 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
Nov 30, 2023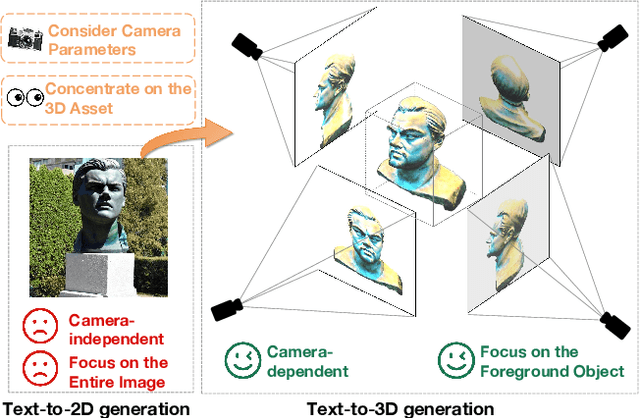

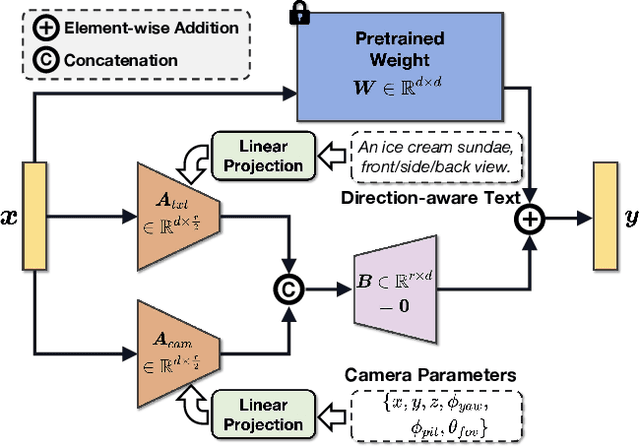

In recent times, automatic text-to-3D content creation has made significant progress, driven by the development of pretrained 2D diffusion models. Existing text-to-3D methods typically optimize the 3D representation to ensure that the rendered image aligns well with the given text, as evaluated by the pretrained 2D diffusion model. Nevertheless, a substantial domain gap exists between 2D images and 3D assets, primarily attributed to variations in camera-related attributes and the exclusive presence of foreground objects. Consequently, employing 2D diffusion models directly for optimizing 3D representations may lead to suboptimal outcomes. To address this issue, we present X-Dreamer, a novel approach for high-quality text-to-3D content creation that effectively bridges the gap between text-to-2D and text-to-3D synthesis. The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) Loss. CG-LoRA dynamically incorporates camera information into the pretrained diffusion models by employing camera-dependent generation for trainable parameters. This integration enhances the alignment between the generated 3D assets and the camera's perspective. AMA loss guides the attention map of the pretrained diffusion model using the binary mask of the 3D object, prioritizing the creation of the foreground object. This module ensures that the model focuses on generating accurate and detailed foreground objects. Extensive evaluations demonstrate the effectiveness of our proposed method compared to existing text-to-3D approaches. Our project webpage: https://xmuxiaoma666.github.io/Projects/X-Dreamer .
Pseudo-label Alignment for Semi-supervised Instance Segmentation
Aug 10, 2023Pseudo-labeling is significant for semi-supervised instance segmentation, which generates instance masks and classes from unannotated images for subsequent training. However, in existing pipelines, pseudo-labels that contain valuable information may be directly filtered out due to mismatches in class and mask quality. To address this issue, we propose a novel framework, called pseudo-label aligning instance segmentation (PAIS), in this paper. In PAIS, we devise a dynamic aligning loss (DALoss) that adjusts the weights of semi-supervised loss terms with varying class and mask score pairs. Through extensive experiments conducted on the COCO and Cityscapes datasets, we demonstrate that PAIS is a promising framework for semi-supervised instance segmentation, particularly in cases where labeled data is severely limited. Notably, with just 1\% labeled data, PAIS achieves 21.2 mAP (based on Mask-RCNN) and 19.9 mAP (based on K-Net) on the COCO dataset, outperforming the current state-of-the-art model, \ie, NoisyBoundary with 7.7 mAP, by a margin of over 12 points. Code is available at: \url{https://github.com/hujiecpp/PAIS}.
Approximated Prompt Tuning for Vision-Language Pre-trained Models
Jun 27, 2023



Prompt tuning is a parameter-efficient way to deploy large-scale pre-trained models to downstream tasks by adding task-specific tokens. In terms of vision-language pre-trained (VLP) models, prompt tuning often requires a large number of learnable tokens to bridge the gap between the pre-training and downstream tasks, which greatly exacerbates the already high computational overhead. In this paper, we revisit the principle of prompt tuning for Transformer-based VLP models and reveal that the impact of soft prompt tokens can be actually approximated via independent information diffusion steps, thereby avoiding the expensive global attention modeling and reducing the computational complexity to a large extent. Based on this finding, we propose a novel Approximated Prompt Tuning (APT) approach towards efficient VL transfer learning. To validate APT, we apply it to two representative VLP models, namely ViLT and METER, and conduct extensive experiments on a bunch of downstream tasks. Meanwhile, the generalization of APT is also validated on CLIP for image classification. The experimental results not only show the superior performance gains and computation efficiency of APT against the conventional prompt tuning methods, e.g., +6.6% accuracy and -64.62% additional computation overhead on METER, but also confirm its merits over other parameter-efficient transfer learning approaches.