 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISE-Video: Can Video Generators Decode Implicit World Rules?
Feb 05, 2026While generative video models have achieved remarkable visual fidelity, their capacity to internalize and reason over implicit world rules remains a critical yet under-explored frontier. To bridge this gap, we present RISE-Video, a pioneering reasoning-oriented benchmark for Text-Image-to-Video (TI2V) synthesis that shifts the evaluative focus from surface-level aesthetics to deep cognitive reasoning. RISE-Video comprises 467 meticulously human-annotated samples spanning eight rigorous categories, providing a structured testbed for probing model intelligence across diverse dimensions, ranging from commonsense and spatial dynamics to specialized subject domains. Our framework introduces a multi-dimensional evaluation protocol consisting of four metrics: \textit{Reasoning Alignment}, \textit{Temporal Consistency}, \textit{Physical Rationality}, and \textit{Visual Quality}. To further support scalable evaluation, we propose an automated pipeline leveraging Large Multimodal Models (LMMs) to emulate human-centric assessment. Extensive experiments on 11 state-of-the-art TI2V models reveal pervasive deficiencies in simulating complex scenarios under implicit constraints, offering critical insights for the advancement of future world-simulating generative models.
Pathwise Test-Time Correction for Autoregressive Long Video Generation
Feb 05, 2026Distilled autoregressive diffusion models facilitate real-time short video synthesis but suffer from severe error accumulation during long-sequence generation. While existing Test-Time Optimization (TTO) methods prove effective for images or short clips, we identify that they fail to mitigate drift in extended sequences due to unstable reward landscapes and the hypersensitivity of distilled parameters. To overcome these limitations, we introduce Test-Time Correction (TTC), a training-free alternative. Specifically, TTC utilizes the initial frame as a stable reference anchor to calibrate intermediate stochastic states along the sampling trajectory. Extensive experiments demonstrate that our method seamlessly integrates with various distilled models, extending generation lengths with negligible overhead while matching the quality of resource-intensive training-based methods on 30-second benchmarks.
