 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Restore Multi-Degraded Images via Ingredient Decoupling and Task-Aware Path Adaptation
Nov 07, 2025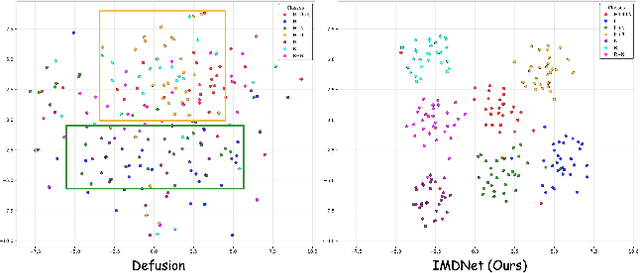
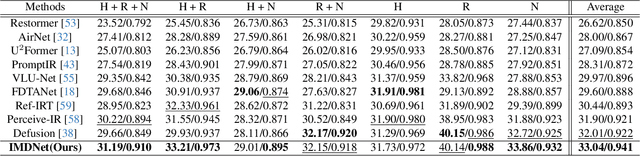
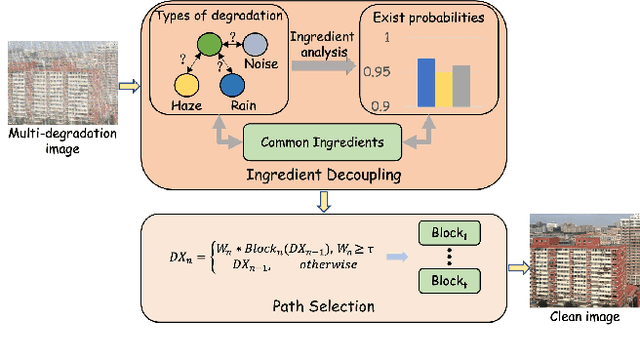
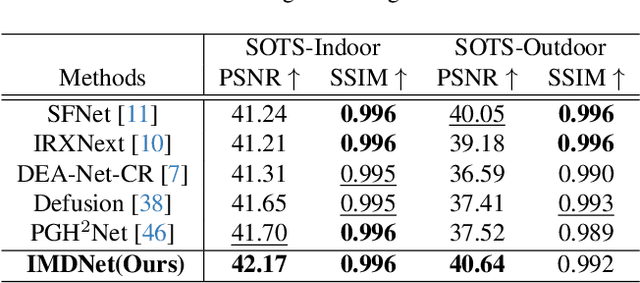
Image restoration (IR) aims to recover clean images from degraded observations. Despite remarkable progress, most existing methods focus on a single degradation type, whereas real-world images often suffer from multiple coexisting degradations, such as rain, noise, and haze coexisting in a single image, which limits their practical effectiveness. In this paper, we propose an adaptive multi-degradation image restoration network that reconstructs images by leveraging decoupled representations of degradation ingredients to guide path selection. Specifically, we design a degradation ingredient decoupling block (DIDBlock) in the encoder to separate degradation ingredients statistically by integrating spatial and frequency domain information, enhancing the recognition of multiple degradation types and making their feature representations independent. In addition, we present fusion block (FBlock) to integrate degradation information across all levels using learnable matrices. In the decoder, we further introduce a task adaptation block (TABlock) that dynamically activates or fuses functional branches based on the multi-degradation representation, flexibly selecting optimal restoration paths under diverse degradation conditions. The resulting tightly integrated architecture, termed IMDNet, is extensively validated through experiments, showing superior performance on multi-degradation restoration while maintaining strong competitiveness on single-degradation tasks.
