 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContribution-aware Token Compression for Efficient Video Understanding via Reinforcement Learning
Feb 02, 2026Video large language models have demonstrated remarkable capabilities in video understanding tasks. However, the redundancy of video tokens introduces significant computational overhead during inference, limiting their practical deployment. Many compression algorithms are proposed to prioritize retaining features with the highest attention scores to minimize perturbations in attention computations. However, the correlation between attention scores and their actual contribution to correct answers remains ambiguous. To address the above limitation, we propose a novel \textbf{C}ontribution-\textbf{a}ware token \textbf{Co}mpression algorithm for \textbf{VID}eo understanding (\textbf{CaCoVID}) that explicitly optimizes the token selection policy based on the contribution of tokens to correct predictions. First, we introduce a reinforcement learning-based framework that optimizes a policy network to select video token combinations with the greatest contribution to correct predictions. This paradigm shifts the focus from passive token preservation to active discovery of optimal compressed token combinations. Secondly, we propose a combinatorial policy optimization algorithm with online combination space sampling, which dramatically reduces the exploration space for video token combinations and accelerates the convergence speed of policy optimization. Extensive experiments on diverse video understanding benchmarks demonstrate the effectiveness of CaCoVID. Codes will be released.
Unified Thinker: A General Reasoning Modular Core for Image Generation
Jan 06, 2026Despite impressive progress in high-fidelity image synthesis, generative models still struggle with logic-intensive instruction following, exposing a persistent reasoning--execution gap. Meanwhile, closed-source systems (e.g., Nano Banana) have demonstrated strong reasoning-driven image generation, highlighting a substantial gap to current open-source models. We argue that closing this gap requires not merely better visual generators, but executable reasoning: decomposing high-level intents into grounded, verifiable plans that directly steer the generative process. To this end, we propose Unified Thinker, a task-agnostic reasoning architecture for general image generation, designed as a unified planning core that can plug into diverse generators and workflows. Unified Thinker decouples a dedicated Thinker from the image Generator, enabling modular upgrades of reasoning without retraining the entire generative model. We further introduce a two-stage training paradigm: we first build a structured planning interface for the Thinker, then apply reinforcement learning to ground its policy in pixel-level feedback, encouraging plans that optimize visual correctness over textual plausibility. Extensive experiments on text-to-image generation and image editing show that Unified Thinker substantially improves image reasoning and generation quality.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
MMG-Vid: Maximizing Marginal Gains at Segment-level and Token-level for Efficient Video LLMs
Aug 28, 2025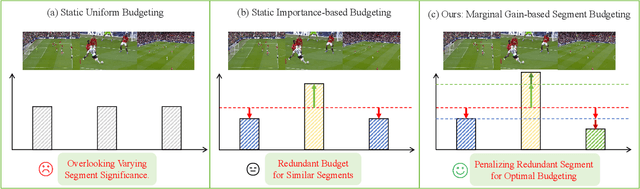
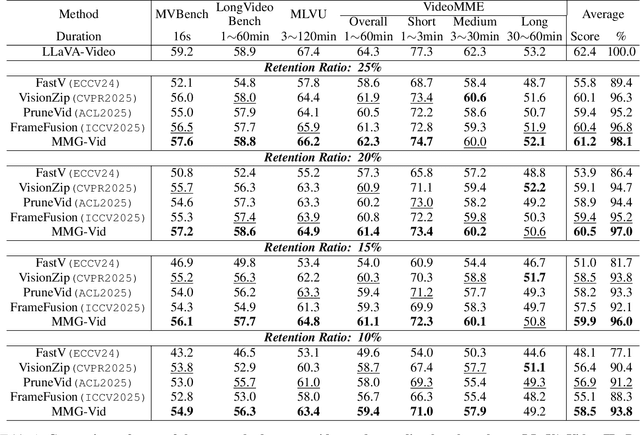
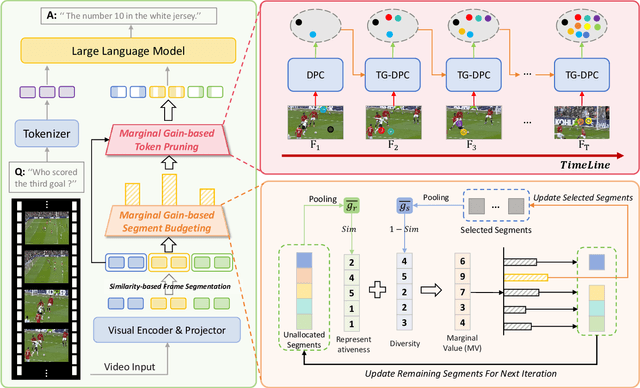
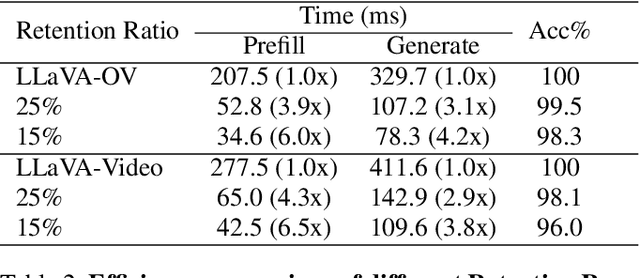
Video Large Language Models (VLLMs) excel in video understanding, but their excessive visual tokens pose a significant computational challenge for real-world applications. Current methods aim to enhance inference efficiency by visual token pruning. However, they do not consider the dynamic characteristics and temporal dependencies of video frames, as they perceive video understanding as a multi-frame task. To address these challenges, we propose MMG-Vid, a novel training-free visual token pruning framework that removes redundancy by Maximizing Marginal Gains at both segment-level and token-level. Specifically, we first divide the video into segments based on frame similarity, and then dynamically allocate the token budget for each segment to maximize the marginal gain of each segment. Subsequently, we propose a temporal-guided DPC algorithm that jointly models inter-frame uniqueness and intra-frame diversity, thereby maximizing the marginal gain of each token. By combining both stages, MMG-Vid can maximize the utilization of the limited token budget, significantly improving efficiency while maintaining strong performance. Extensive experiments demonstrate that MMG-Vid can maintain over 99.5% of the original performance, while effectively reducing 75% visual tokens and accelerating the prefilling stage by 3.9x on LLaVA-OneVision-7B. Code will be released soon.
