 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSMCIR: CoT-Enhanced Symmetric Alignment with Memory Bank for Composed Image Retrieval
Jan 07, 2026Composed Image Retrieval (CIR) enables users to search for target images using both a reference image and manipulation text, offering substantial advantages over single-modality retrieval systems. However, existing CIR methods suffer from representation space fragmentation: queries and targets comprise heterogeneous modalities and are processed by distinct encoders, forcing models to bridge misaligned representation spaces only through post-hoc alignment, which fundamentally limits retrieval performance. This architectural asymmetry manifests as three distinct, well-separated clusters in the feature space, directly demonstrating how heterogeneous modalities create fundamentally misaligned representation spaces from initialization. In this work, we propose CSMCIR, a unified representation framework that achieves efficient query-target alignment through three synergistic components. First, we introduce a Multi-level Chain-of-Thought (MCoT) prompting strategy that guides Multimodal Large Language Models to generate discriminative, semantically compatible captions for target images, establishing modal symmetry. Building upon this, we design a symmetric dual-tower architecture where both query and target sides utilize the identical shared-parameter Q-Former for cross-modal encoding, ensuring consistent feature representations and further reducing the alignment gap. Finally, this architectural symmetry enables an entropy-based, temporally dynamic Memory Bank strategy that provides high-quality negative samples while maintaining consistency with the evolving model state. Extensive experiments on four benchmark datasets demonstrate that our CSMCIR achieves state-of-the-art performance with superior training efficiency. Comprehensive ablation studies further validate the effectiveness of each proposed component.