ASBench: Image Anomalies Synthesis Benchmark for Anomaly Detection
Oct 09, 2025Anomaly detection plays a pivotal role in manufacturing quality control, yet its application is constrained by limited abnormal samples and high manual annotation costs. While anomaly synthesis offers a promising solution, existing studies predominantly treat anomaly synthesis as an auxiliary component within anomaly detection frameworks, lacking systematic evaluation of anomaly synthesis algorithms. Current research also overlook crucial factors specific to anomaly synthesis, such as decoupling its impact from detection, quantitative analysis of synthetic data and adaptability across different scenarios. To address these limitations, we propose ASBench, the first comprehensive benchmarking framework dedicated to evaluating anomaly synthesis methods. Our framework introduces four critical evaluation dimensions: (i) the generalization performance across different datasets and pipelines (ii) the ratio of synthetic to real data (iii) the correlation between intrinsic metrics of synthesis images and anomaly detection performance metrics , and (iv) strategies for hybrid anomaly synthesis methods. Through extensive experiments, ASBench not only reveals limitations in current anomaly synthesis methods but also provides actionable insights for future research directions in anomaly synthesis
Decoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation
May 20, 2025This paper focus on few-shot object detection~(FSOD) and instance segmentation~(FSIS), which requires a model to quickly adapt to novel classes with a few labeled instances. The existing methods severely suffer from bias classification because of the missing label issue which naturally exists in an instance-level few-shot scenario and is first formally proposed by us. Our analysis suggests that the standard classification head of most FSOD or FSIS models needs to be decoupled to mitigate the bias classification. Therefore, we propose an embarrassingly simple but effective method that decouples the standard classifier into two heads. Then, these two individual heads are capable of independently addressing clear positive samples and noisy negative samples which are caused by the missing label. In this way, the model can effectively learn novel classes while mitigating the effects of noisy negative samples. Without bells and whistles, our model without any additional computation cost and parameters consistently outperforms its baseline and state-of-the-art by a large margin on PASCAL VOC and MS-COCO benchmarks for FSOD and FSIS tasks. The Code is available at https://csgaobb.github.io/Projects/DCFS.
A Survey on Industrial Anomalies Synthesis
Feb 23, 2025This paper comprehensively reviews anomaly synthesis methodologies. Existing surveys focus on limited techniques, missing an overall field view and understanding method interconnections. In contrast, our study offers a unified review, covering about 40 representative methods across Hand-crafted, Distribution-hypothesis-based, Generative models (GM)-based, and Vision-language models (VLM)-based synthesis. We introduce the first industrial anomaly synthesis (IAS) taxonomy. Prior works lack formal classification or use simplistic taxonomies, hampering structured comparisons and trend identification. Our taxonomy provides a fine-grained framework reflecting methodological progress and practical implications, grounding future research. Furthermore, we explore cross-modality synthesis and large-scale VLM. Previous surveys overlooked multimodal data and VLM in anomaly synthesis, limiting insights into their advantages. Our survey analyzes their integration, benefits, challenges, and prospects, offering a roadmap to boost IAS with multimodal learning. More resources are available at https://github.com/M-3LAB/awesome-anomaly-synthesis.