Repulsor: Accelerating Generative Modeling with a Contrastive Memory Bank
Dec 13, 2025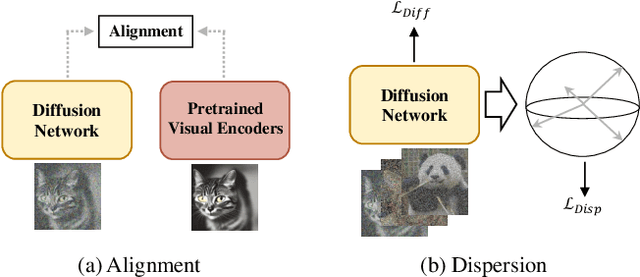
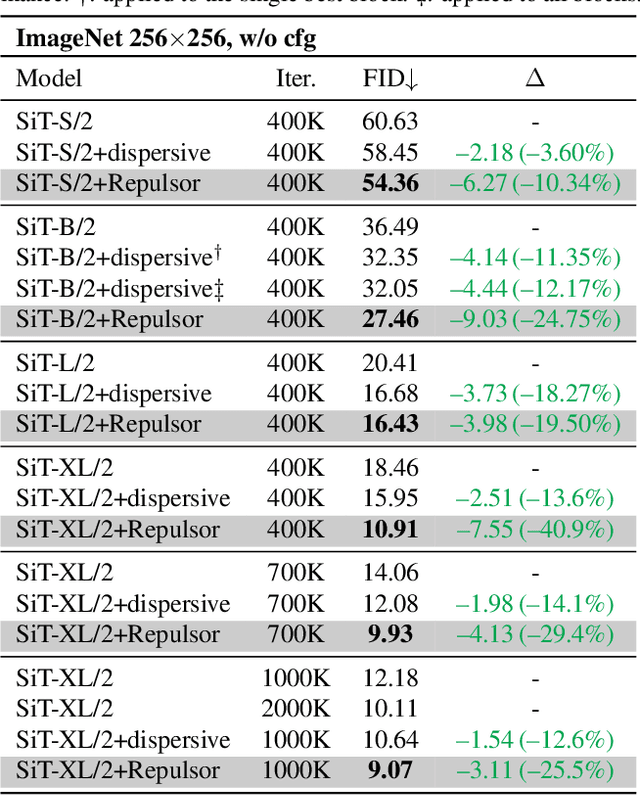
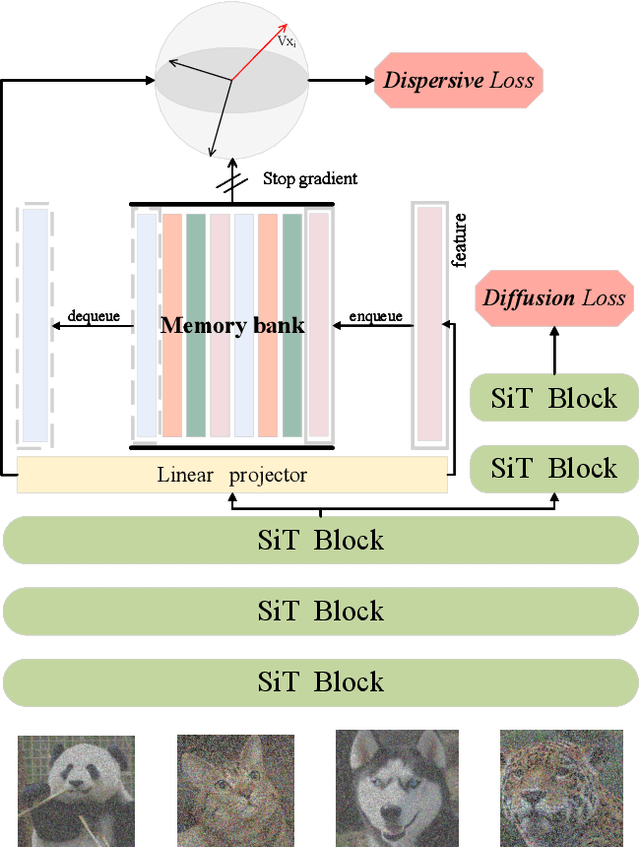

The dominance of denoising generative models (e.g., diffusion, flow-matching) in visual synthesis is tempered by their substantial training costs and inefficiencies in representation learning. While injecting discriminative representations via auxiliary alignment has proven effective, this approach still faces key limitations: the reliance on external, pre-trained encoders introduces overhead and domain shift. A dispersed-based strategy that encourages strong separation among in-batch latent representations alleviates this specific dependency. To assess the effect of the number of negative samples in generative modeling, we propose {\mname}, a plug-and-play training framework that requires no external encoders. Our method integrates a memory bank mechanism that maintains a large, dynamically updated queue of negative samples across training iterations. This decouples the number of negatives from the mini-batch size, providing abundant and high-quality negatives for a contrastive objective without a multiplicative increase in computational cost. A low-dimensional projection head is used to further minimize memory and bandwidth overhead. {\mname} offers three principal advantages: (1) it is self-contained, eliminating dependency on pretrained vision foundation models and their associated forward-pass overhead; (2) it introduces no additional parameters or computational cost during inference; and (3) it enables substantially faster convergence, achieving superior generative quality more efficiently. On ImageNet-256, {\mname} achieves a state-of-the-art FID of \textbf{2.40} within 400k steps, significantly outperforming comparable methods.