CIR-CoT: Towards Interpretable Composed Image Retrieval via End-to-End Chain-of-Thought Reasoning
Oct 09, 2025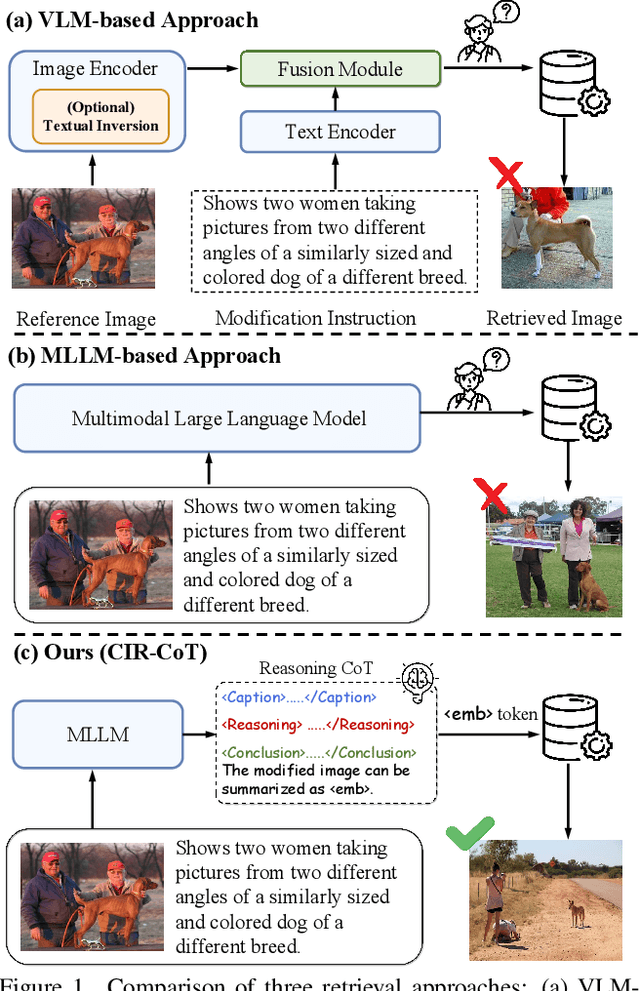
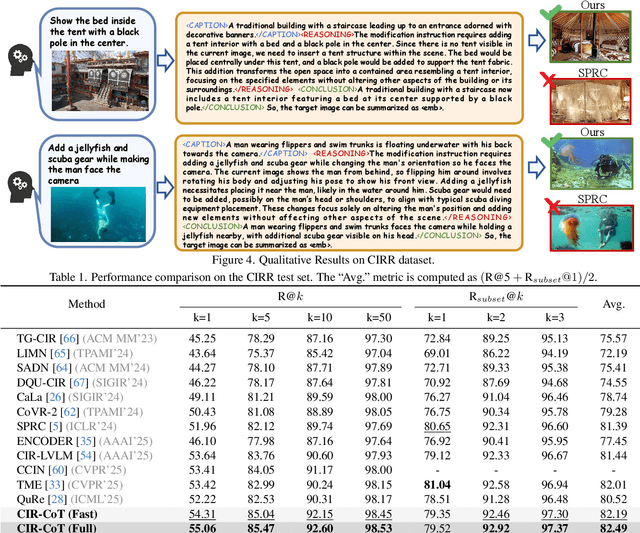
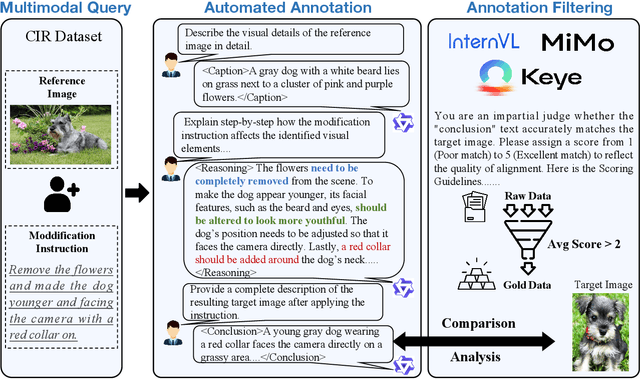
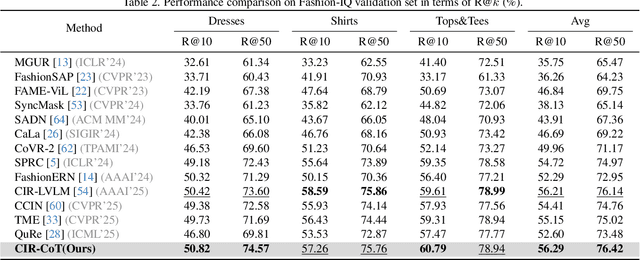
Composed Image Retrieval (CIR), which aims to find a target image from a reference image and a modification text, presents the core challenge of performing unified reasoning across visual and semantic modalities. While current approaches based on Vision-Language Models (VLMs, e.g., CLIP) and more recent Multimodal Large Language Models (MLLMs, e.g., Qwen-VL) have shown progress, they predominantly function as ``black boxes." This inherent opacity not only prevents users from understanding the retrieval rationale but also restricts the models' ability to follow complex, fine-grained instructions. To overcome these limitations, we introduce CIR-CoT, the first end-to-end retrieval-oriented MLLM designed to integrate explicit Chain-of-Thought (CoT) reasoning. By compelling the model to first generate an interpretable reasoning chain, CIR-CoT enhances its ability to capture crucial cross-modal interactions, leading to more accurate retrieval while making its decision process transparent. Since existing datasets like FashionIQ and CIRR lack the necessary reasoning data, a key contribution of our work is the creation of structured CoT annotations using a three-stage process involving a caption, reasoning, and conclusion. Our model is then fine-tuned to produce this structured output before encoding its final retrieval intent into a dedicated embedding. Comprehensive experiments show that CIR-CoT achieves highly competitive performance on in-domain datasets (FashionIQ, CIRR) and demonstrates remarkable generalization on the out-of-domain CIRCO dataset, establishing a new path toward more effective and trustworthy retrieval systems.