Active management of battery degradation in wireless sensor network using deep reinforcement learning for group battery replacement
Mar 20, 2025



Wireless sensor networks (WSNs) have become a promising solution for structural health monitoring (SHM), especially in hard-to-reach or remote locations. Battery-powered WSNs offer various advantages over wired systems, however limited battery life has always been one of the biggest obstacles in practical use of the WSNs, regardless of energy harvesting methods. While various methods have been studied for battery health management, existing methods exclusively aim to extend lifetime of individual batteries, lacking a system level view. A consequence of applying such methods is that batteries in a WSN tend to fail at different times, posing significant difficulty on planning and scheduling of battery replacement trip. This study investigate a deep reinforcement learning (DRL) method for active battery degradation management by optimizing duty cycle of WSNs at the system level. This active management strategy effectively reduces earlier failure of battery individuals which enable group replacement without sacrificing WSN performances. A simulated environment based on a real-world WSN setup was developed to train a DRL agent and learn optimal duty cycle strategies. The performance of the strategy was validated in a long-term setup with various network sizes, demonstrating its efficiency and scalability.
EmpathyAgent: Can Embodied Agents Conduct Empathetic Actions?
Mar 19, 2025Empathy is fundamental to human interactions, yet it remains unclear whether embodied agents can provide human-like empathetic support. Existing works have studied agents' tasks solving and social interactions abilities, but whether agents can understand empathetic needs and conduct empathetic behaviors remains overlooked. To address this, we introduce EmpathyAgent, the first benchmark to evaluate and enhance agents' empathetic actions across diverse scenarios. EmpathyAgent contains 10,000 multimodal samples with corresponding empathetic task plans and three different challenges. To systematically evaluate the agents' empathetic actions, we propose an empathy-specific evaluation suite that evaluates the agents' empathy process. We benchmark current models and found that exhibiting empathetic actions remains a significant challenge. Meanwhile, we train Llama3-8B using EmpathyAgent and find it can potentially enhance empathetic behavior. By establishing a standard benchmark for evaluating empathetic actions, we hope to advance research in empathetic embodied agents. Our code and data are publicly available at https://github.com/xinyan-cxy/EmpathyAgent.
Raccoon: Multi-stage Diffusion Training with Coarse-to-Fine Curating Videos
Feb 28, 2025


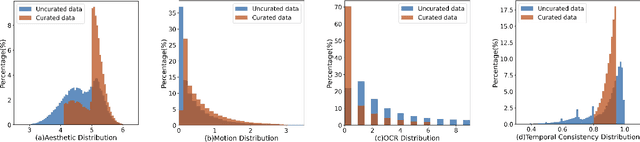
Text-to-video generation has demonstrated promising progress with the advent of diffusion models, yet existing approaches are limited by dataset quality and computational resources. To address these limitations, this paper presents a comprehensive approach that advances both data curation and model design. We introduce CFC-VIDS-1M, a high-quality video dataset constructed through a systematic coarse-to-fine curation pipeline. The pipeline first evaluates video quality across multiple dimensions, followed by a fine-grained stage that leverages vision-language models to enhance text-video alignment and semantic richness. Building upon the curated dataset's emphasis on visual quality and temporal coherence, we develop RACCOON, a transformer-based architecture with decoupled spatial-temporal attention mechanisms. The model is trained through a progressive four-stage strategy designed to efficiently handle the complexities of video generation. Extensive experiments demonstrate that our integrated approach of high-quality data curation and efficient training strategy generates visually appealing and temporally coherent videos while maintaining computational efficiency. We will release our dataset, code, and models.