Dual-Branch Center-Surrounding Contrast: Rethinking Contrastive Learning for 3D Point Clouds
Dec 09, 2025



Most existing self-supervised learning (SSL) approaches for 3D point clouds are dominated by generative methods based on Masked Autoencoders (MAE). However, these generative methods have been proven to struggle to capture high-level discriminative features effectively, leading to poor performance on linear probing and other downstream tasks. In contrast, contrastive methods excel in discriminative feature representation and generalization ability on image data. Despite this, contrastive learning (CL) in 3D data remains scarce. Besides, simply applying CL methods designed for 2D data to 3D fails to effectively learn 3D local details. To address these challenges, we propose a novel Dual-Branch \textbf{C}enter-\textbf{S}urrounding \textbf{Con}trast (CSCon) framework. Specifically, we apply masking to the center and surrounding parts separately, constructing dual-branch inputs with center-biased and surrounding-biased representations to better capture rich geometric information. Meanwhile, we introduce a patch-level contrastive loss to further enhance both high-level information and local sensitivity. Under the FULL and ALL protocols, CSCon achieves performance comparable to generative methods; under the MLP-LINEAR, MLP-3, and ONLY-NEW protocols, our method attains state-of-the-art results, even surpassing cross-modal approaches. In particular, under the MLP-LINEAR protocol, our method outperforms the baseline (Point-MAE) by \textbf{7.9\%}, \textbf{6.7\%}, and \textbf{10.3\%} on the three variants of ScanObjectNN, respectively. The code will be made publicly available.
Denoising Vision Transformer Autoencoder with Spectral Self-Regularization
Nov 16, 2025Variational autoencoders (VAEs) typically encode images into a compact latent space, reducing computational cost but introducing an optimization dilemma: a higher-dimensional latent space improves reconstruction fidelity but often hampers generative performance. Recent methods attempt to address this dilemma by regularizing high-dimensional latent spaces using external vision foundation models (VFMs). However, it remains unclear how high-dimensional VAE latents affect the optimization of generative models. To our knowledge, our analysis is the first to reveal that redundant high-frequency components in high-dimensional latent spaces hinder the training convergence of diffusion models and, consequently, degrade generation quality. To alleviate this problem, we propose a spectral self-regularization strategy to suppress redundant high-frequency noise while simultaneously preserving reconstruction quality. The resulting Denoising-VAE, a ViT-based autoencoder that does not rely on VFMs, produces cleaner, lower-noise latents, leading to improved generative quality and faster optimization convergence. We further introduce a spectral alignment strategy to facilitate the optimization of Denoising-VAE-based generative models. Our complete method enables diffusion models to converge approximately 2$\times$ faster than with SD-VAE, while achieving state-of-the-art reconstruction quality (rFID = 0.28, PSNR = 27.26) and competitive generation performance (gFID = 1.82) on the ImageNet 256$\times$256 benchmark.
VideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models
May 29, 2025Recent advancements in text-to-video (T2V) diffusion models have enabled high-fidelity and realistic video synthesis. However, current T2V models often struggle to generate physically plausible content due to their limited inherent ability to accurately understand physics. We found that while the representations within T2V models possess some capacity for physics understanding, they lag significantly behind those from recent video self-supervised learning methods. To this end, we propose a novel framework called VideoREPA, which distills physics understanding capability from video understanding foundation models into T2V models by aligning token-level relations. This closes the physics understanding gap and enable more physics-plausible generation. Specifically, we introduce the Token Relation Distillation (TRD) loss, leveraging spatio-temporal alignment to provide soft guidance suitable for finetuning powerful pre-trained T2V models, a critical departure from prior representation alignment (REPA) methods. To our knowledge, VideoREPA is the first REPA method designed for finetuning T2V models and specifically for injecting physical knowledge. Empirical evaluations show that VideoREPA substantially enhances the physics commonsense of baseline method, CogVideoX, achieving significant improvement on relevant benchmarks and demonstrating a strong capacity for generating videos consistent with intuitive physics. More video results are available at https://videorepa.github.io/.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Point2RBox-v2: Rethinking Point-supervised Oriented Object Detection with Spatial Layout Among Instances
Feb 07, 2025



With the rapidly increasing demand for oriented object detection (OOD), recent research involving weakly-supervised detectors for learning OOD from point annotations has gained great attention. In this paper, we rethink this challenging task setting with the layout among instances and present Point2RBox-v2. At the core are three principles: 1) Gaussian overlap loss. It learns an upper bound for each instance by treating objects as 2D Gaussian distributions and minimizing their overlap. 2) Voronoi watershed loss. It learns a lower bound for each instance through watershed on Voronoi tessellation. 3) Consistency loss. It learns the size/rotation variation between two output sets with respect to an input image and its augmented view. Supplemented by a few devised techniques, e.g. edge loss and copy-paste, the detector is further enhanced. To our best knowledge, Point2RBox-v2 is the first approach to explore the spatial layout among instances for learning point-supervised OOD. Our solution is elegant and lightweight, yet it is expected to give a competitive performance especially in densely packed scenes: 62.61%/86.15%/34.71% on DOTA/HRSC/FAIR1M. Code is available at https://github.com/VisionXLab/point2rbox-v2.
