 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIR-CoT: Towards Interpretable Composed Image Retrieval via End-to-End Chain-of-Thought Reasoning
Oct 09, 2025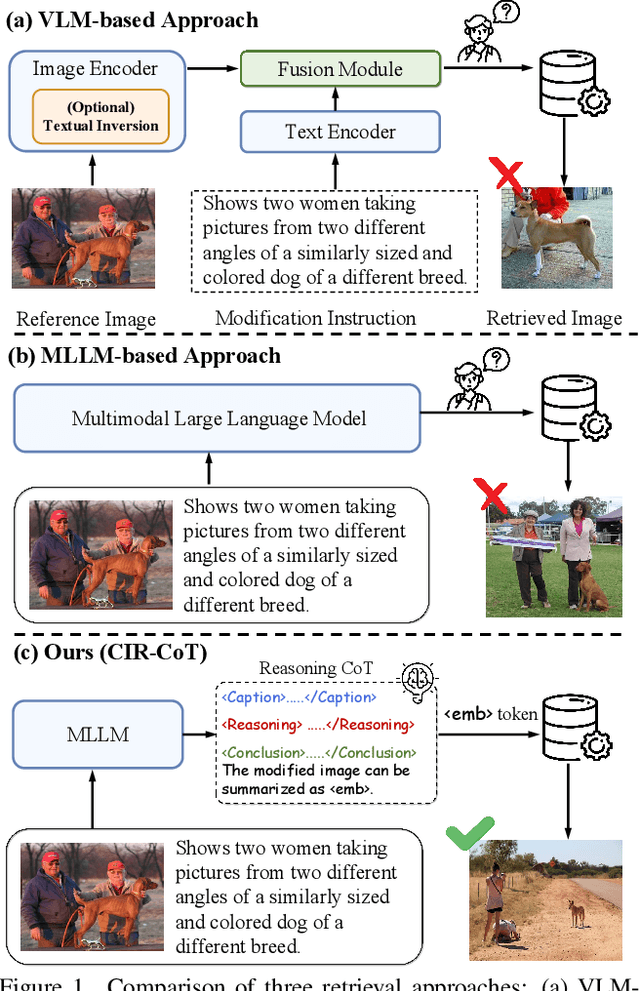
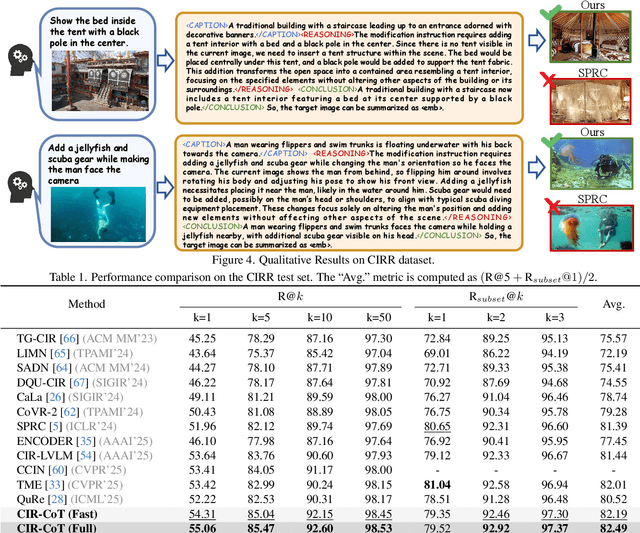
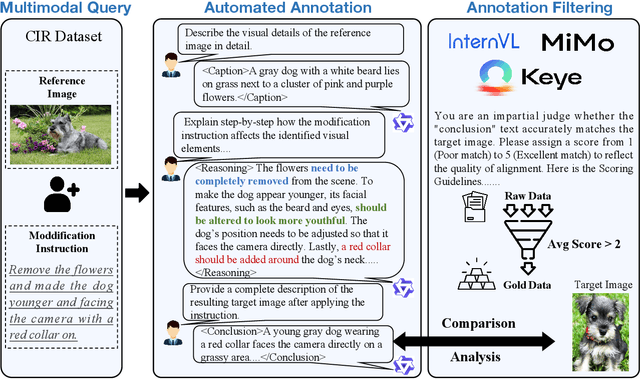
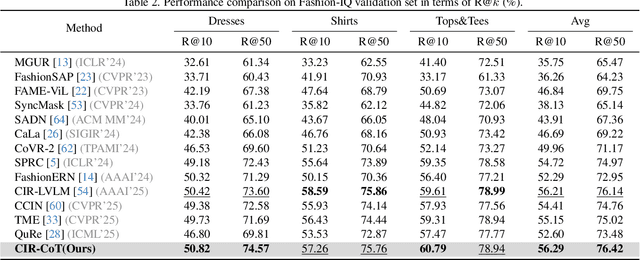
Composed Image Retrieval (CIR), which aims to find a target image from a reference image and a modification text, presents the core challenge of performing unified reasoning across visual and semantic modalities. While current approaches based on Vision-Language Models (VLMs, e.g., CLIP) and more recent Multimodal Large Language Models (MLLMs, e.g., Qwen-VL) have shown progress, they predominantly function as ``black boxes." This inherent opacity not only prevents users from understanding the retrieval rationale but also restricts the models' ability to follow complex, fine-grained instructions. To overcome these limitations, we introduce CIR-CoT, the first end-to-end retrieval-oriented MLLM designed to integrate explicit Chain-of-Thought (CoT) reasoning. By compelling the model to first generate an interpretable reasoning chain, CIR-CoT enhances its ability to capture crucial cross-modal interactions, leading to more accurate retrieval while making its decision process transparent. Since existing datasets like FashionIQ and CIRR lack the necessary reasoning data, a key contribution of our work is the creation of structured CoT annotations using a three-stage process involving a caption, reasoning, and conclusion. Our model is then fine-tuned to produce this structured output before encoding its final retrieval intent into a dedicated embedding. Comprehensive experiments show that CIR-CoT achieves highly competitive performance on in-domain datasets (FashionIQ, CIRR) and demonstrates remarkable generalization on the out-of-domain CIRCO dataset, establishing a new path toward more effective and trustworthy retrieval systems.
I2EBench: A Comprehensive Benchmark for Instruction-based Image Editing
Aug 26, 2024



Significant progress has been made in the field of Instruction-based Image Editing (IIE). However, evaluating these models poses a significant challenge. A crucial requirement in this field is the establishment of a comprehensive evaluation benchmark for accurately assessing editing results and providing valuable insights for its further development. In response to this need, we propose I2EBench, a comprehensive benchmark designed to automatically evaluate the quality of edited images produced by IIE models from multiple dimensions. I2EBench consists of 2,000+ images for editing, along with 4,000+ corresponding original and diverse instructions. It offers three distinctive characteristics: 1) Comprehensive Evaluation Dimensions: I2EBench comprises 16 evaluation dimensions that cover both high-level and low-level aspects, providing a comprehensive assessment of each IIE model. 