Neural Directed Speech Enhancement with Dual Microphone Array in High Noise Scenario
Dec 24, 2024



In multi-speaker scenarios, leveraging spatial features is essential for enhancing target speech. While with limited microphone arrays, developing a compact multi-channel speech enhancement system remains challenging, especially in extremely low signal-to-noise ratio (SNR) conditions. To tackle this issue, we propose a triple-steering spatial selection method, a flexible framework that uses three steering vectors to guide enhancement and determine the enhancement range. Specifically, we introduce a causal-directed U-Net (CDUNet) model, which takes raw multi-channel speech and the desired enhancement width as inputs. This enables dynamic adjustment of steering vectors based on the target direction and fine-tuning of the enhancement region according to the angular separation between the target and interference signals. Our model with only a dual microphone array, excels in both speech quality and downstream task performance. It operates in real-time with minimal parameters, making it ideal for low-latency, on-device streaming applications.
DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis
Dec 16, 2024
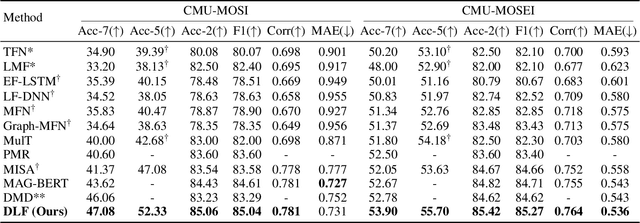
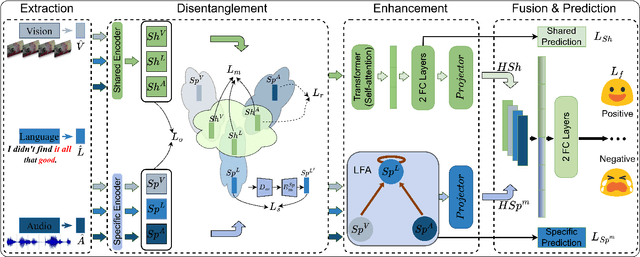
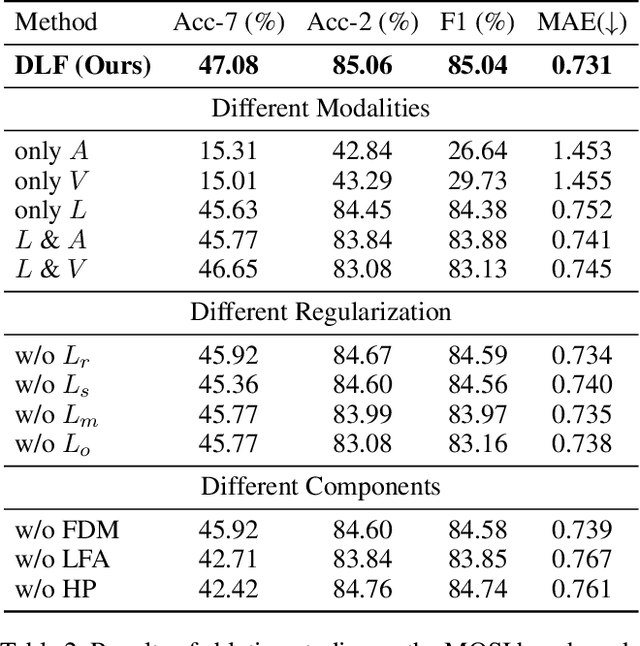
Multimodal Sentiment Analysis (MSA) leverages heterogeneous modalities, such as language, vision, and audio, to enhance the understanding of human sentiment. While existing models often focus on extracting shared information across modalities or directly fusing heterogeneous modalities, such approaches can introduce redundancy and conflicts due to equal treatment of all modalities and the mutual transfer of information between modality pairs. To address these issues, we propose a Disentangled-Language-Focused (DLF) multimodal representation learning framework, which incorporates a feature disentanglement module to separate modality-shared and modality-specific information. To further reduce redundancy and enhance language-targeted features, four geometric measures are introduced to refine the disentanglement process. A Language-Focused Attractor (LFA) is further developed to strengthen language representation by leveraging complementary modality-specific information through a language-guided cross-attention mechanism. The framework also employs hierarchical predictions to improve overall accuracy. Extensive experiments on two popular MSA datasets, CMU-MOSI and CMU-MOSEI, demonstrate the significant performance gains achieved by the proposed DLF framework. Comprehensive ablation studies further validate the effectiveness of the feature disentanglement module, language-focused attractor, and hierarchical predictions. Our code is available at https://github.com/pwang322/DLF.