Zooming In on Fakes: A Novel Dataset for Localized AI-Generated Image Detection with Forgery Amplification Approach
Apr 16, 2025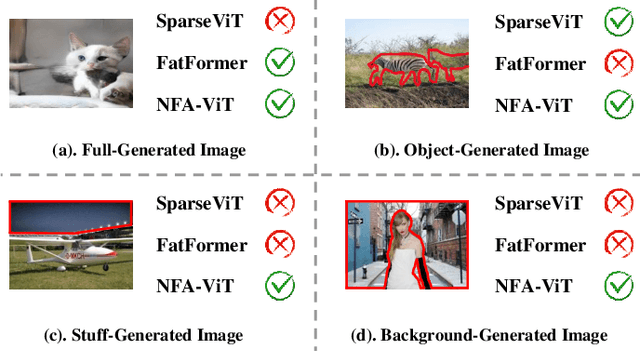
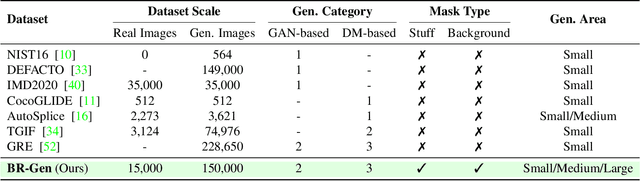
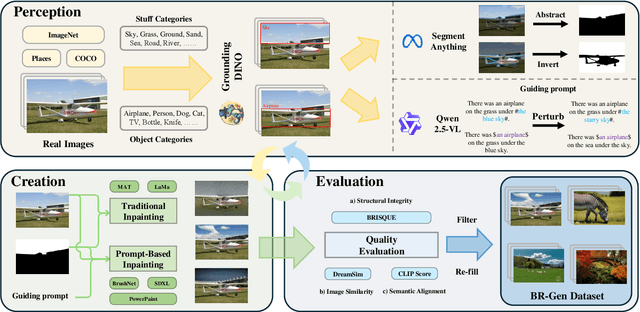
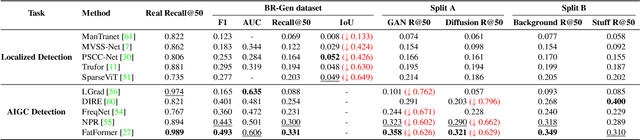
The rise of AI-generated image editing tools has made localized forgeries increasingly realistic, posing challenges for visual content integrity. Although recent efforts have explored localized AIGC detection, existing datasets predominantly focus on object-level forgeries while overlooking broader scene edits in regions such as sky or ground. To address these limitations, we introduce \textbf{BR-Gen}, a large-scale dataset of 150,000 locally forged images with diverse scene-aware annotations, which are based on semantic calibration to ensure high-quality samples. BR-Gen is constructed through a fully automated Perception-Creation-Evaluation pipeline to ensure semantic coherence and visual realism. In addition, we further propose \textbf{NFA-ViT}, a Noise-guided Forgery Amplification Vision Transformer that enhances the detection of localized forgeries by amplifying forgery-related features across the entire image. NFA-ViT mines heterogeneous regions in images, \emph{i.e.}, potential edited areas, by noise fingerprints. Subsequently, attention mechanism is introduced to compel the interaction between normal and abnormal features, thereby propagating the generalization traces throughout the entire image, allowing subtle forgeries to influence a broader context and improving overall detection robustness. Extensive experiments demonstrate that BR-Gen constructs entirely new scenarios that are not covered by existing methods. Take a step further, NFA-ViT outperforms existing methods on BR-Gen and generalizes well across current benchmarks. All data and codes are available at https://github.com/clpbc/BR-Gen.
MLLM-Selector: Necessity and Diversity-driven High-Value Data Selection for Enhanced Visual Instruction Tuning
Mar 26, 2025Visual instruction tuning (VIT) has emerged as a crucial technique for enabling multi-modal large language models (MLLMs) to follow user instructions adeptly. Yet, a significant gap persists in understanding the attributes of high-quality instruction tuning data and frameworks for its automated selection. To address this, we introduce MLLM-Selector, an automated approach that identifies valuable data for VIT by weighing necessity and diversity. Our process starts by randomly sampling a subset from the VIT data pool to fine-tune a pretrained model, thus creating a seed model with an initial ability to follow instructions. Then, leveraging the seed model, we calculate necessity scores for each sample in the VIT data pool to identify samples pivotal for enhancing model performance. Our findings underscore the importance of mixing necessity and diversity in data choice, leading to the creation of MLLM-Selector, our methodology that fuses necessity scoring with strategic sampling for superior data refinement. Empirical results indicate that within identical experimental conditions, MLLM-Selector surpasses LLaVA-1.5 in some benchmarks with less than 1% of the data and consistently exceeds performance across all validated benchmarks when using less than 50%.