2) Human Perception Alignment: To ensure the alignment of our benchmark with human perception, we conducted an extensive user study for each evaluation dimension. 3) Valuable Research Insights: By analyzing the advantages and disadvantages of existing IIE models across the 16 dimensions, we offer valuable research insights to guide future development in the field. We will open-source I2EBench, including all instructions, input images, human annotations, edited images from all evaluated methods, and a simple script for evaluating the results from new IIE models. The code, dataset and generated images from all IIE models are provided in github: https://github.com/cocoshe/I2EBench.
INF-LLaVA: Dual-perspective Perception for High-Resolution Multimodal Large Language Model
Jul 23, 2024With advancements in data availability and computing resources, Multimodal Large Language Models (MLLMs) have showcased capabilities across various fields. However, the quadratic complexity of the vision encoder in MLLMs constrains the resolution of input images. Most current approaches mitigate this issue by cropping high-resolution images into smaller sub-images, which are then processed independently by the vision encoder. Despite capturing sufficient local details, these sub-images lack global context and fail to interact with one another. To address this limitation, we propose a novel MLLM, INF-LLaVA, designed for effective high-resolution image perception. INF-LLaVA incorporates two innovative components. First, we introduce a Dual-perspective Cropping Module (DCM), which ensures that each sub-image contains continuous details from a local perspective and comprehensive information from a global perspective. Second, we introduce Dual-perspective Enhancement Module (DEM) to enable the mutual enhancement of global and local features, allowing INF-LLaVA to effectively process high-resolution images by simultaneously capturing detailed local information and comprehensive global context. Extensive ablation studies validate the effectiveness of these components, and experiments on a diverse set of benchmarks demonstrate that INF-LLaVA outperforms existing MLLMs. Code and pretrained model are available at https://github.com/WeihuangLin/INF-LLaVA.