 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-to-3D Generation via Hybrid Diffusion Supervision
Nov 22, 2024



Recent progress in 3D object generation has been fueled by the strong priors offered by diffusion models. However, existing models are tailored to specific tasks, accommodating only one modality at a time and necessitating retraining to change modalities. Given an image-to-3D model and a text prompt, a naive approach is to convert text prompts to images and then use the image-to-3D model for generation. This approach is both time-consuming and labor-intensive, resulting in unavoidable information loss during modality conversion. To address this, we introduce XBind, a unified framework for any-to-3D generation using cross-modal pre-alignment techniques. XBind integrates an multimodal-aligned encoder with pre-trained diffusion models to generate 3D objects from any modalities, including text, images, and audio. We subsequently present a novel loss function, termed Modality Similarity (MS) Loss, which aligns the embeddings of the modality prompts and the rendered images, facilitating improved alignment of the 3D objects with multiple modalities. Additionally, Hybrid Diffusion Supervision combined with a Three-Phase Optimization process improves the quality of the generated 3D objects. Extensive experiments showcase XBind's broad generation capabilities in any-to-3D scenarios. To our knowledge, this is the first method to generate 3D objects from any modality prompts. Project page: https://zeroooooooow1440.github.io/.
X-Oscar: A Progressive Framework for High-quality Text-guided 3D Animatable Avatar Generation
May 02, 2024



Recent advancements in automatic 3D avatar generation guided by text have made significant progress. However, existing methods have limitations such as oversaturation and low-quality output. To address these challenges, we propose X-Oscar, a progressive framework for generating high-quality animatable avatars from text prompts. It follows a sequential Geometry->Texture->Animation paradigm, simplifying optimization through step-by-step generation. To tackle oversaturation, we introduce Adaptive Variational Parameter (AVP), representing avatars as an adaptive distribution during training. Additionally, we present Avatar-aware Score Distillation Sampling (ASDS), a novel technique that incorporates avatar-aware noise into rendered images for improved generation quality during optimization. Extensive evaluations confirm the superiority of X-Oscar over existing text-to-3D and text-to-avatar approaches. Our anonymous project page: https://xmu-xiaoma666.github.io/Projects/X-Oscar/.
X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
Nov 30, 2023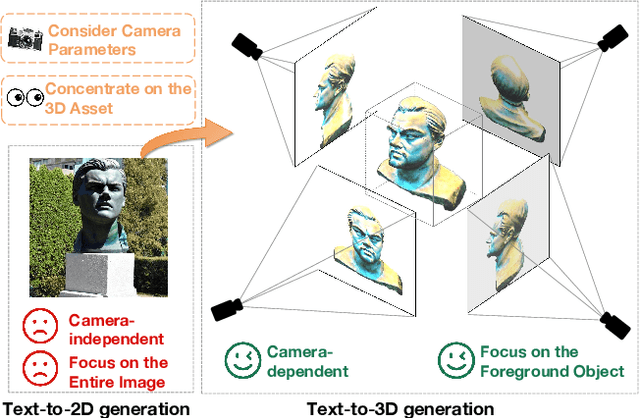

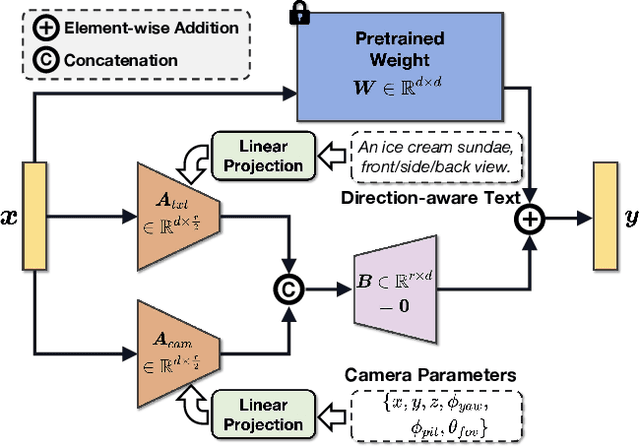

In recent times, automatic text-to-3D content creation has made significant progress, driven by the development of pretrained 2D diffusion models. Existing text-to-3D methods typically optimize the 3D representation to ensure that the rendered image aligns well with the given text, as evaluated by the pretrained 2D diffusion model. Nevertheless, a substantial domain gap exists between 2D images and 3D assets, primarily attributed to variations in camera-related attributes and the exclusive presence of foreground objects. Consequently, employing 2D diffusion models directly for optimizing 3D representations may lead to suboptimal outcomes. To address this issue, we present X-Dreamer, a novel approach for high-quality text-to-3D content creation that effectively bridges the gap between text-to-2D and text-to-3D synthesis. The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) Loss. CG-LoRA dynamically incorporates camera information into the pretrained diffusion models by employing camera-dependent generation for trainable parameters. This integration enhances the alignment between the generated 3D assets and the camera's perspective. AMA loss guides the attention map of the pretrained diffusion model using the binary mask of the 3D object, prioritizing the creation of the foreground object. This module ensures that the model focuses on generating accurate and detailed foreground objects. Extensive evaluations demonstrate the effectiveness of our proposed method compared to existing text-to-3D approaches. Our project webpage: https://xmuxiaoma666.github.io/Projects/X-Dreamer .