IPDN: Image-enhanced Prompt Decoding Network for 3D Referring Expression Segmentation
Jan 09, 2025



3D Referring Expression Segmentation (3D-RES) aims to segment point cloud scenes based on a given expression. However, existing 3D-RES approaches face two major challenges: feature ambiguity and intent ambiguity. Feature ambiguity arises from information loss or distortion during point cloud acquisition due to limitations such as lighting and viewpoint. Intent ambiguity refers to the model's equal treatment of all queries during the decoding process, lacking top-down task-specific guidance. In this paper, we introduce an Image enhanced Prompt Decoding Network (IPDN), which leverages multi-view images and task-driven information to enhance the model's reasoning capabilities. To address feature ambiguity, we propose the Multi-view Semantic Embedding (MSE) module, which injects multi-view 2D image information into the 3D scene and compensates for potential spatial information loss. To tackle intent ambiguity, we designed a Prompt-Aware Decoder (PAD) that guides the decoding process by deriving task-driven signals from the interaction between the expression and visual features. Comprehensive experiments demonstrate that IPDN outperforms the state-ofthe-art by 1.9 and 4.2 points in mIoU metrics on the 3D-RES and 3D-GRES tasks, respectively.
RG-SAN: Rule-Guided Spatial Awareness Network for End-to-End 3D Referring Expression Segmentation
Dec 03, 2024



3D Referring Expression Segmentation (3D-RES) aims to segment 3D objects by correlating referring expressions with point clouds. However, traditional approaches frequently encounter issues like over-segmentation or mis-segmentation, due to insufficient emphasis on spatial information of instances. In this paper, we introduce a Rule-Guided Spatial Awareness Network (RG-SAN) by utilizing solely the spatial information of the target instance for supervision. This approach enables the network to accurately depict the spatial relationships among all entities described in the text, thus enhancing the reasoning capabilities. The RG-SAN consists of the Text-driven Localization Module (TLM) and the Rule-guided Weak Supervision (RWS) strategy. The TLM initially locates all mentioned instances and iteratively refines their positional information. The RWS strategy, acknowledging that only target objects have supervised positional information, employs dependency tree rules to precisely guide the core instance's positioning. Extensive testing on the ScanRefer benchmark has shown that RG-SAN not only establishes new performance benchmarks, with an mIoU increase of 5.1 points, but also exhibits significant improvements in robustness when processing descriptions with spatial ambiguity. All codes are available at https://github.com/sosppxo/RG-SAN.
Any-to-3D Generation via Hybrid Diffusion Supervision
Nov 22, 2024



Recent progress in 3D object generation has been fueled by the strong priors offered by diffusion models. However, existing models are tailored to specific tasks, accommodating only one modality at a time and necessitating retraining to change modalities. Given an image-to-3D model and a text prompt, a naive approach is to convert text prompts to images and then use the image-to-3D model for generation. This approach is both time-consuming and labor-intensive, resulting in unavoidable information loss during modality conversion. To address this, we introduce XBind, a unified framework for any-to-3D generation using cross-modal pre-alignment techniques. XBind integrates an multimodal-aligned encoder with pre-trained diffusion models to generate 3D objects from any modalities, including text, images, and audio. We subsequently present a novel loss function, termed Modality Similarity (MS) Loss, which aligns the embeddings of the modality prompts and the rendered images, facilitating improved alignment of the 3D objects with multiple modalities. Additionally, Hybrid Diffusion Supervision combined with a Three-Phase Optimization process improves the quality of the generated 3D objects. Extensive experiments showcase XBind's broad generation capabilities in any-to-3D scenarios. To our knowledge, this is the first method to generate 3D objects from any modality prompts. Project page: https://zeroooooooow1440.github.io/.