CamoTeacher: Dual-Rotation Consistency Learning for Semi-Supervised Camouflaged Object Detection
Aug 15, 2024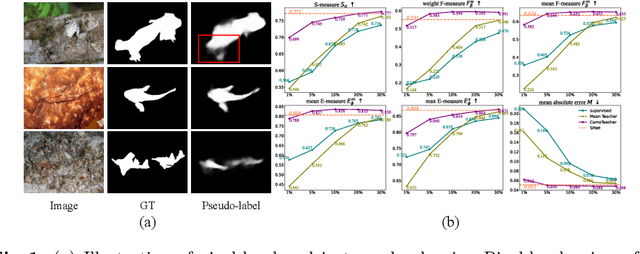
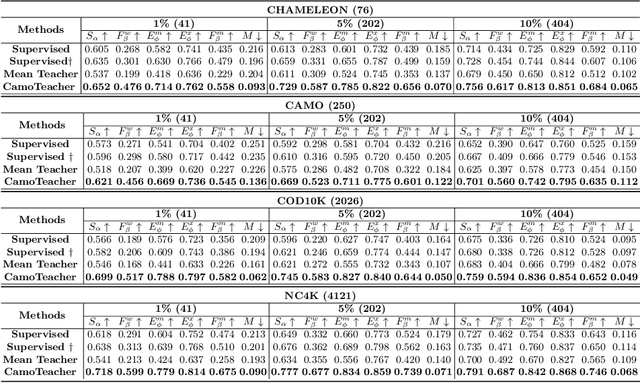
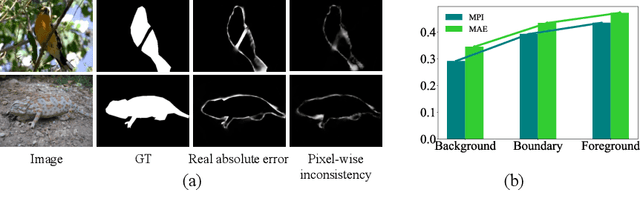
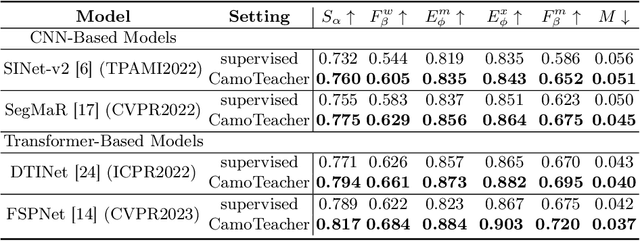
Existing camouflaged object detection~(COD) methods depend heavily on large-scale pixel-level annotations.However, acquiring such annotations is laborious due to the inherent camouflage characteristics of the objects.Semi-supervised learning offers a promising solution to this challenge.Yet, its application in COD is hindered by significant pseudo-label noise, both pixel-level and instance-level.We introduce CamoTeacher, a novel semi-supervised COD framework, utilizing Dual-Rotation Consistency Learning~(DRCL) to effectively address these noise issues.Specifically, DRCL minimizes pseudo-label noise by leveraging rotation views' consistency in pixel-level and instance-level.First, it employs Pixel-wise Consistency Learning~(PCL) to deal with pixel-level noise by reweighting the different parts within the pseudo-label.Second, Instance-wise Consistency Learning~(ICL) is used to adjust weights for pseudo-labels, which handles instance-level noise.Extensive experiments on four COD benchmark datasets demonstrate that the proposed CamoTeacher not only achieves state-of-the-art compared with semi-supervised learning methods, but also rivals established fully-supervised learning methods.Our code will be available soon.
Beat: Bi-directional One-to-Many Embedding Alignment for Text-based Person Retrieval
Jun 09, 2024



Text-based person retrieval (TPR) is a challenging task that involves retrieving a specific individual based on a textual description. Despite considerable efforts to bridge the gap between vision and language, the significant differences between these modalities continue to pose a challenge. Previous methods have attempted to align text and image samples in a modal-shared space, but they face uncertainties in optimization directions due to the movable features of both modalities and the failure to account for one-to-many relationships of image-text pairs in TPR datasets. To address this issue, we propose an effective bi-directional one-to-many embedding paradigm that offers a clear optimization direction for each sample, thus mitigating the optimization problem. Additionally, this embedding scheme generates multiple features for each sample without introducing trainable parameters, making it easier to align with several positive samples. Based on this paradigm, we propose a novel Bi-directional one-to-many Embedding Alignment (Beat) model to address the TPR task. Our experimental results demonstrate that the proposed Beat model achieves state-of-the-art performance on three popular TPR datasets, including CUHK-PEDES (65.61 R@1), ICFG-PEDES (58.25 R@1), and RSTPReID (48.10 R@1). Furthermore, additional experiments on MS-COCO, CUB, and Flowers datasets further demonstrate the potential of Beat to be applied to other image-text retrieval tasks.
