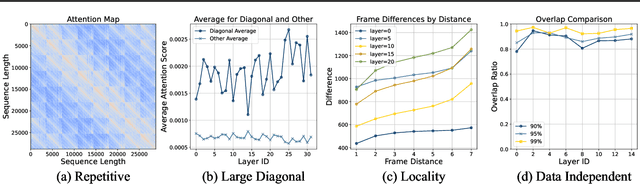
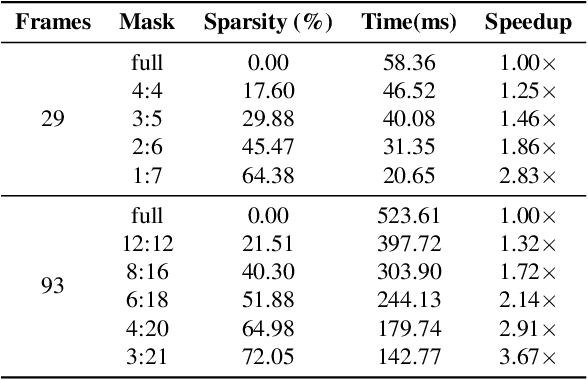


Despite the promise of synthesizing high-fidelity videos, Diffusion Transformers (DiTs) with 3D full attention suffer from expensive inference due to the complexity of attention computation and numerous sampling steps. For example, the popular Open-Sora-Plan model consumes more than 9 minutes for generating a single video of 29 frames. This paper addresses the inefficiency issue from two aspects: 1) Prune the 3D full attention based on the redundancy within video data; We identify a prevalent tile-style repetitive pattern in the 3D attention maps for video data, and advocate a new family of sparse 3D attention that holds a linear complexity w.r.t. the number of video frames. 2) Shorten the sampling process by adopting existing multi-step consistency distillation; We split the entire sampling trajectory into several segments and perform consistency distillation within each one to activate few-step generation capacities. We further devise a three-stage training pipeline to conjoin the low-complexity attention and few-step generation capacities. Notably, with 0.1% pretraining data, we turn the Open-Sora-Plan-1.2 model into an efficient one that is 7.4x -7.8x faster for 29 and 93 frames 720p video generation with a marginal performance trade-off in VBench. In addition, we demonstrate that our approach is amenable to distributed inference, achieving an additional 3.91x speedup when running on 4 GPUs with sequence parallelism.