I2EBench: A Comprehensive Benchmark for Instruction-based Image Editing
Aug 26, 2024



Significant progress has been made in the field of Instruction-based Image Editing (IIE). However, evaluating these models poses a significant challenge. A crucial requirement in this field is the establishment of a comprehensive evaluation benchmark for accurately assessing editing results and providing valuable insights for its further development. In response to this need, we propose I2EBench, a comprehensive benchmark designed to automatically evaluate the quality of edited images produced by IIE models from multiple dimensions. I2EBench consists of 2,000+ images for editing, along with 4,000+ corresponding original and diverse instructions. It offers three distinctive characteristics: 1) Comprehensive Evaluation Dimensions: I2EBench comprises 16 evaluation dimensions that cover both high-level and low-level aspects, providing a comprehensive assessment of each IIE model. 2) Human Perception Alignment: To ensure the alignment of our benchmark with human perception, we conducted an extensive user study for each evaluation dimension. 3) Valuable Research Insights: By analyzing the advantages and disadvantages of existing IIE models across the 16 dimensions, we offer valuable research insights to guide future development in the field. We will open-source I2EBench, including all instructions, input images, human annotations, edited images from all evaluated methods, and a simple script for evaluating the results from new IIE models. The code, dataset and generated images from all IIE models are provided in github: https://github.com/cocoshe/I2EBench.
3D-GRES: Generalized 3D Referring Expression Segmentation
Jul 31, 2024


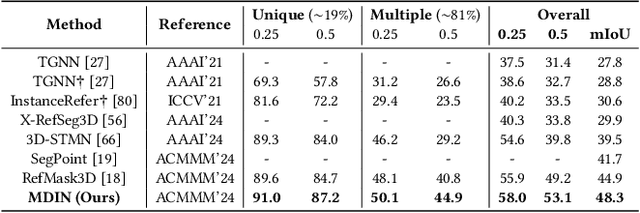
3D Referring Expression Segmentation (3D-RES) is dedicated to segmenting a specific instance within a 3D space based on a natural language description. However, current approaches are limited to segmenting a single target, restricting the versatility of the task. To overcome this limitation, we introduce Generalized 3D Referring Expression Segmentation (3D-GRES), which extends the capability to segment any number of instances based on natural language instructions. In addressing this broader task, we propose the Multi-Query Decoupled Interaction Network (MDIN), designed to break down multi-object segmentation tasks into simpler, individual segmentations. MDIN comprises two fundamental components: Text-driven Sparse Queries (TSQ) and Multi-object Decoupling Optimization (MDO). TSQ generates sparse point cloud features distributed over key targets as the initialization for queries. Meanwhile, MDO is tasked with assigning each target in multi-object scenarios to different queries while maintaining their semantic consistency. To adapt to this new task, we build a new dataset, namely Multi3DRes. Our comprehensive evaluations on this dataset demonstrate substantial enhancements over existing models, thus charting a new path for intricate multi-object 3D scene comprehension. The benchmark and code are available at https://github.com/sosppxo/MDIN.
INF-LLaVA: Dual-perspective Perception for High-Resolution Multimodal Large Language Model
Jul 23, 2024With advancements in data availability and computing resources, Multimodal Large Language Models (MLLMs) have showcased capabilities across various fields. However, the quadratic complexity of the vision encoder in MLLMs constrains the resolution of input images. Most current approaches mitigate this issue by cropping high-resolution images into smaller sub-images, which are then processed independently by the vision encoder. Despite capturing sufficient local details, these sub-images lack global context and fail to interact with one another. To address this limitation, we propose a novel MLLM, INF-LLaVA, designed for effective high-resolution image perception. INF-LLaVA incorporates two innovative components. First, we introduce a Dual-perspective Cropping Module (DCM), which ensures that each sub-image contains continuous details from a local perspective and comprehensive information from a global perspective. Second, we introduce Dual-perspective Enhancement Module (DEM) to enable the mutual enhancement of global and local features, allowing INF-LLaVA to effectively process high-resolution images by simultaneously capturing detailed local information and comprehensive global context. Extensive ablation studies validate the effectiveness of these components, and experiments on a diverse set of benchmarks demonstrate that INF-LLaVA outperforms existing MLLMs. Code and pretrained model are available at https://github.com/WeihuangLin/INF-LLaVA.