FocSAM: Delving Deeply into Focused Objects in Segmenting Anything
May 29, 2024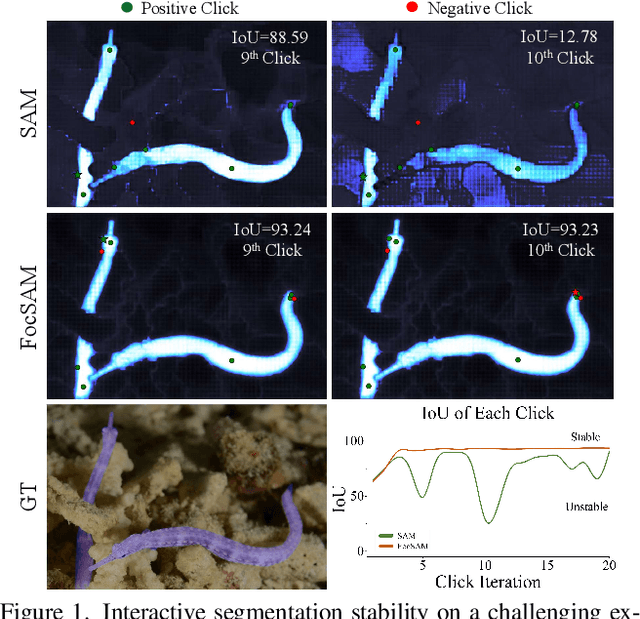
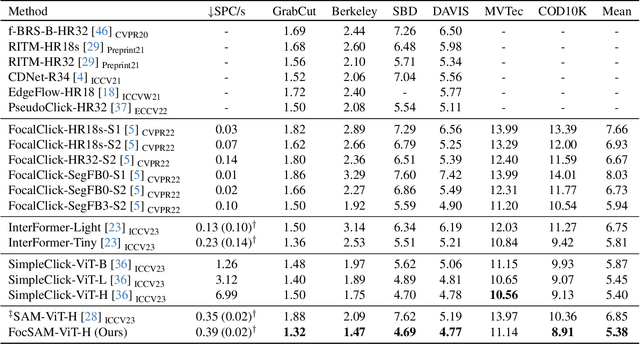
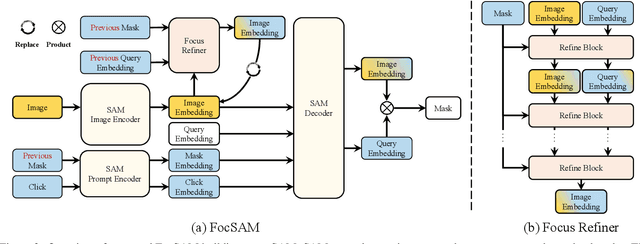

The Segment Anything Model (SAM) marks a notable milestone in segmentation models, highlighted by its robust zero-shot capabilities and ability to handle diverse prompts. SAM follows a pipeline that separates interactive segmentation into image preprocessing through a large encoder and interactive inference via a lightweight decoder, ensuring efficient real-time performance. However, SAM faces stability issues in challenging samples upon this pipeline. These issues arise from two main factors. Firstly, the image preprocessing disables SAM from dynamically using image-level zoom-in strategies to refocus on the target object during interaction. Secondly, the lightweight decoder struggles to sufficiently integrate interactive information with image embeddings. To address these two limitations, we propose FocSAM with a pipeline redesigned on two pivotal aspects. First, we propose Dynamic Window Multi-head Self-Attention (Dwin-MSA) to dynamically refocus SAM's image embeddings on the target object. Dwin-MSA localizes attention computations around the target object, enhancing object-related embeddings with minimal computational overhead. Second, we propose Pixel-wise Dynamic ReLU (P-DyReLU) to enable sufficient integration of interactive information from a few initial clicks that have significant impacts on the overall segmentation results. Experimentally, FocSAM augments SAM's interactive segmentation performance to match the existing state-of-the-art method in segmentation quality, requiring only about 5.6% of this method's inference time on CPUs.