Motion Control for Enhanced Complex Action Video Generation
Nov 13, 2024
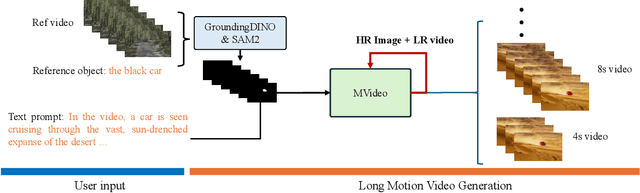

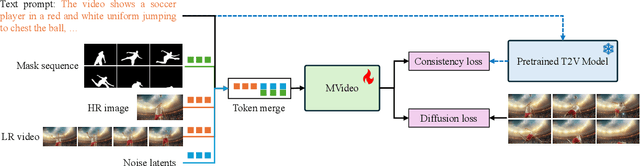
Existing text-to-video (T2V) models often struggle with generating videos with sufficiently pronounced or complex actions. A key limitation lies in the text prompt's inability to precisely convey intricate motion details. To address this, we propose a novel framework, MVideo, designed to produce long-duration videos with precise, fluid actions. MVideo overcomes the limitations of text prompts by incorporating mask sequences as an additional motion condition input, providing a clearer, more accurate representation of intended actions. Leveraging foundational vision models such as GroundingDINO and SAM2, MVideo automatically generates mask sequences, enhancing both efficiency and robustness. Our results demonstrate that, after training, MVideo effectively aligns text prompts with motion conditions to produce videos that simultaneously meet both criteria. This dual control mechanism allows for more dynamic video generation by enabling alterations to either the text prompt or motion condition independently, or both in tandem. Furthermore, MVideo supports motion condition editing and composition, facilitating the generation of videos with more complex actions. MVideo thus advances T2V motion generation, setting a strong benchmark for improved action depiction in current video diffusion models. Our project page is available at https://mvideo-v1.github.io/.
Exploiting Unlabeled Data with Multiple Expert Teachers for Open Vocabulary Aerial Object Detection and Its Orientation Adaptation
Nov 04, 2024



In recent years, aerial object detection has been increasingly pivotal in various earth observation applications. However, current algorithms are limited to detecting a set of pre-defined object categories, demanding sufficient annotated training samples, and fail to detect novel object categories. In this paper, we put forth a novel formulation of the aerial object detection problem, namely open-vocabulary aerial object detection (OVAD), which can detect objects beyond training categories without costly collecting new labeled data. We propose CastDet, a CLIP-activated student-teacher detection framework that serves as the first OVAD detector specifically designed for the challenging aerial scenario, where objects often exhibit weak appearance features and arbitrary orientations. Our framework integrates a robust localization teacher along with several box selection strategies to generate high-quality proposals for novel objects. Additionally, the RemoteCLIP model is adopted as an omniscient teacher, which provides rich knowledge to enhance classification capabilities for novel categories. A dynamic label queue is devised to maintain high-quality pseudo-labels during training. By doing so, the proposed CastDet boosts not only novel object proposals but also classification. Furthermore, we extend our approach from horizontal OVAD to oriented OVAD with tailored algorithm designs to effectively manage bounding box representation and pseudo-label generation. Extensive experiments for both tasks on multiple existing aerial object detection datasets demonstrate the effectiveness of our approach. The code is available at https://github.com/lizzy8587/CastDet.