AnomalyXFusion: Multi-modal Anomaly Synthesis with Diffusion
May 02, 2024Anomaly synthesis is one of the effective methods to augment abnormal samples for training. However, current anomaly synthesis methods predominantly rely on texture information as input, which limits the fidelity of synthesized abnormal samples. Because texture information is insufficient to correctly depict the pattern of anomalies, especially for logical anomalies. To surmount this obstacle, we present the AnomalyXFusion framework, designed to harness multi-modality information to enhance the quality of synthesized abnormal samples. The AnomalyXFusion framework comprises two distinct yet synergistic modules: the Multi-modal In-Fusion (MIF) module and the Dynamic Dif-Fusion (DDF) module. The MIF module refines modality alignment by aggregating and integrating various modality features into a unified embedding space, termed X-embedding, which includes image, text, and mask features. Concurrently, the DDF module facilitates controlled generation through an adaptive adjustment of X-embedding conditioned on the diffusion steps. In addition, to reveal the multi-modality representational power of AnomalyXFusion, we propose a new dataset, called MVTec Caption. More precisely, MVTec Caption extends 2.2k accurate image-mask-text annotations for the MVTec AD and LOCO datasets. Comprehensive evaluations demonstrate the effectiveness of AnomalyXFusion, especially regarding the fidelity and diversity for logical anomalies. Project page: http:github.com/hujiecpp/MVTec-Caption
ShadowMaskFormer: Mask Augmented Patch Embeddings for Shadow Removal
Apr 30, 2024Transformer recently emerged as the de facto model for computer vision tasks and has also been successfully applied to shadow removal. However, these existing methods heavily rely on intricate modifications to the attention mechanisms within the transformer blocks while using a generic patch embedding. As a result, it often leads to complex architectural designs requiring additional computation resources. In this work, we aim to explore the efficacy of incorporating shadow information within the early processing stage. Accordingly, we propose a transformer-based framework with a novel patch embedding that is tailored for shadow removal, dubbed ShadowMaskFormer. Specifically, we present a simple and effective mask-augmented patch embedding to integrate shadow information and promote the model's emphasis on acquiring knowledge for shadow regions. Extensive experiments conducted on the ISTD, ISTD+, and SRD benchmark datasets demonstrate the efficacy of our method against state-of-the-art approaches while using fewer model parameters.
Rethinking 3D Dense Caption and Visual Grounding in A Unified Framework through Prompt-based Localization
Apr 17, 20243D Visual Grounding (3DVG) and 3D Dense Captioning (3DDC) are two crucial tasks in various 3D applications, which require both shared and complementary information in localization and visual-language relationships. Therefore, existing approaches adopt the two-stage "detect-then-describe/discriminate" pipeline, which relies heavily on the performance of the detector, resulting in suboptimal performance. Inspired by DETR, we propose a unified framework, 3DGCTR, to jointly solve these two distinct but closely related tasks in an end-to-end fashion. The key idea is to reconsider the prompt-based localization ability of the 3DVG model. In this way, the 3DVG model with a well-designed prompt as input can assist the 3DDC task by extracting localization information from the prompt. In terms of implementation, we integrate a Lightweight Caption Head into the existing 3DVG network with a Caption Text Prompt as a connection, effectively harnessing the existing 3DVG model's inherent localization capacity, thereby boosting 3DDC capability. This integration facilitates simultaneous multi-task training on both tasks, mutually enhancing their performance. Extensive experimental results demonstrate the effectiveness of this approach. Specifically, on the ScanRefer dataset, 3DGCTR surpasses the state-of-the-art 3DDC method by 4.3% in CIDEr@0.5IoU in MLE training and improves upon the SOTA 3DVG method by 3.16% in Acc@0.25IoU.